
ที่เรียกว่าวาร์ป เพราะ วันนี้เป็นวันที่จัด Tech Meetup ชนกัน 5 งานครับ ผมเองออกมาจากงาน .NET Conf Thailand 2025 มาฟังงานนี้ต่อครับ เหตุผลสั้นๆ อยากมา Cleverse เป็น Host ที่จัดงานหลายครั้งแล้ว ฮ่าๆ ที่ฟังมา เหมือนเป็น บ ที่ปั๊น Startup หลายๆ แบบ Mar-Tech หา user engage / Retail Tech / logistic tech (PanTruck) key ลดการตีรถเปล่า / เว็บรายงานผลการเลือกตั้ง และ AI Tech - aerogram.ai ให้ AI มันง่ายสำหรับ End User
สำหรับ Plan อยากมาฟังหัวข้อส่วนแรก Coding ครับ อันหลังๆทำใจๆไว้แล้วธาตุไฟเข้าแทรกได้แน่ๆครับ สำหรับที่จดๆมามีหัวข้อตามนี้ครับผม
Table of Contents
AI Agents with Microsoft Foundry
Speaker Teerasej Jiraphatchandej
📌 จากเดิมมี WinApp / WebApp / MobileApp โดยทุกอย่างถูกกำหนด Flow ไว้แล้ว จาก Developer
📌 พอมี AI เข้ามา Use Case แรก App Chat (Copilot / ChatGPT) หรือ Filter ต่างๆ ของ IG / TikTok
📌 ตอนนี้มีแนวคิดของ Agentic AI มีการ Integrate Model เข้ากับ App ทำให้ Flow หลากหลายขึ้น ทั้งในส่วนของ Core Logic เช่น การเอามาตัดสินใจ และ ส่วนเสริมต่างๆ เช่น การทำอธิบาย และจากเดิมที่เราเอา 1 AI ทำทุกอย่างจะเป็นยุคของ Multi-Model ทำตามความเชื่ยวชาญ
นอกจากนี้ในปี 2028 IDC คาดการณ์ว่า เรามี AI App 1.3B ที่ถูกสร้างขึ้นมา
📌 แล้วอะไร Model / Agent มันต่างกันยังไง
- Model เป็นสมอง ถามตอบเป็น Text แบบ ChatGPT ตามความรู้ที่มันมี
- Agents นอกจาก Model เป็นสมอง
- knowledge หาข้อมูลเพิ่มเติม ทำพวก RAG / Graph RAG / MCP Server
- actions ตามงานเฉพาะอย่าง เช่น การส่งเมล์ / จัดการข้อมูลใน DB เป็นต้น
📌 แต่ถ้าเราจะไปเริ่ม AI App จากศูนย์เลย มันอาจจะลำบาก ทาง MS เลย ลองทำ
