สำหรับสัปดาห์นี้จะเรียนให้หัวข้อ Cloud Native Architecture ว่าจะทำ App ให้เป็น Cloud Native ต้องเข้าใจเรื่องอะไรบ้าง
Table of Contents
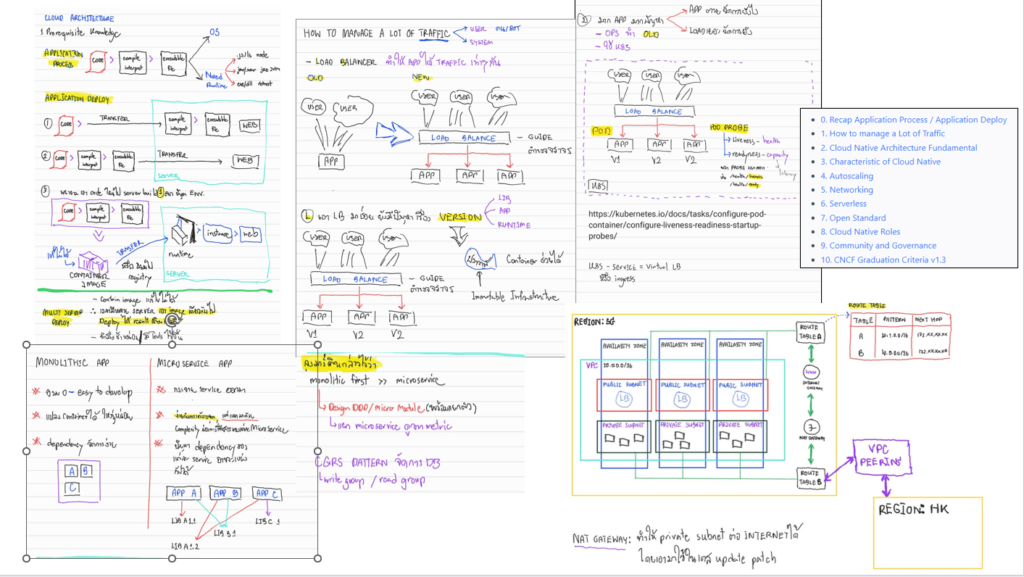
0. Recap Application Process / Application Deploy
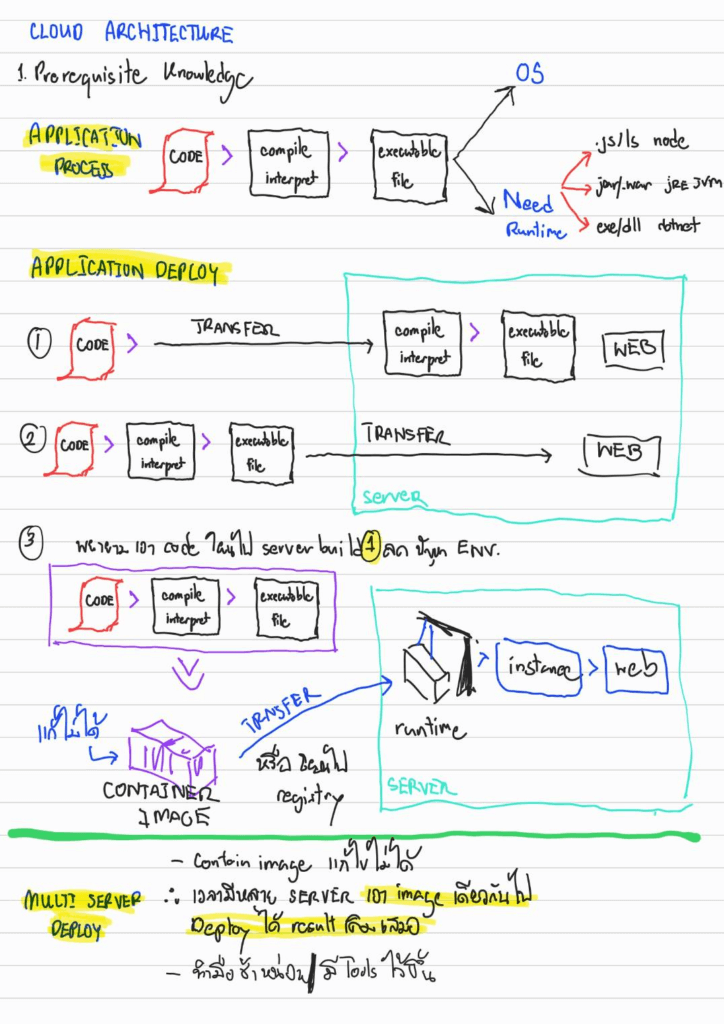
- Application Process จาก Code > Build > จะได้ตัว
- OS
- Need Runtime พวก asp.net (dotnet) / spring-boot (java-jdk/jre) / ts, js (Node.JS) - Application Deploy จากเดิมทำมือ > pack package แต่มีปัญหา Environment > ยุค Container ที่ลดปัญหา Environment ลงไป
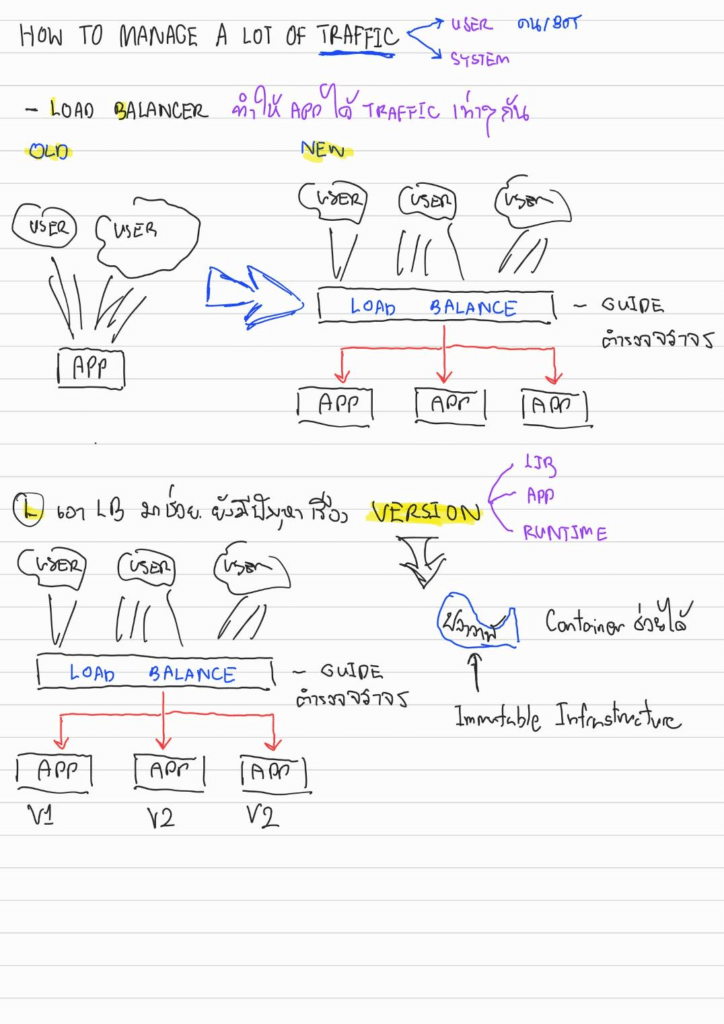
1. How to manage a Lot of Traffic
Traffic มาจากหลายส่วนไม่ว่าจะเป็น user หรือ ระบบเอง เราคงไม่สามารถสร้าง Server ขนาดใหญ่มาจัดการได้หมด เลยต้องมี Load Balancer มากระจาย Traffic ให้กับ App แค่ละตัว
