วันนี้มาเรียนแบบ จ่ายเองนักเลงพอ มาดูว่าที่เค้า Performance Testing มันเป็นยังไงน้า จากทาง SCK Dojo ครับ ที่จดๆมาประมาณนี้ครับ
Table of Contents
Performance Test ทดสอบช่วงไหน ?
เริ่มต้นพี่หนุ่มมาถามก่อนเลยว่า เราควรทำ Performance Test ทดสอบช่วงไหน
| แบบ | ต้น Project | วิเคราะห์ และออกแบบระบบ | coding | หลัง functional test | ท้ายโครงการ | ||
|---|---|---|---|---|---|---|---|
| แบบที่1 | อย่าหาทำ | ||||||
| แบบที่2 | ไม่ควรทำ | ||||||
| แบบที่3 | ไม่ควรทำช่วงท้าย | ||||||
| แบบที่4 | วิเคราะห์ วางแผน ออกแบบ เตรียมการสื่อสาร Perf Test: Test Development | ||||||
| ทดสอบช่วงนี้ Perf Test: Test Exection ที่มันเหลื่อมๆ กัน เพราต้อง Feedback Sync กลับไปให้ Test Development | |||||||
ควรทำแบบที่ 4 เพราะ Key สำคัญของ Performance Test อย่างนึง การเห็นภาพรวมทั้งหมด Architecture ของระบบ แล้วมาคุย Flow การไหลของ Request / Event จากนั้นตกลงว่าเทสจุดไหนบ้าง จุดไหนที่ทีมบอกว่าว่ามันตุๆ จะเกิดปัญหา
Performance Test ทำ เพื่ออะไร
❌ เพื่อให้มีของตรวจรับ - ถูกบางส่วน
✅ เพื่อมาทดสอบสมมติฐาน + Cross ตามข้อกำหนด เช่น เรื่อง Auto Scale และหาจุดอ่อน และเสริมให้มันเอาตัวรอดได้ในช่วงเวลาของระบบ
Performance Test ทดสอบแบบเทียบบัญญัติไตรยางค์ตรงๆไม่ได้นะ ปัจจัยมันเยอะ
เรารู้ได้ยังไงว่าเทสจากอะไร ?
📌 มาจาก Need (พวก TOR / RFP) ส่วนใหญ่มันจะคำกลวงๆ ต้องมาเสริม\
📌 Requirement เน้น Non Function List โดยอาจจะสอบถามคนที่เกี่ยวข้องจริง โดยมีคำถาม Guideline และเก็บข้อมูลในรูปแบบของ
- Non-Funtional Area
- Requirements + ฺBusiness
- Current Value ค่าปัจจุบันที่มีย้อนหลังไป ถ้าไม่มี อาจจะต้องมากำหนด Asssumption หรือ ถ้ามีระบบเดิม ต้องไปหามีธีสกัดออกมา อาจจะจาก log
- Expected Value ณ เวลาใด จะได้จ่ายเงินได้สบายใจ
📌 คำถามที่ควรถาม
- [Capacity] จำนวนที่หน่วยย่อยที่ใช้งาน Agent / Branch / Account ถ้าบางที่เกี่ยวกับที่ตั้ง อาจจะต้องถามต่ออยู่แถวไหน เช่น SEA
- [Capacity] Transaction ที่เกิดขึ้นใน 1 ปี
- [Capacity] ช่วงเวลาที่มีการใช้งานสูงสุด( Peak Time)
- [Capacity] (Growth rate of transactions in XX Years
- [Capacity] Num of Users / Growth of Users / Max Concurrent of Users ในเวลาเดียวกัน
- [Security] ต้องเข้ารหัสอะไรไหม ถ้ามีมันจะช้าลง มันส่งผลกับ Perf
- [Performance] Response Time by Function/Service ของแต่ละ API