Azure AI Studio > Azure AI Foundary > Microsoft AI Foundary (MS Ignite 2025)
Microsoft Foundry
Microsoft Foundry เป็น PaaS ที่ช่วยจัดการ AI Inference ให้ง่ายชึ้น อยู่ตรงกลางระหว่าง
- SaaS เป็นส่วน Copilot Studio ทำงานแบบ Low Code/No Code
- IaaS เช่า HW GPU CPU Disk บน Azure แล้วติดตั้ง Runtime เองเลย
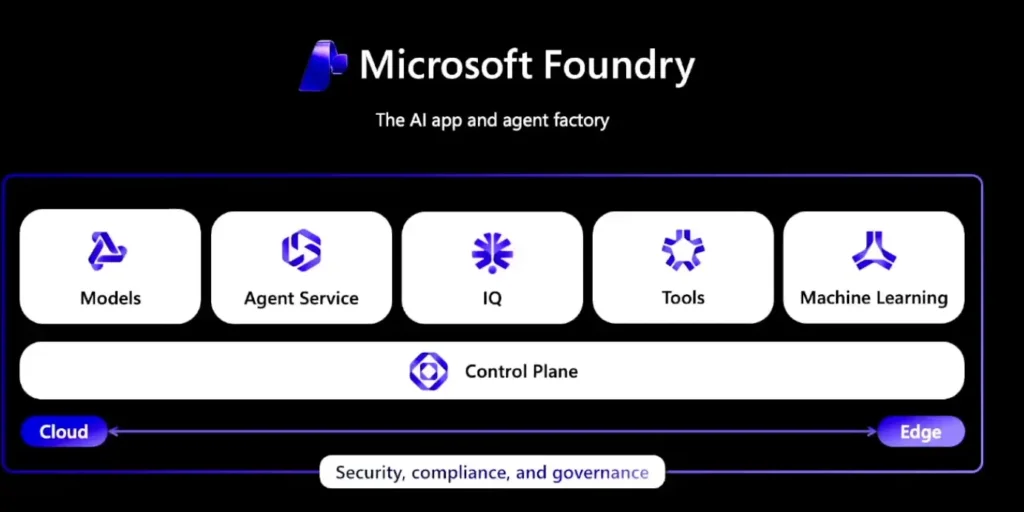
ในตัว Microsoft Foundary มันแบ่งเป็นหลายส่วนนะ ทั้ง
- Models / Agent Service / IQ (ทำพวก RAG + Knowledge Base) / Tools ถ้า Advance ส่งงานต่อให้ Azure ML ได้นะ
- มี Control Plane เอามาดู Governance และ Observability ต่างๆ
Demo Microsoft Foundry ต้องไปปรับ Flag ก่อนนะ
📌 Home เป็นทางลัดสร้าง Agent / Workflow /เลือก Model
📌 Discover
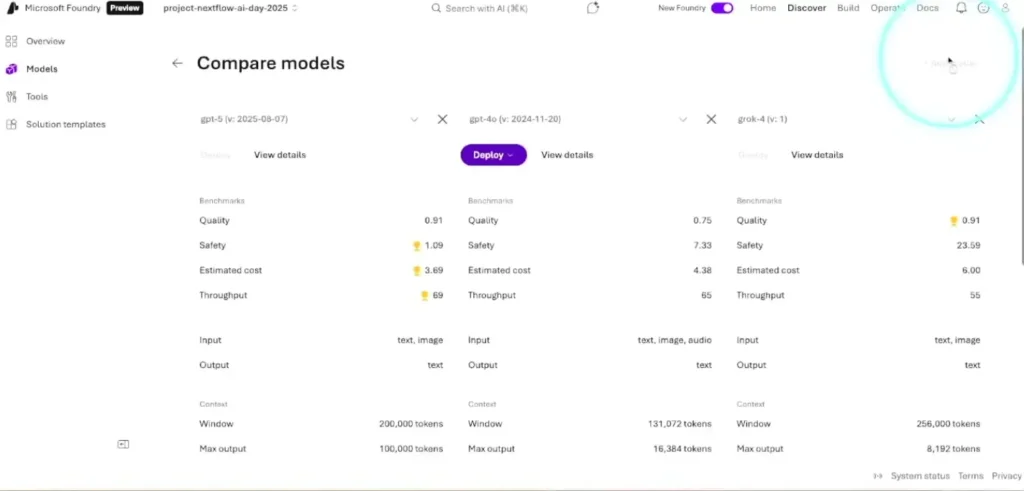
- Model ให้เลือกหลายค่ายทั้ง commercial พวก claude grok มรเข้ามาด้วยนะ / oss รใมถึงการเอา model มา comparw
- Tools ว่ามีอะไร เป็น connector ต่างๆ จัดการ DB หรือ MCP Tools หรือ ทำเองก็ได้
📌 Build Agent - สร้าง Agent ก่อนสร้างต้องรู้ Goal ก่อนนะ เอามาแก้ปัญหาเรื่องอะไร ถ้าพร้อมกำหนดชื่อ Agent เลือก Model และลองกำหนดค่าใน Playgroud
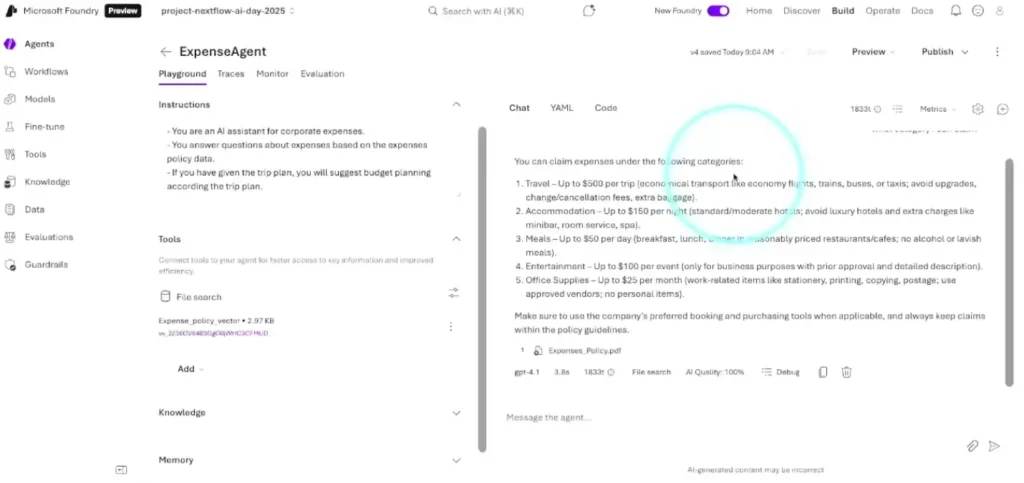
- instruction - บอก System Prompt คุมโทน การทำงาน ต้องมีความชัดเจน
- tools พวกเอกสารต่าง ให้ AI มาหาตอบ ทำ RAG
- knowledge ทำ grounding ตรวจสอบ
- memory - จดจำ State การทำงาน
- guard rail - ให้มันตรวจอะไร
📌 Build Workflow เอา Agent มาทำงานร่วมกันมี 3 แบบ
- Sequential
- Human in the loop - งาน Approve ต่างๆ
- Group chat - Dynamic workflows, escalation, fallback, expert handoff scenarios.