แต่ทว่าพอเพิ่ม App หลายๆตัวเข้ามา ใช่ว่าปัญหาจะจบ มันมีเรื่อง
- การ Deploy / Monitor
- Load เยอะใน App ตังให้ตัวหนึ้งจะรู้ได้ไง
เมื่อก่อนใช้ Operation มาดู แต่ตอนนี้ถ้าเป็นยุค Container จะใช้ตัว K8S ต้องมาดูในส่วนของ Liveness Probe / Readiness Probe - นอกจากนั้นยังต้องมาหงุดหงิดจัดการ Version ของ App / Library (Dependency) / Runtime ที่แต่ละ Environment ใช้
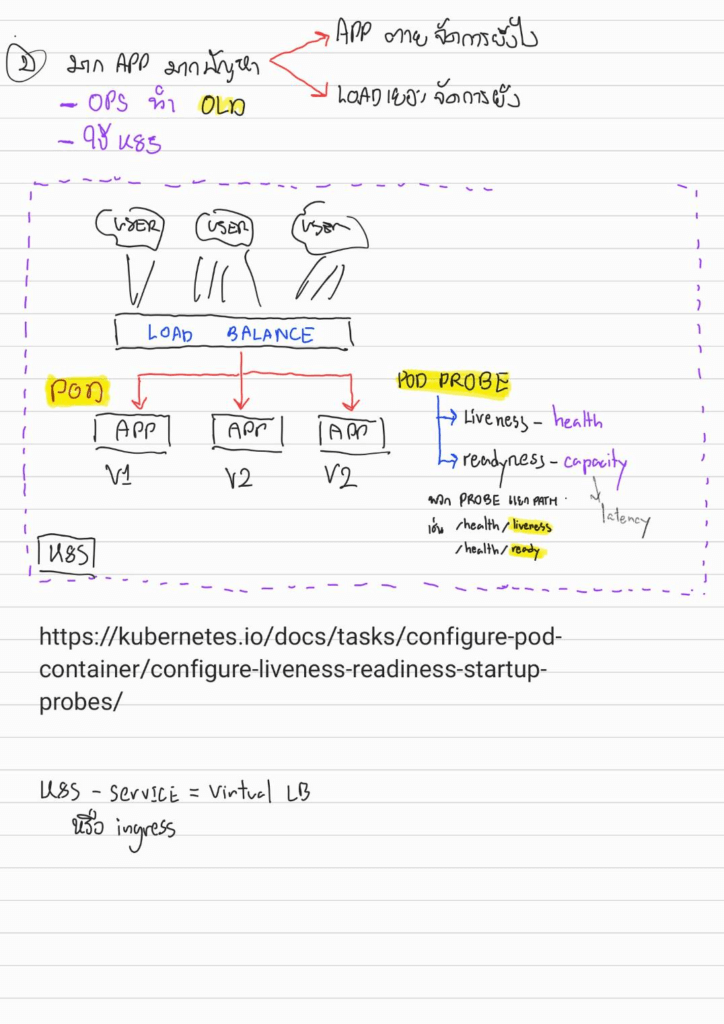
ปกติขา dotnet ที่ดูทำ API สำหรับ HealthCheck แต่ลองไปค้นๆมา มีคนทำ Lib ไว้แล้วด้วย
- petabridge/akkadotnet-healthcheck: Healthchecks for Akka.NET Applications :hospital: (github.com)
- Health checks with ASP.NET Core and Kubernetes - David Guida
2. Cloud Native Architecture Fundamental
- Cloud Native - App ที่ Optimize มาสำหรับ Cloud ในด้าน Cost (Scale) / Reliability / Time to Market