- [Performance] Workload Type เช่น Online / Batch เวลาที่รับได้แต่ละงานในมุมของ Biz
- [Availability] Application Service Time เวลาที่ระบบต้องพร้อมใช้งาน จะได้มากำหนดได้ งาน xx ไม่ควรเกิดเวลาไปจากนี้ หรือ ต้องตกลงเพิ่ม
- [Availability] Maintainace Time (Windows Time)
Test จุดที่ Business บอก Critical
(bool, error) ดังนั้นคนที่เกี่ยวกับ Perf Test เป็นพวก Analyst (BA / SA)
จากคำถามตอนนี้แบบว่าได้คนที่เกี่ยวข้องมาเยอะ และเลย
ใน Perf เรามีกิจกรรมอะไรบ้าง แล้วใครต้องเกี่ยวข้อง
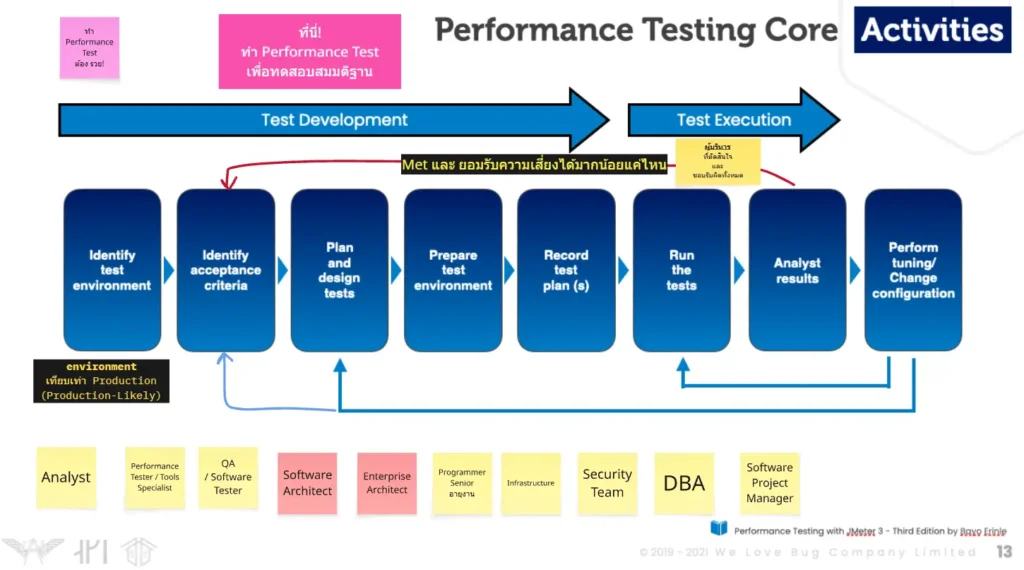
กิจกรรมพวกนี้มันจะล้อไปกับ SDLC จากตอนต้นสรุปไปว่า Perf Test อยู่ช่วงต้น Project > Coding แสดงว่า 8 กิจกรรมของ Performace Testing Core Activities ต้องล้อกันไป
- Identify Test Environment - Env เทียบเท่า Prod (Production Likely)
- Identify Acceptance Criterial - ทำ Questionnaire + เก็บ Req สรุปมา เป็น Expected Value
- Plan and Design Test
- Prepare Test Environment
- Record Plan
- Run Tests
- Analyst Result ต้องมาดูว่ามันตรง (met) ข้อ 2 ได้ไหม อันที่ไม่ผ่าน เรายอมรับความเสี่ยงได้ไหม แต่ต้องยอมรับบางเคส มีปัญหาต้องวนไปปรับ Code / Arch จะไปวนข้อ 3 ใหม่
- Tunning & Change Config
ใครต้องเกี่ยวข้อง
- System Analyst / Solution Architect / Enterprise Architect / Senior Programmer / Infra / Security Team (มาหาข้อตกลง เพราะ ยิ่งเยอะ แล้ว perf ช้าลง) / DBA / QAZ
- ผู้บริหาร (ที่ชอบรับผิด ชอบ+ ตัดสินใจ) - ตัดสินใจ คุยกับแต่ละฝ่าย แล้วถ้าขึ้นไปแล้ว ถ้ามีปัญหาต้อง Deal กับทุกฝ่าย หาคนนี้ของลูกค้าให้เจอนะ
- Software Project Manager จะได้เข้าใจ Nature
- ส่วน Product Owner ขึ้นกับแต่ละทีนะ ถ้าไปลุยจัดการ Req เองก็นับนะ
จากนี้ไปมาแตกย่อยในส่วนของ Performace Testing Core Activities
PT: Identify Test Environment
เกิดขึ้นตอนต้นโครงการ หรือ ก่อนเริ่ม Project
📌 จาก Need (พวก TOR / RFP) ต้องแยกส่วนบอกถึง NFT ในที่นี้จะเป็น performance ออกมา โดยอาจจะเอา Idea จากคำถามข้างต้นมาช่วยกรอง และตอนทำ Requirement ไปขุดสกัดออกมาอีกทีให้ชัดเจน อันนี้ฟังแล้วชอบอันนี้
Ver: 1
- จำนวน Tx ช่วงจันทร์ - ศุกร์ วันละ 50,000 Tx
- จำนวน Tx ช่วงเสาร์ - อาทิตย์ วันละ 90,000 Tx
คาดหวังว่า
Ver: 2 ที่เราทำใหม่ต้องรองรับได้มากกว่าเดิม 4 เท่า
คำว่า 4 เท่าตีความยังไง ?