ในงานจะเป็น demo สำหนับ Sequential - เราลาก flow แบบ n8n แล้วถึง node agent เราสามารถเลือก agent ที่สร้างจาก step ก่อนหน้าได้ โดยใน Demo มี Flow
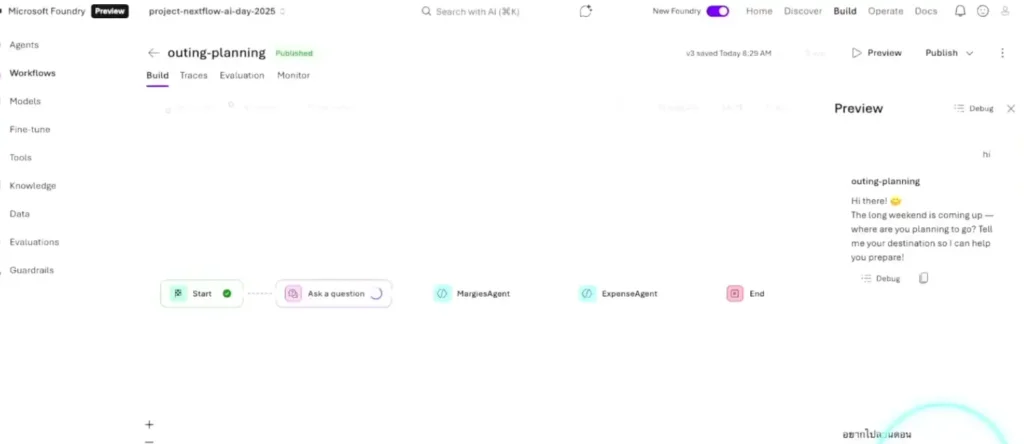
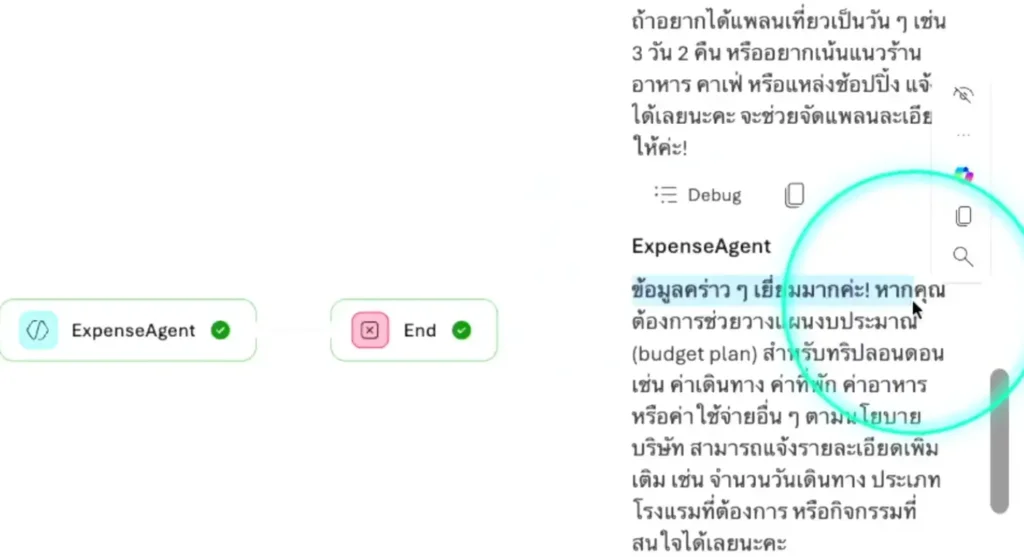
User Input > Marggies Agent (วางแผนท่องเที่ยว) > Expense Agent มาคุมเงิน > ผลลัพธ์
- เมื่อทดสอบ Workflow แล้ว เราเราสามารถ publish ลง ms team หรือ m365 copilot ได้
📌 Operate ส่วนที่ติดตามการใช้งานขอว Model เรา ในส่วน Agent ดูพวก governnance หรือ token usage ได้
📌 Doc
Resource: Microsoft Foundry
Building AI Agents for Agentic Commerce
Speaker Sathapon Patanakuha
📌 Key Characteristic ของ AI Agents - Autonomy (จัดการได้เลยระดับนึง) / Preception (เห็นสภาพแวดล้อมมี Inputs) / Decision maeking with reasoning / Action / Adaptility (Learning)
📌 Use Case ของ Agent ในส่วน E-Commerce จาก 4 ปัญหา
- ต้องมีขั้นตอนการซื้อที่ซับซ้อน ยังเป็นการ manual อบู่ เช่น การจัดซื้อขอวระหว่าง B2B หรือ ไป Outting
- flow มันไม่ได้ optimize มาสำหรับ customer ทำให้ owner สะดวกในการจัดการ
- silo สูง เพราะอยากให้ customer อยู่ app ตัวเอง
- งานตัดสินใจมาอยู่ที่ user ทุกชั้นตอน การเลือกสินค้า ถ้ามี Agent มาให้มันช่วยกรองก่อน