- How To - มันไม่ได้ปรับที่ Tech อย่างเดียว สร้าง
-Team Culture - ดูจากเล่ม Team Topology
-Tech Stack ดูจาก cncf
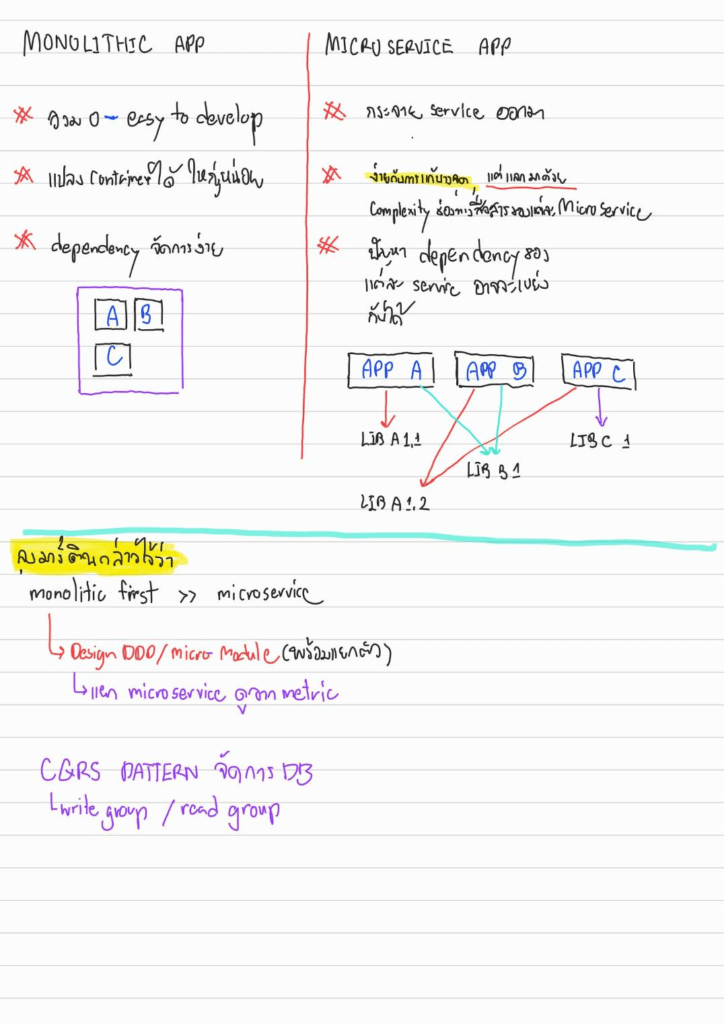
-Design: Design Pattern / Architecture Pattern / Domain Driven Design - Monolithic VS Microservice
- Monolithic จัดการง่าย รวม 0
- Microservice กระจาย Code จัดการง่ายขึ้น แต่มี Complexity ในการสื่อสารเพิ่มขึ้น และมี app version / library version / Runtime ที่ไม่ตรงกัน - ถ้าเริ่มแรกต้องต้นจาก Monolithic ก่อน แต่แยก Domain ให้ชัดเจน และทำ Micro-Module พร้อมแยกตัว (ฝั่ง dotnet ผมแยก project/dll) Ref. Martin Fowler
3. Characteristics of Cloud Native
- High Level of Automation ต้องเริ่มวางแผน Infra โดยเริ่มจาก
1. Network Infra
2. Architecture Infra - วาง Workload APP / DB / Load balance และอื่นๆ
3. Application Infra - เจาะลงไปใน App จะเอา App เดิมขึ้นมาเลย / ทำเป็น Monolithic / Microservice เลย)
4. Deployment Process (CI/CD)
Note: ข้อ 1/2 นึกถึงพวก Landing Zone ของพวก Cloud - Self healing ทำให้ App มันยืดหยุ่น ตายแล้วฟื้นมาได้ไว (Resilience) โดยมี Pattern สำคัญ
- Circuit Breaker - ถ้าอันไหนพัง ตัดทิ้ง แล้วให้ระบบทำงานต่อไปได้
- Feature Toggle (Open-Close แบบ Load Traffic จาก V1 ไป V2)
- Auto Restart
- Ready - Scalable
- Cost-Efficient หรือ FinOps เริ่มจาก
- Inform ทำให้เห็นก่อนว่าเกิดอะไรขึ้น มี Observability
- Optimize (ลด / ปิด)
- Operation (ทำให้มัน Automate) - Easy to maintain - 12 Factor / scalable architecture/automation process / pattern & test.
- Secure by default - zero trust.