- Tx ช่วงจันทร์ - ศุกร์ วันละ 50,000 Tx > 200,000 Tx หรือ
- Tx ช่วงจันทร์ - ศุกร์ วันละ 50,000 Tx > 250,000 Tx
📌 จากนั้นต้องตกลง System / Software Archtitecture ให้ได้ก่อน จะได้เห็นว่า
- ระบบที่เราทำงาน อยู่มีส่วนประกอบอะไรบ้าง รูปแบบการทำงานเป็นอย่างไร ?
- ระบบรอบข้างที่เกี่ยวข้อง กับเรา รูปแบบการทำงานเป็นอย่างไร ?
- รูปแบบการทำงานเป็นอย่างไร ? เช่น
- Online / Batch
- Request / Response เป็นอย่างไร มี Protocal อย่างไร
- Sync / Async
- ปริมาณที่เคยรับได้ + ความสัมพันธ์ >> ตรงนี้ Observability (Log / Trace / Metric) จะช่วยได้เยอะ - จากนั้นมาดูได้จุดไหน เป็นจุดอ่อน จุดเสี่ยงได้
📌 พอได้ข้อมูลแล้ว มากำหนด ENV อยากได้แบบ Production - Likely เหมือนที่สุด อาจจะมีการลงทุนด้วย ต้องบวกงบเข้าไปด้วย
📌 ถ้าเราไม่รู้อะไรเลย ข้อมูลเก่าก็ไม่มี
- อาจจะหาระบบงานที่ใกล้เคียงมา Reference แต่ต้องระวังนะ
- ถาม user โดยอาจจะทำ Questionnaire หรือ ไปดูข้อมูลจาก Observability System ถ้ามี
- ถ้ากำหนดมากไป มันจะผลกับ Resource Usage ว่าใช้จริงๆเท่าไหร่ อารมณ์แบบซื้อเครื่องร้อยล้าน แต่ Resource Usage จริงๆใช้ 10% จริงๆ ควรจะใกล้กับ Norm ขององค์กร เช่น กำหนดไว้ว่า 60-70% พวก Cloud / Container / kube เลยมาตอบโจทย์ตรงนี้ เพื่อให้ Resource ใช้คุ้ม
Performance Test ควรใส่ใน Regression Test เพราะได้รู้ว่า Code ไหนเปลี่ยน ทำช้า
ส่วน UI Test อาจจะไม่จำเป็นสำหรับ Regression Test รันเป็นรอบๆ ตามที่ตกลงไว้
📌 อีกคำถามต้องรู้ ผล Performance Test ที่เราทำต้องรองรับได้อีกกี่ปี ใน Condition อะไรบ้าง เช่น ไม่มี Feature เพิ่มหลังจากนี้ มีการทำ Housekeeping xx เป็นต้น
📌 Production-Likely
- ทั้งในส่วนของ APP และ DB ควรทำให้เหมือนกัน Spec เท่ากันก่อน เขียนถึงที่มา วิธีคิดไว้ชัดเจน ว่าทำมาเพื่อทดสอบสมมติฐานอะไร
- ถ้า DB แยก Replicate Read / Write ทำเหมือนกัน
- ถ้าค่อยมาตกลงลด Spec ลงมาตามกำลังทรัพย์
ถ้าหักของออกไป มันจะกระทบอะไรบ้าง และมีความเสี่ยงที่ ยอมรับกันได้ไหม
- แยก Resource ส่วนที่ Load Injector / System Under Test / Obserability + Monitor คนละชุดกัน

PT: Identify Acceptance Criteria
Acceptance Criteria ข้อตกลงในการตรวจรับ และจ่ายเงินอย่างสบายใจ
จากระบบทำงานได้ถูกต้อง มีอีกหลายส่วนมาเสริม เช่น
- Response Time
📌 วัดการตอบสนองจากระบบ โดยต้องดู 2 มุม Data Point ที่วัดได้ / Average ตัดข้อมูลที่เท่าไหร่ 90% / 95% หรือ 99.5% การเลือกว่าตัดที่เท่าไหร่ ดูว่าจำนวนที่จะมีโอกาศได้เงินจาก Tx สำเร็จนั้นๆ เท่าไหร่ + solution ที่ต้องลงทุนเพิ่ม
📌 ตอนสนองจากไหน
- Web UI ควรจะไม่เกิน Second - ที่ได้ยินกัน 1-3 Second
- API ควรจะไม่เกิน Millisecond - Postman จะเอา Default 200ms
📌 กว่าจะตอบมา 1 ทีต้องผ่านอะไรบ้าง ?