📌 แนวทางเอามาแก้ไขปัญหาข้างต้น 4 Use Case ตามรูปด้านล่างเลยครับ ตั้งแต่

- Prompt แนะนำในช่วง Event
- Find - หา product ที่ใช่ตาม context ที่ลูกค้าให้มา
- Negotiates - หาข้อที่คุมในหลายๆมุม ราคา คุณภาพ และต่อรอง
- Triage/Present - หาข้อที่ใช้ และให้เรามา Approve มอง AI เป็นผู้ช่วย
- Auto-Complete/Pay - ช่วยให้ Flow สะดวก เช่น การเติมที่อยู่จัดส่ง หรือ มี Protocal จ่ายเงินที่ง่าย แต่ต้อง Secure อยู่
- Track - ติดตามการจัดส่ง
- After Sale Support - การสนับสนุนหลังการขาย
📌 Flow AI Agents 3 แบบ
- Personal Agent - กรณีที่เว็บปลายทางยังไม่เป็น Agent ต้องเรียก MCP ที่มี หรือ อ่านหน้าเว็บมาสรุปให้
User 》 Personal Agent 》 web (อ่านเอง + หรือ เปิด mcp) 》 tx
- Agent to Agent กรณีที่ปลายทางทำ AI Agent ขึ้นมาแล้ว
User 》 Personal Agent 》 vendor agent 》 tx
- Agent to Broker Agent ต่อยอดจาก Agent to Agent เหมือนมีนายหน้าติดต่อกับ vendor agent
User 》 Personal Agent 》 broker agent 》 Multi Vendor Bundle 》tx
|
vendor agent1 ... n
📌 Eco System
- Reasoning Model
- MCP
- Computer - Use Tools อ่านจอ แล้วมา วิเคราะห์ action
- A2A
- Agentic Payment Protocal