4. Autoscaling
เงื่อนไขว่าจะอะไรมา Scale ตาม Load หรือ Reqest ที่เข้ามาหนักหน่วง (Intensive)
- จับจาก Resource เช่น CPU / Memory / GPU / Connection (Pool / Response ที่ตอบช้าลง)
- ช่วงเวลา Custom เช่น Business ช่วงต้องปิดงบไตรมาส
ภาพ App Service Plan ลอยมาเลย สำหรับรูปแบบการ scale มี 2 แบบ
- Vertical Scaling (Scale UP/ Down) เป็นการขยาย/ลดขนาดของ Instance ให้มี Resource มากขึ้น เช่น CPU / RAM
- Prod จัดการได้ง่าย เพราะตัว App เดิมๆ ที่อาจจะเป็น Stateful (เช่น พวก DB) ไม่ต้องมาปรับตัวอะไรมาก
- Con single point of failure และมื่อถึงจุดที่ต้องการ Spec สูงๆ จะเริ่มแพงขึ้น เพราะหาเครื่องในท้องตลาดยาก - Horizontal Scaling (Scale Out / In) เป็นการเพิ่ม / ลดจำนวน Instance
- Prod เพิ่ม Availability + fault-tolerance
- Con Complexity เพิ่มต้องมาจัดการ Instance / Communication และเรียนรู้ Tools เข้ามาช่วย อย่าง K8S
รวมถึงต้องคิดตั้งแต่ Design App ควรต้องเป็น Stateless ไม่ถืออะไร เดวจากลาไม่ต้องมาตามล่า รวมถึง Cost ที่เพิ่มขึ้น
5. Networking
หัวข้อนี้คำศัพท์เยอะ - หลายคนที่ไม่เคยใช้งาน Cloud อาจจะงงได้
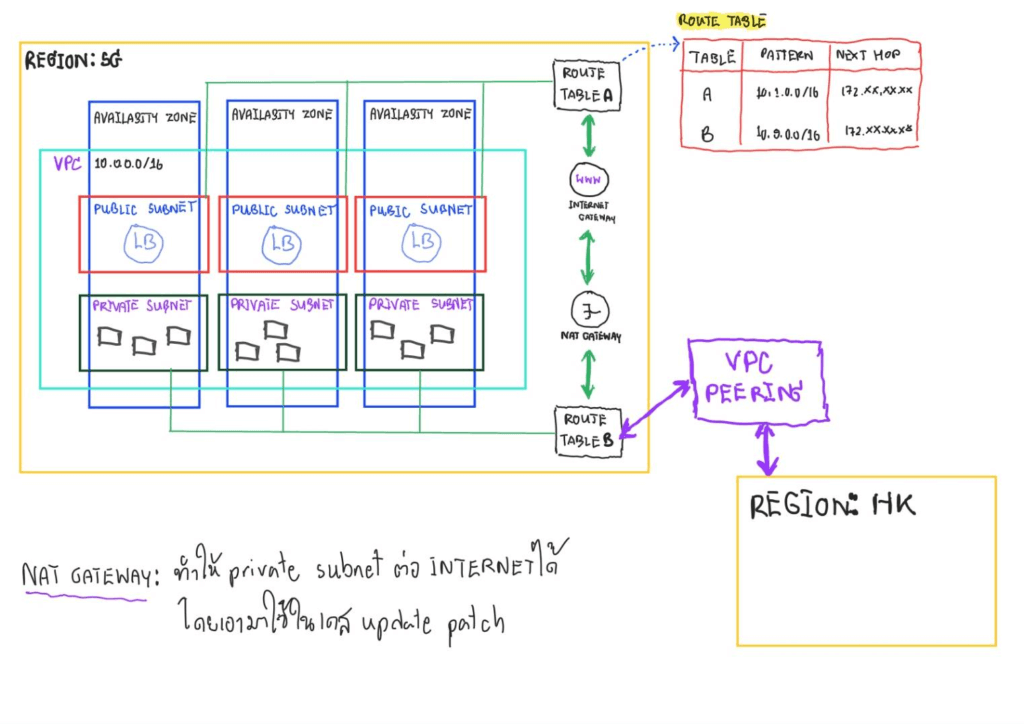
- Cloud Service Provider - ผู้ให้บริการ Cloud ไม่ว่าจะในประเทศ เช่น PROEN / NIPA หรือ ต่างประเทศ ตัวอย่าง Azure / AWS / GCP / Alibaba / Huawei เป็นต้น
- Region - ภูมิภาคแบ่งตามภูมิศาสตร์ (Geo-Location) เพื่อตั้ง Cloud โดย Region จะแบ่งย่อยเป็น Zone ตั้งแต่ 3 ที่ขึ้นไป
- Zone (Availability Zone) ศูนย์ข้อมูลที่กระจายกันอยู่ใน Region เพื่อรองรับเรื่องของ High Availability (HA)
- Local Zone - ช่วยการเก็บข้อมูลไว้ในประเทศ (Data localization) / งานที่ต้องการ latency น้อยๆ อย่าง เช่น DNS, Proxy หรือ พวก CDN อาจจะแบ่งมาทำ Private Cloud ก็ได้นะ ถ้าเงินหนาพอ
- Zone (Availability Zone) ศูนย์ข้อมูลที่กระจายกันอยู่ใน Region เพื่อรองรับเรื่องของ High Availability (HA)
- Virtual Private Cloud - Switch ขนาดใหญ่ใน Region เหมือน Network วงใหญ่ของเรา ปกติ 1 Region จะมี่ 1 VPC แต่อาจจะแบ่งย่อยได้ ถ้าต้องการทำ DC/DR เป็นต้น อ๋อ VPC บางค่ายอาจจะเรียกว่า VNET
- Subnet พื้นที่ย่อยแบ่งจาก VPC ตามแต่ Availability Zone สำหรับงานต่างๆ โดยแยกกลุ่ม
- Public Subnet - งานที่เข้าต้องให้เข้าจาก Internet เช่น Load Balance / Portal และเขียนกับ Internet Gateway ปกติจะ Allocate IP น้อยๆ