Response Time = Latency Time (LT) + Processing Time (PT) ในแต่ละ hop
การจะรู้ว่า Response Time เต็ม มันคิดจากไหนบ้าง เราต้องรู้ Architecture ของระบบ + เส้นทางที่ลูกค้าจะมาถึงระบบเรา เช่น ผ่าน WiFi > Internet > System Under Test

- มุมคนทั่วไป - ตั้งแต่กด Enter สั่งจนเว็บ Render เสร็จ
- มุม Perf Tools - บิตแรกถูกส่งไป และตัดสุดท้ายที่ได้รับ
📌 เครื่องมือ Tools ที่ Test Performance ควรมี Probe ด้วย อย่าง load runner มี probe
probe = เครื่องมือจับที่ละ hop ผ่าน Web - App - DB หรือ External System เป็นต้น ถ้าในยุคนี้จะเป็นพวก Tracing ของ Observability (แอบดีใจ App ที่ไปช่วยล่าสุดมีเน้นเรื่องนี้ไป ตอนแก้ Perf ดู Trace ง่ายมาก)
- Success Rate / Fail Rate
📌 ถ้าเป็น web จะเป็นพวก http code อย่าง 2xx ควรจะ 100% และมีพวก 4xx หรือ 5xx ให้น้อยที่สุด
📌 ถ้ามีมาแสดงว่า มันต้องร่วงสักจุดในระบบ
- Resource Utilization
📌ดูที่ไหนบ้าง > ทุกจุด ทั้ง App / DB และตัว Host ที่มันรันอยู่ด้วย เรียกว่าเป็นการบูรณาการข้อมูลจาก Infra / App / DB เห็นหลายอันพยายามออกข้อมูลในรูปแบบของ Open Telemetry ด้วย เพราะตัว Perf Tools มันเก็บได้ไม่หมด อยากกมากได้แค่ตัว CPU / Memory
📌 ดูอะไรบ้าง มีหลายส่วน ตามนี้เลย
| RESOURE | ค่าที่คุ้ม | ค่าที่ต้อง Alert |
|---|---|---|
| CPU / Memory / Disk / Bandwidth / Queue เป็นต้น | คุ้มกับเงินที่ลงทุนไป เช่น อยากให้ซื่อ Server แล้ว CPU ใน load ปกติใช้งานประมาณ 55-60% | ถ้าเกินต้องส่งคนเข้าไปดู ก่อนระบบดับ เข่น 75% นานเกิน 1 ชั่วโมง เป็นตน |
📌 นอกจากดู Resource อาจจะวัดจาก SLA ความพร้อมใช้งานระบบ เช่น ตามช่วงเวลาทำงาน
📌 อีกประเด็นมี Request Simulate มาเท่าไหร่ ?
PT: Plan and Design Test
📌 เข้าใจกันก่อน ถึงรูปแบบของ Virtual Users (VUs) เป็นอย่างไร และ Workload Model อย่างไร Workload Model มี 3 ส่วน ได้แก่
- Ramp-Up - ช่วงเวลาที่ user เริ่มถล่มเข้ามา กราฟมันจะชันขึ้น
- Steady - ช่วงที่ Request คงที่ แบบคนเข้ามาพยายามจองกล่องสุ่ม
- Ramp-Down - ช่วงที่ Request ลดลง จากทำงานสำเร็จตาม Flow หรือ หลุดออกไปด้วยสาเหตุอื่นๆ

📌 ข้อมูล Workload มาจากไหน
- ข้อมูลในอดีต
- อาจจะเอาจาก Log ของระบบเดิม ทีม Infra มา Visualize ว่ามันมี Wave ของ Workload อย่างไร
- Query จาก Log เดิมของระบบ