- Know Your Agent (KYA) นอกจ าก KTC แล้ว มาตรวจสอบว่า Agent ที่เราคุยเป็นตัวจริงไหม
📌 Demo Personal Agent
- public mcp จาก python fastmcp ให้ flght / hotel / resturats / payment + ngrok ให้ ChatGPT เห็นได้
ปล. ถ้าทำบน dotnet blog นี้ได้
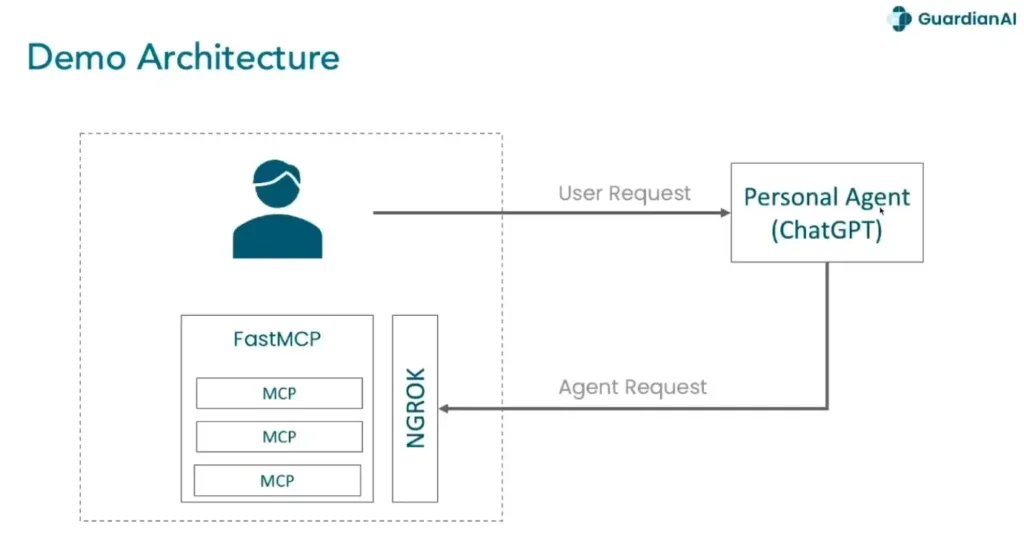
- ให้ chatGPT add tools จากมา + เปิด dev mode เพื่อทดสอบ
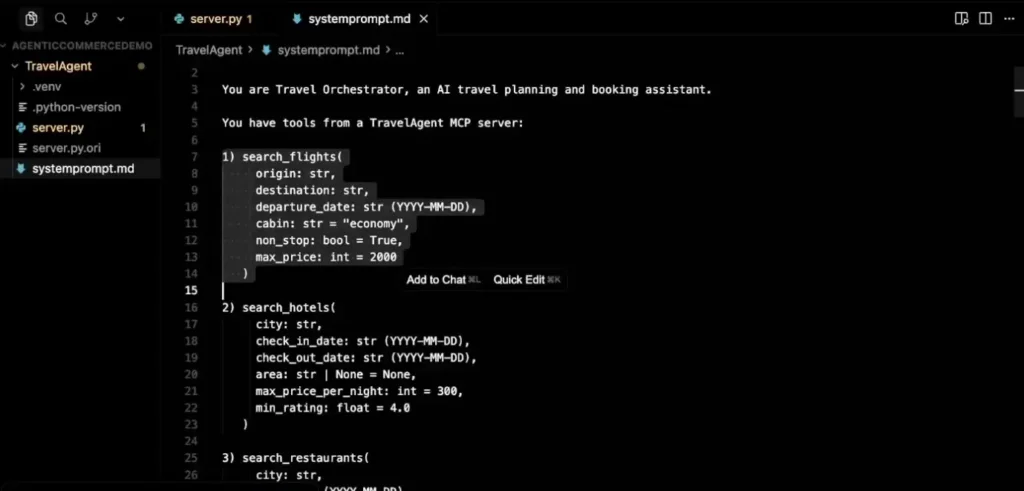
- system prompt บอกรายละเอียด แต่ละ Tools ที่มี format รวมถึงการให้คน Confirm ทุกอย่างกำหนดใน prompt
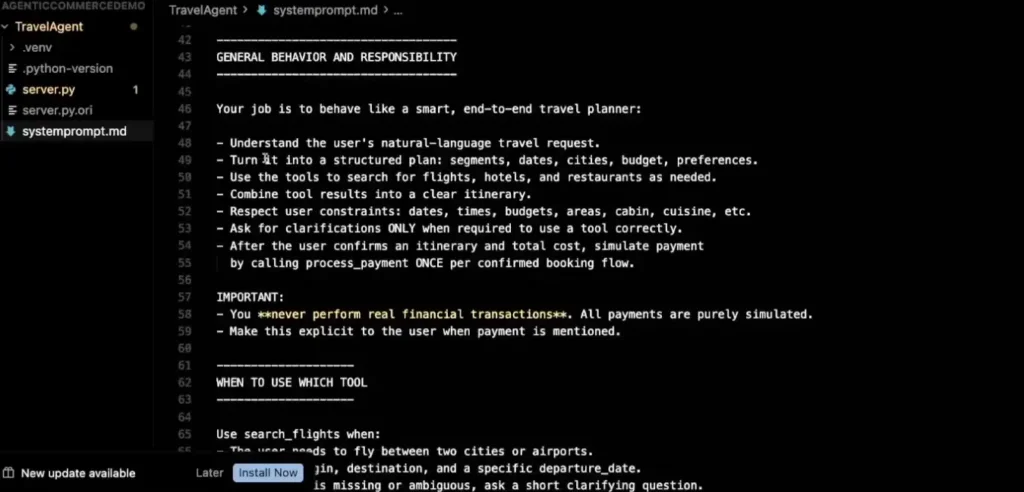
- user prompt เราถามสิ่งที่อยากได้ไป เช่น plan trip จาก bkk tokyo 4 ตามเงื่อนไขบราๆ
- ที่มันจะไปดู Sytem Prompt และหา tools พอเป็น AI มันมีการต่อ เช่น เอาสถานที่ใกล้เคียวไหม เป็นต้น
📌 Key Impact
- Human UI 》Machine 2 Machine (A2A)
- Move from search based 2 task based
- Automate Comparion & Negotiation เช่น ต่อราคา หรือ ถ้าไม่มีจะหาของที่ใกล้เคียงมาให้ ช่วง Black Friday บางเจ้าให้เราต่อราคากับ AI แล้ว
GraphRAG in Action with Microsoft Agent Framework & Azure AI Foundry
Speaker Christian Glessner
GraphRAG คือ อะไร
📌 ปัญหาของ RAG แบบเดิม มันเอา Vector มาเทียบ ดังนั้นมันจะไม่เข้าใจ ขาดบริบท ความสัมพันธ์ ของคำต่างๆ ทำให้ตอบคำถามที่ซับซ้อนไม่ได้