- Private Subnet - งานที่ไม่ต้องการ Access จากข้างนอก เช่น Database / Business Tier ถ้าต้องการ Internet อย่าง Update Patch จะอยู่ผ่าน NAT Gateway - CIDR (Classless Inter-Domain Routing) - วิธีการจัดสรรพื้นที่ IP Address ของ VPC / Subnet
- Subnet พื้นที่ย่อยแบ่งจาก VPC ตามแต่ Availability Zone สำหรับงานต่างๆ โดยแยกกลุ่ม
- Route Table - ตารางบอกที่อยู่ ว่า Subnet A > B หรือต้องไปออก Internet ผ่าน Internet Gateway / NAT Gateway ต้องไปทางไหน
- VPC Peering การเอา VPC 2 จุด มาเชื่อมกัน เช่น คนละ Region โดยที่ IP Range ห้าม Overlap กัน
สำหรับความสัมพันธ์ทั้งหมด จะอยู่ตามภาพนี้
6. Serverless
Serverless อีกชื่อนึง Function as a Service เป็นอีกแนวคิดนึง Deploy Code เล็กๆ เอามาแปะ / ทำ .zip / ทำ Container ให้ทำงานได้ โดยที่เราไม่ต้องสนใจงานด้าน Infrastructure เลย ให้ Cloud จัดการให้ ลดงาน Developer โดยงานที่ใช้จะเป็น
- เหมาะกับงานที่ลองอะไรเล็กๆ / Test ก่อน ขยับขยาย เพราะมันคิด Cost ตาม Event / Request
- หรือ จะเป็น Extension เสริม เช่น สั่งปิด / เปิด VM หรือ จะลอง Test Check Health App ถ้าไม่ Response ให้เปิด Stack อีก Region ขึ้นมาทำงาน
On-Premises มีตัวให้ใช้งานนะ อย่าง K8S มีตัว Knative ให้ทำ Serverless
7. Open Standard
Open Standard เป็นแนวทางที่ช่วยให้ตัว Open-Source Project มีแนวทางพัฒนาไปในทางเดียวกัน แลัวสามารถเอามาใช้งานร่วมกันได้ รวมถึงเพื่อป้องกันปัญหา Vendor Lock และลดเวลาในการแก้ปัญหาจุกจิ อย่าง เช่น พวก OS
อย่างตัว Linux Foundation ในส่วน Container แยกเป็น How to build and run containers อาที เช่น
- Open Container Initiative
- Container Network Interface
- Container Runtime Interface (CRI)
- Container Storage Interface (CSI)
- Service Mash Interface | A standard interface for service meshes on Kubernetes (smi-spec.io)
พอมันมี Open Standard มันเลยเป็นที่มาว่า ทำไมเราถึงใช้ docker image บน podman / K8S ได้ หรือว่าจะโยก pod จาก podman ขึ้น K8S ได้เลย
CloudEvents - เป็นอีกที่เข้ามาตามแนวคิดของ Open Standard ที่ดูแลโดยทาง CNCF โดยสิ่งที่ CloudEvents เข้ามาช่วยที่ให้การสื่อสารระหว่าง Platform ต่างๆ อย่าง Cloud Service Provider / On-Premise หรือ Service อื่นๆ คุยกันได้สะดวก ตอนทำ Serverless ถ้าต้องส่ง Event ข้ามไป/มา สะดวกขึ้น //ดู AZ-104 มา CloudEvents v1.0 schema with Azure Event Grid เหมือน Connect-the-dots
OpenTelemetry - อีกอันที่ดูแล โดยทาง CNCF
8. Cloud Native Roles
- Recap Week#1 ขอ Reference ไป Blog Week แรกจ้า
- มีหลากหลายอาชีพ สรุปสั้นๆ ตามนี้