- หรือ ถ้าไม่มีต้องสอบถาม และไปเทียบเคียงกับระบบที่คล้ายๆกัน - พอได้ข้อมูลแล้ว เราต้องมาแบ่งในแค่ละช่วงเวลา Workload มาเป็นอย่างไร และจุดไหนควรทดสอบ จุดไหนไม่ควรทดสอบ
📌 จากนั้นมา Simulated Load ตัว Workload โดยดูจาก
- ตาม Step การใช้งานจริงตาม Business Steps / End User Business Flow / Customer Journey
- มี think time behavior (ช่วงเวลา แต่ละ action หยุดคิดของผู้ใช้ หยุดคิด มันยึด resource) เช่น คิดเลือกสิ้นค้าจากตะก้รา หรือ เพิ่มลดวิชา
- ระบบมี caching ไหมถ้ามี ต้องคิดเคสที่ TTL หมดอายุด้วยนะ หรือ ตาย พฤติกรรมเปลี่ยนไปอย่างไร
- geographical distribution ใช้จากที่ไหน browser / device อะไร
📌 รูปแบบของ Workload
- Load Test - ทดสอบตาม Max Design Capacity
- มี Ramp-up / Steady / Ramp-Down อันเดียว ทดสอบ 1 API - Flow Test (Load Test Multi-Steps Ramp-up)
- ทดสอบตาม Flow Business ยิง API 1 ต่อด้วย API 2 3 .. จนครบ Flow Business จะได้ Workload Model ซ้อนกันไปเรื่อยๆ - Endurance Test - เทสความทนทาน ทดสอบ Durability จะช่วยเรื่อง
- เคสแบบ App Run เช้าเร็ว บ่ายช้า เลยต้อง Restart นานๆเข้า เช้าเร็ว สัก 10 โมงเริ่มช้าแล้ว ถ้า java เคส GC มัน Clear ของเดิมไม่ทัน GC ส่งงานใหม่มารอ
- ทดสอบ Response Time ว่าช้าลงไหม / Resource Utilization มันควรจะ Stable ถ้าเปิดเฉยๆ แล้วตัว memory leak ต้องมาดูแล้วว่าหลุดที่ไหน - Stress Tests
- มาหาจุด Break Point ไม่ใช่หาจุดคอขวด และวางแผน + ทำ Code / Microservice ที่เกิดปัญหา
- อยากรู้ว่า เรารองรับได้ไปอีกกี่ปี ตามสัดส่วนการ Growth ตาม Business ปี 1 2 3 …
- ส่วน Load Test ทดสอบตาม Max Design Capacity - Spike Test - ทดสอบว่าระบบรองรับไหม ถ้าอยู่มี Traffic เพิ่มขึ้นมาจาก Load Test แปบๆ อาจจะมี 1 Spike หรือ หลาย Spike ก็ได้ ต้องมาดูว่าช่วย Spike มีอะไรที่สะดุดไหม ตัวอย่าง วันหวยออก / ระบบลงทะเบียน มันจะ Spike ช่วงแรก พอคนทำงานเสร็จ Traffic ลดลงไปเป็นปกติ
- Scalability Test เอาไว้ดูว่าถ้าถึงเงื่อนไขที่ระบบต้อง Scale แล้ว ระบบ Scale จริงไหม นึกถึงภาพตัวเองเปิด Cloud Shell แล้วยิง App Service / EKS ดูว่ามันสร้าง Instance ขึ้นมาตามไหม
- Volume Test เอา Data Dump ลง Database แล้วดูการตอบสนองจากส่วนอื่นๆของระบบ