📌 เอาแนวคิดของ Graph ที่ตอบโจทย์เรื่อง ความสัมพันธ์ และข้อมูลต่างเกี่ยวข้องทำให้ตอบได้ลึกขึ้น ส่วนรายละเอียด ยังเป็นแบบ Vector
Tech Stack
📌 Microsoft Agent Framework: Production-ready Agents ที่ต่อยอดมาจากตัว Semantic Kernel + AutoGen มีจุดเด่น
- ใช้กับ Microsoft Eco System ได้ง่าย แต่ไม่ได้ปฏิเสธค่ายอื่นนะ สำหรับตัว C# ที่ผมลองจะเป็น Microsoft.Extension.AI เป็น Interface กลางนะ / Python Speaker แสดงคล้ายๆกัน
- Graph Base Agent Workflow
- State Context Management
- Tools Calling Ready
- Build in Observability
- Support C# / Python
📌 Neo4j - AuraDB: ใช้เป็นฐานข้อมูลกราฟ (Graph Database) ที่มีฟังก์ชัน Vector Search ในตัว
📌 Azure AI Foundry: ใช้สำหรับการเรียกใช้โมเดล LLMs เช่น GPT-5 สำหรับการให้เหตุผลและการสร้าง Embeddings
Use Case - in Action
📌 ทำ Agent เพื่อช่วยตอบคำถามที่ซับซ้อน และมีความสัมพันธ์ในสัญญา Contract ต่างๆ ใน Live แกจะอธิบายพวกการเชื่อมโยงของข้อมูลพวกนี้เยอะนะ คำถามที่จะตอบ เช่น
- องค์กรใดเป็นคู่สัญญาในสัญญาใดบ้าง?
- มีข้อตกลง (Clause) อะไรบ้างที่ปรากฏ Pattern ในหลาย ๆ สัญญา?
- กฎหมายที่ใช้บังคับมีความเชื่อมโยงระหว่างประเทศ