- Cloud Architect - DevOps Engineer - Security Engineer - DevSecOps Engineer - Data Engineer - Full-Stack Developer - Site Reliability Engineer (SRE) - Observability Engineer
9. Community and Governance
- ถ้าเรามี Open-Source Project อะไร สามารถเอาไปเสนอให้ทาง Foundation ใหญ่ๆอย่าง Linux Foundation / CNCF Foundation เพื่อมาเป็นที่ปรึกษา / ขอ Funding ได้่
- สำหรับทาง CNCF เองจะมีทีมงาน Technical Oversight Committee (TOC) ที่ตั้งมาจากองค์กรใหญ่ ที่ให้ Funding กับ CNCF เอง เข้ามาช่วยแนะนำ เป็นที่ปรึกษาตามแนวทาง “minimal viable governance" ที่เข้ามาช่วยแนะนำให้เรื่อง technical vision / common practices ที่ควรทำ / approving new projects / accepting feedback จาก End-User โดยที่ TOC มาจากองค์กรใหญ่ๆ
- TOC มีหลายคณะแยกตามสาขาที่เรียกว่า TAG ตอนนี้มีส่วน TAG-Security / TAG-Storage / TAG-App-Delivery / TAG-Network / TAG-Runtime / TAG Contributor Strategy / TAG Observability และ TAG Environmental Sustainability
10. CNCF Graduation Criteria v1.3
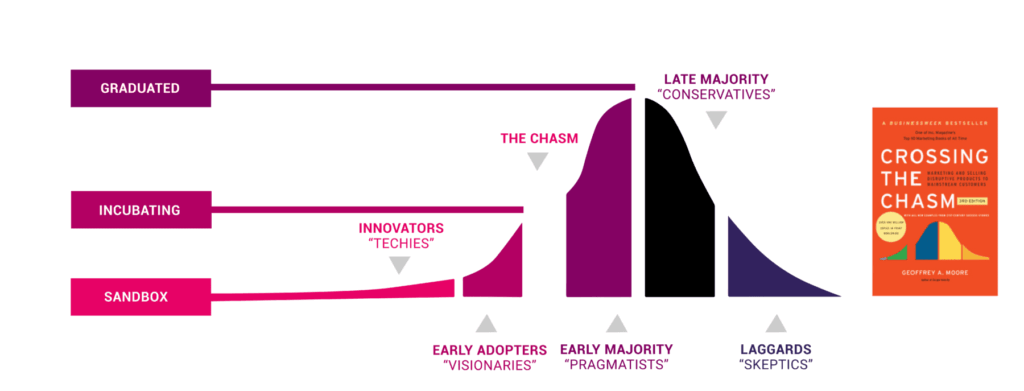
การที่เราจะเลือกเอา Tools / Lib มาใช้ เราสามารถใช้ Project Maturity เข้ามาช่วยในการตัดสินใจได้ โดย Project Maturity เป็นเกณฑ์ที่วัดการเติบโต วุฒิภาวะของตัว Project โดยเริ่มจาก
- Sandbox Stage - TOC ช่วยดูว่า Project ที่เสนอมา ใช้งานได้ดีไหม และมี Community ระดับนึง
- Incubating Stage - การขยับจาก Sandbox ขึ้นมา Incubating มีคนใช้งานจริงบน Production 3 เจ้า และต้องมีการกำหนด Process ชัดเจน
- Commit และ Contribute Project
- แนวทางการจัดการด้าน Security เช่น การ Patch ช่องโหว่ที่เกิด
- Release Roadmap เป็นต้น - Graduation Stage
- มี 2 องค์กรใหญ่ เข้ามาร่วม Contribute (ถ้าเข้ามาแสดงว่ามันไม่ล่มและ)
- ทำ Guideline จนได้ Best Practices Badge
- มี 3rd Party เข้ามาตรวจสอบด้าน Security
Ref: Project Metrics | Cloud Native Computing Foundation (cncf.io)
สำหรับวัน On-Site มีจับกลุ่มแบบสุ่มมองลองเอาที่เรียนมา มา Design ตามโจทย์ที่ได้จับสลากมา
- มันจะได้หลากหลาย Domain และหลายมุมมอง ถ้ามองจากมุมของผมที่จับ Product เดิมๆมาจากภาพ Architecture ไม่ค่อยได้ขยับเท่าไหร่
- อย่างกลุ่มผมวันนั้นได้การทำ Crypto Exchange เปิดโลกเลย และนอกจากการ Technical Design แล้ว Business สำคัญมากนะ ถ้าตีไม่แตก แล้ววนในอ่าง อาจจะพลาดโอกาสในการสร้างรายได้ แม้ว่า Architecture มันจะ Design ให้รับ Scale Load ได้เยอะแค่ไหน ถ้าคนไม่เข้ามาใช้ก็จบ...