💡ส่วน Chaos Test มันจะคนละมุมกับ Performance Test ตัว Chaos Test มันเป็นสิ่งที่เราคุมไม่ได้นะ
PT: Prepare Test Environment (🏗️ Arrange 🏗️) +
PT: Record Plan
📌 เตรียม Production-Likely Resource
- ส่วนที่ Load Injector / System Under Test / Obserability + Monitor คนละชุดกัน
- เริ่มต้นอาจจะทำมือ
- แต่ถ้าต้องสร้างลบบ่อยๆ พบ Script เข้ามาช่วย
- Docker / Docker Compose
- Scale มาหน่อย K8S หรือ Cloud ของแต่ละค่าย - ตกลงกับ Network Infra ให้เรียบร้อย ว่าจะยิงน้า จะได้ไม่โดน Firewall Filter ทิ้ง หรือ ถ้าแยก Env ไว้ อาจจะของเค้าช่วย Duplicate Traffic มาใส่ได้ได้
📌 เตรียม Test Data ตามปริมาณข้อมูล
- ใช้ Tools Generate Data ใน Class จะเป็นตัว https://fakerjs.dev/
- ให้ Dev API ช่วย Dump ที่ผมเคยทำนะ
📌 เตรียม External Service
- อาจจะทำ Stub / Mock API มาใช้งาน ถ้าไม่มีให้ลอง
📌 เตรียม Performance Testing Tools
- เลือกใช้ Tools อะไรเอาตัวนั้นเลย เพราะแต่ละตัวมีวิธีวัด ไม่เหมือนกัน จะเอาผล Tools A มาชนกับ B ไม่ได้
- Tools มีหลายตัว
- Grafrana K6 (OSS / Cloud-Commercial) เขียน JS + CLI
- JMeter (OSS)
- wrk (OSS)
- LoadRunner (Commercial)
- vegeta (OSS)
- bombardier (OSS)
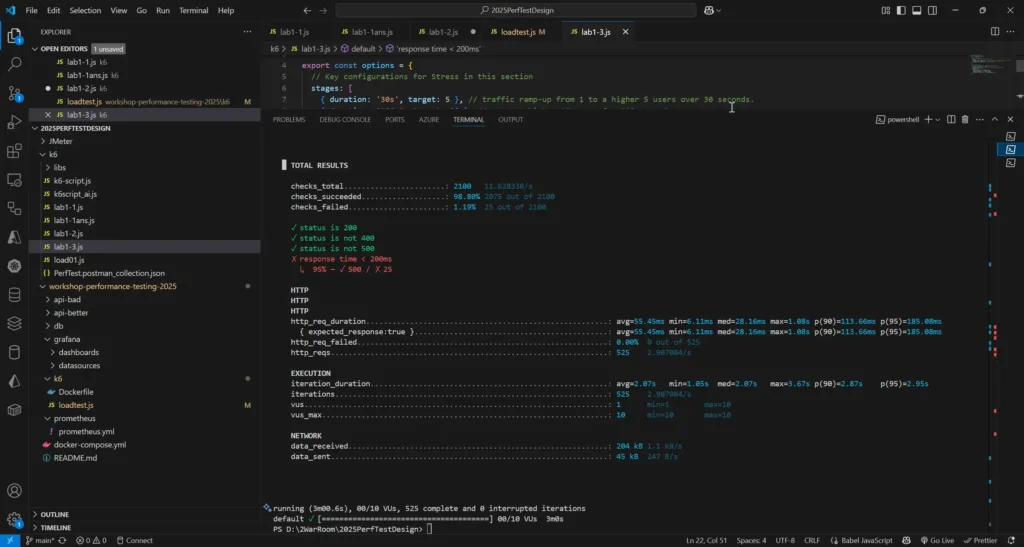
📌 เขียน Performance Testing Script ตามที่ Design ไว้ สำหรับใน Class พี่ปุ๋ย พี่บอม ลองเน้น 2 ตัว Grafrana K6 / JMeter
- Grafrana K6 - เป็น Script เขียนด้วย JS นอกจากนี้ตัวแปลงจาก postman collection postman-to-k6 หรือ AI มัน Gen ออกมาพออ่านได้ ลองเขียน script ตามนี้
import http from 'k6/http';
import { sleep } from 'k6';
export const options = {
// Key configurations for Stress in this section
// แบบเดิม
// stages: [
// { duration: '30s', target: 10 }, // traffic ramp-up from 1 to a higher 10 users over 5 seconds.
// { duration: '120s', target: 10 }, // stay at higher 10 users for 30 seconds
// { duration: '30s', target: 0 }, // ramp-down to 0 users
// ],
tags:{
type: "load-test",
name: 'product-get-test',
testid: 'lab1-1',
},
// แบบใหม่ เอามาแทน stages
//https://grafana.com/docs/k6/latest/using-k6/scenarios/
scenarios: {
get_product_information: {