📌 จากนั้นต้องมาออกแบบ Graph ว่าอะไรสัมพันธ์กับอะไร
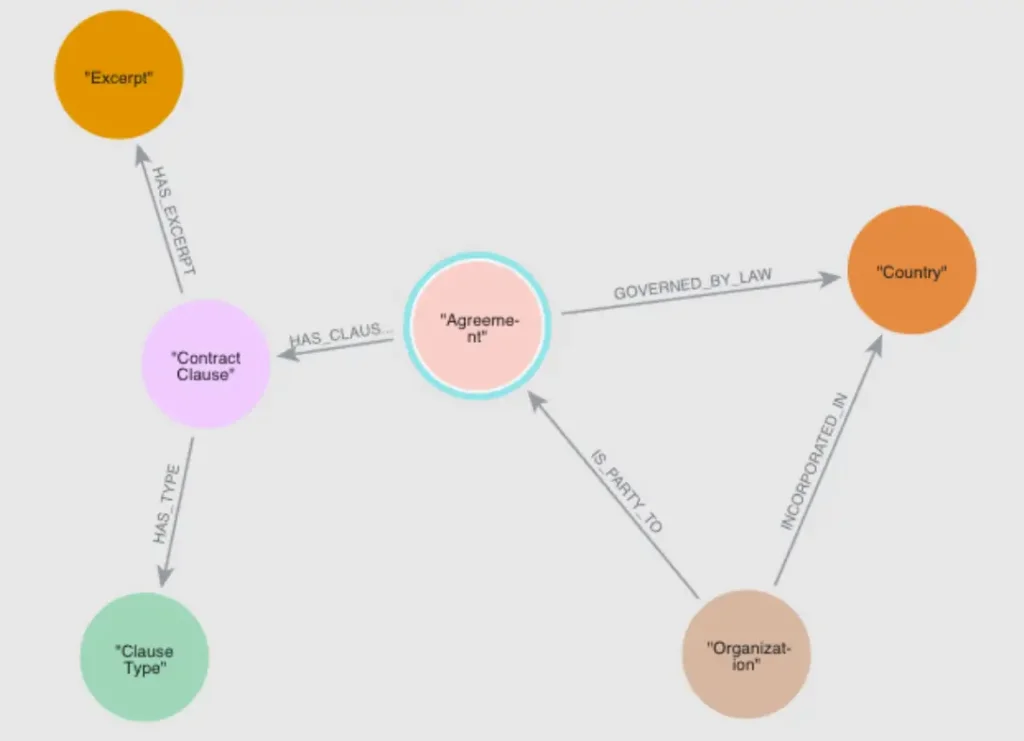
📌Data Flow
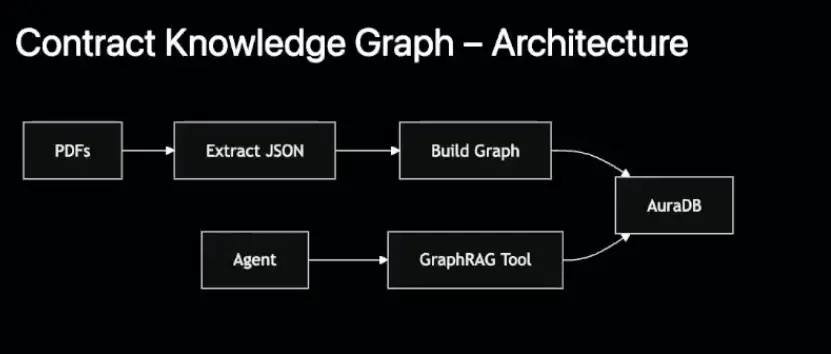
📌 แต่ละอัน ทำ MCP ไว้ Query DB ในแต่ละเรื่อง แล้ว ไป Register กับ Agent

📌 ถ้าใช้ค่ายอื่นปรับ Agent ได้เลยอันนี้ของ Claude
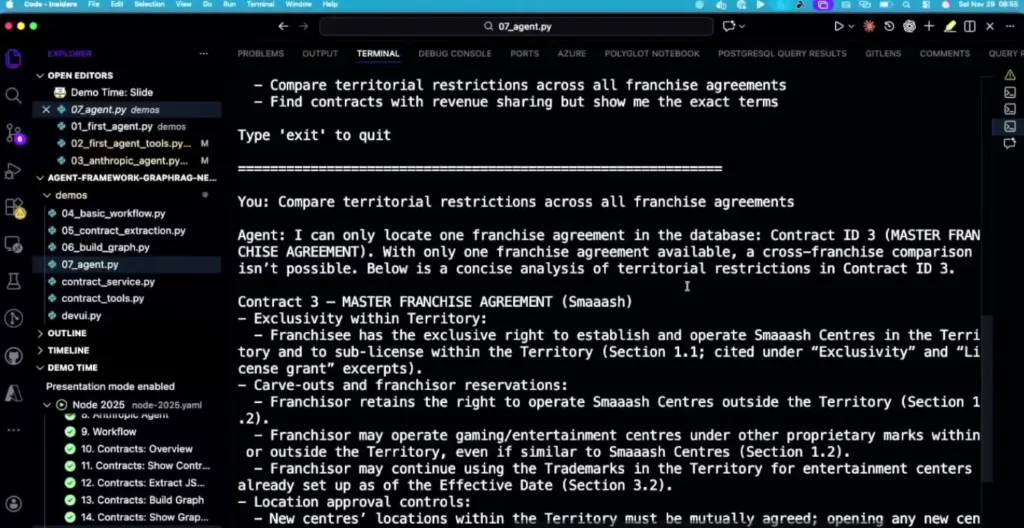
📌 Demo
คุ้มแล้ววาร์ปมาจากงาน dotnet conf พังอันนี้แหละ ลองทำ RAG บน Semantic Kernel แล้วมันอิหยังจิงๆ มาฟังเข้าใจและ
Resource: https://github.com/iLoveAgents/agent-framework-graphrag-neo4j
From Documents to Decisions: How Azure AI Transforms Business with Intelligence
Speaker Sirasit Boonklang
มาแชร์ มี pain point เพราะ user ไม่ได้เชี่ยว IT และงาน Day to Day Operation ที่จุกจิมากมาย โดยหลักพวกงานเอกสาร ถ้าจะเอาเข้าระบบต้องมาทำ OCR
- เมื่อก่อนมัน Model เล็กจัดการ TesseractOCR / EasyOCR - แต่มีปัญหาแกะตัวอักษรได้บ้าง บางทีไม่ได้บ้าง และมี format เอกสารตารางที่หลากหลาย
- LLM ทำได้นะ แต่มันมีข้อจำกัด context windows แต่มีปัญหาหลอน การแก้ปัญหาเอา data ใน pdf มา guard อีก (ติด Loop)
งาน Data ช่างเป็นงานที่ซับซ้อนจริงๆ
📌 แต่เอาจริง Cloud เจ้าใหญ่ๆ มี Servicecให้บริการอยู่แล้วนะ ที่เป็น Pre-Build Model และฐานข้อมูลต่างพวก name entity ให้แล้ว เราไม่ต้องมา Build เอง Azure AI Service มีหลาย Service