มี keyword อื่นๆที่จำได้ เช่น
- Transactional outbox (microservices.io) น่าจะใช้แหละที่ไม่ต้องรอให้มัน insert ให้จบส่งเข้า queue หรือ message buffer แล้วให้มันจัดการต่อ //สำหรับงานที่ไม่ได้ Required Transaction
- microservice ถ้าแยกย่อยเยอะๆ ต้องระวังเรื่อง delay chain (บัญญติเองนะ) ที่มันช้าจากการมา Call Service ไป insert และส่งต่อ ที่ละ DB แล้วสุดท้ายไปทำ Business Delay แทนอันนี้อาจจะต้องเอา event-driven หรือตัวใหม่ SAGA มาช่วย
- CQRS ผมชอบจำสลับ CORS 555 - แยก Write / Read ออกจากนั้น ผมที่คุ้นกับ RDBMS อารมณ์แบบว่าให้ไป Read on Standby หรือ Replicate DB
- 4C Cloud Native Security จากเล็กไปใหญ่
- Code
- Container
- Cluster
- Cloud - Site Reliability Engineer (SRE) ทำให้มันไม่ล่ม โดยมี Keyword ที่ต้องรู้สามคำ
- Service Level Objectives (SLO) - เป้าหมายของ Service ที่ต้องการ (a target level for the reliability of your service) เช่น
>> ป้ายหน้า Site ก่อนสร้างบอกว่าต้องปลอดภัย 99.95%
>> ถ้าเอา IT มาหน่อย Server ต้องทำได้ได้ 99.98% / Service ต้อง latency <= 100ms
- Service Level Indicators (SLI) - metric (quantitative measure of some aspect) เอามาวัด SLO
>> จากอันตะกี้ ก่อสร้างจำนวนวันที่ไม่เกิดอุบัติเหตุ มาวัดจำนวนวันที่ไม่เกิดเหตุ
>> หรือ Service ต้อง latency <= 100ms จะได้ SLI มาเป็น how long a request actually needs to be answered
- Service Level Agreements (SLA) - สัญญาว่าจะทำตาม SLO ปกติเอาไว้คุยกับลูกค้า
- error budget = มูลค่าที่ App เสียไปเมื่อมีปัญหาที่ยอมรับได้ แต่ต้องไม่เกินพวก SLA - 12 Factor for Cloud Native แบ่ง 3 กลุ่ม 12 ข้อ
- Build System
>> Codebase
>> Dependency
>> Config
>> Backing services resource ที่ App ใช้ เช่น DB / Queue
>> Build / Release / Run
- Scalable System
>> Processes - เน้นให้ App ทำเป็น Stateless
>> Port binding
>> Concurrency - Scale แตก Process
>> Disposability - Graceful Shutdown
- Maintainable System
>> Dev/prod parity - ทำให้ Environment ใกล้เคียงกัน Container มาช่วยส่วนนี้
>> Logs - Async - Stream
>> Admin Processes
อ๋อวันเรียนคุณโจโจ้ มีเอาหนังสือมาป้ายยาด้วย Cloud Native Transformation น่าสนใจ เดวรอ Humble มาจัด Set ฮ่าๆ ฺ



Reference
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.