//https://grafana.com/docs/k6/latest/using-k6/scenarios/executors/constant-vus/
//https://grafana.com/docs/k6/latest/using-k6/scenarios/executors/ramping-vus/
executor: 'constant-vus', //constant-vus ขึ้นเลย ramping-vus ค่อยๆ ขึ้น
vus: 10, // 10 virtual users
duration: '180s', // run for 180 seconds
gracefulStop: '5s', // allow 5 seconds for graceful shutdown
},
},
};
export default () => {
const urlRes = http.get('https://quickpizza.grafana.com/');
// Thnik time between request ตอนลองจริงต้องมีหลาย Scenario
sleep(Math.random() * 2 + 1);
//check the response status
check(urlRes, {
'status is 200': (r) => r.status === 200,
'status is not 400': (r) => r.status !== 400,
'status is not 500': (r) => r.status !== 500,
'response time < 200ms': (r) => r.timings.duration < 200,
});
};
มี Version GUI ด้วยนะ https://github.com/grafana/k6-studio
# ถ้ารัน Test ใช้ CLI ตามนี้ k6 run .\load01.js # ต้องการ web dashboard # - เพิ่ม env K6_WEB_DASHBOARD # - report html เพิ่ม K6_WEB_DASHBOARD_EXPORT # Linux Mac K6_WEB_DASHBOARD=true K6_WEB_DASHBOARD_EXPORT=html-report.html k6 run load01.js # Windows(cmd) set K6_WEB_DASHBOARD=true set K6_WEB_DASHBOARD_EXPORT=html-report.html k6 run load01.js # Windows(powershell) $env:K6_WEB_DASHBOARD = "true" $env:K6_WEB_DASHBOARD_EXPORT="html-report.html" k6 run .\load01.js
- JMeter ตอนแรก พวกได้ Workload Model ให้ AI มัน Gen ให้ ไม่รู้เรื่องเลย 5555 พอมากด UI เข้าใจและ
- wrk ใช้สำหรับลองง่ายๆ ก่อนดู Cap เบื้องต้น ถ้าทำมากกว่านั้นภาษา lua เขียน
นอกจากนี้ ถ้าใครใช้ Postman มันมีตัว Perf Test จะ แต่อาจจะติด Limit Concurrent การยิง ต้องเสียเงินเพิ่ม กลับกัน K6 เหมือนออกตัว Studio มาด้วย อาจจะเข้ามาทำแบบ Post
ตอนแรกเขียน 2 ทำไมงอก 555
📌 Collect Result ยังไง เครื่องตัวเอง หรือ หลายเครื่องยิงเอง ตรงนี้พี่ปุ๋ย พี่บอม มีพา Demo
- เอา Local Report จาก K6 / JMeter
- รวมถึงเอาผลมาทำเป็น Centralize จะได้เก็บที่เดียว และดูภาพรวมได้ทั้งหมด ใช้ตัว LGTM Stack อย่างตัว
- Prometheous/Mimir - เก็บ Time Series ที่ได้จากการ Test แต่ตัว JMeter ไปทาง InfluxDB จะดีกว่า เพราะ JMeter ทดของไว้ในนั้นตอนรัน
- Grafrana มาแสดงผล - ตอนนี้มี Drill Down ให้ดูง่าย Ver12 //ลอง Update ใน HomeLab แล้วของดี
ถ้าอยากรู้ว่าใช้ Ver อะไร [grafrana_endpoint]/api/health ตรวจดูครับ
- Sample ของพี่ปุ้ย https://github.com/up1/workshop-performance-testing-2025
สุดท้ายอย่าลืมเก็บของลงใน Source Control ด้วย เป็นไปได้ควรอยู่ที่เดียวกับ Dev
PT: Run Tests (🤺ACT / ASSERT🤺)
- ถ้าพร้อมแล้วก็ลุยทดสอบตาม Workload Model ที่เลือกไว้ เช่น เจอ load เยอะ ช่วย 11pm เมื่อวาน - ตี 2 วันถัดไป และอีกช่วง 9 โมงถึงบ่าย 2 รันทิ้งไว้ตามเวลานั้นๆเลยครับ
- การ Run Test ให้ใช้แบบ CLI ถ้ากดจาก GUI ตัว UI อาจจะเดี้ยงก่อน
- Load Injector แยก server หรือ ใช้ตัวเล็กๆ หลายตัว มาแบ่งๆ แต่คุยกับ network จะได้ไม่โดย Filter ออกไป และก็การสร้าง Virtual User มันใช้ Mem Tools มันใช้ Mem ถ้าเครื่องยิงไม่แรงพอ คนยิงตายเองก่อน
Tools บางตัว อย่าง JMeter รองรับ Mode ยานแม่นะ สั่งแล้วกระจาย slave ให้ยิงให้
- พวก load balance / api gw เป็นไปได้ ควรตัดออกไปก่อน จะได้รู้ว่า App มันรับได้จริงๆ เท่าไหร่ อาจจะโดนกันไป
PT: Analyst Result
เอาผลลัพธ์จาก Test Report มาดู เข้า Request Sucess / Fail หรือ รวมถึงดูจากข้อมูลที่ Percentile ที่เท่าไหร่
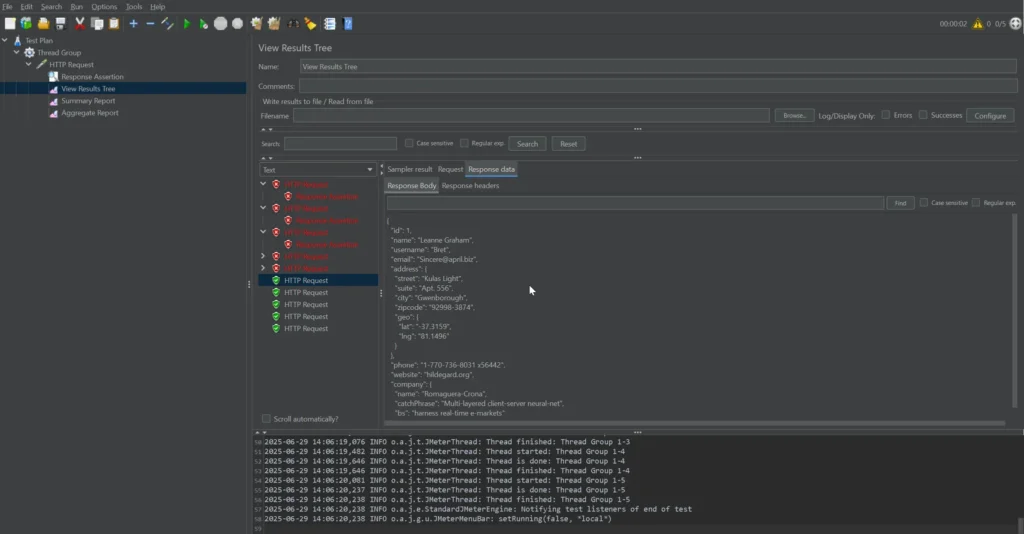
นอกจากนี้แล้วในช่วงเวลาเดียวกัน เราสามารถไปดูจากส่วน Observability System ได้ ว่าช่วยเวลาที่มีปัญหาจาก Perf Test Trace เวลาเดียวกัน Trace มันไปตายในจุดไหน เช่น App ตาย ส่วน DB เหงาไม่มีใครมา Query เป็นต้น

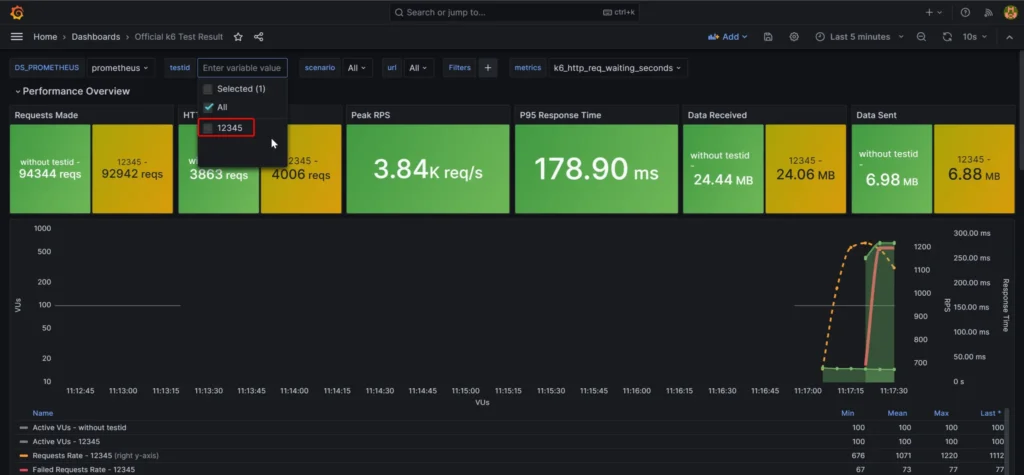
PT: Tunning & Change Config
อันนี้ใน Class ไม่ได้สอน ผมเข้าใจว่า ถ้า Analyst Result ได้ แล้วไปดู Log Trace ว่าช้าตรงไหนเจอ เราไปแก้ Code หรือ Config ได้ ครับ
จากนั้นกลับไปตรวจซ้ำอีกทีครับ
สำหรับ Class นี้จะเน้นสอนการคิดนะ เข้าใจส่วน Tools มาเสริมการใช้งานเบื้องต้นครับ เข้าใจมากขึ้นเยอะ ว่าที่เค้า Report มาให้ปรับๆ มันเป็นยังไง ขอบคุณทีมงานมากๆครับ
Reference
- Performance Testing: Analysis, Design, Develop and Test in Action Workshop รุ่นที่ 1 //ได้ข่าวว่ามีเปิดรุ่น 2 BKK / 3 CMI นะ
- somkiat.cc : บันทึกการแบ่งปันเรื่อง Performance Testing with Grafana K6
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.