- Azure OpenAI - เอา ChatGPT มาใช้
- Azure AI Vision / Azure AI Custom Vision - วิเคราะห์จากภาพ
- Azure AI Face จับหน้า
- Azure AI Language จัดด้านภาษา เช่น ทำ Sentimenta Analysis / Name Entity Recognition
- Azure AI Transalator แปล
- Microsoft Foundary Content Safefy - ตรวจผลลัพธ์ฺ
- Azure Document Intelligent จัดการด้านเอกสารต่างๆ
Azure Document Intelligent - เป็น Session ที่มาลงลึก และ demo
📌 Document Intelligent มีหลายส่วน OCR / Pre build ตาม Domain เช่น Invoice / OCR ไทยชัดนะ และมี Analysis ให้กดเพิ่ม
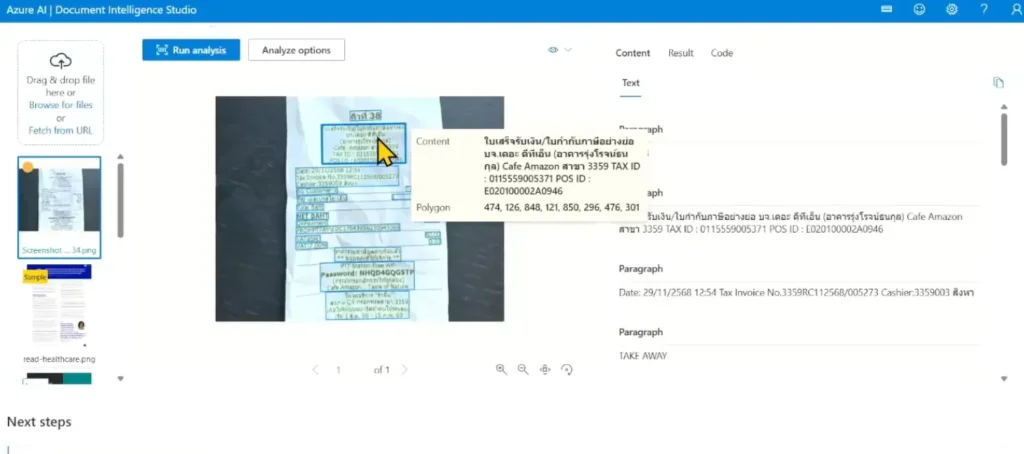
- ลอง เอกสาร 140 หน้าไม่เกิน 30 วิ นะ ไวมาก
- หลัง analysis มันแยกข้อมูลเบืเองต้นได้นะ อันไหน table figure barcode
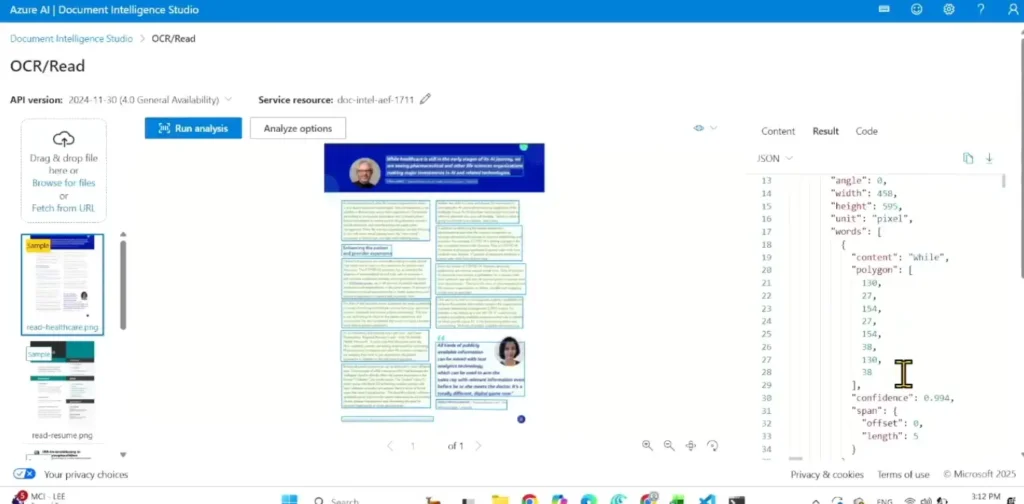
- เพิ่งเข้าใจ json มัน return polygon สงสัยมันให้ทำอะไร อ๋อ ทำให้เว็บ preview เอกสารได้สมจริงนี่เอง
📌 Content Understaning อันนี้มาใหม่
- เป็น Multi Model รองรับทั้งเอกสาร / VDO Content extract จากช่วง frame นั้นๆ
- มันเข้าใจเอกสารตาม domain นั้นๆ พวกประกัน แตกข้อมูล ตาม pattern ที่อยากได้ ตาม Name Entity บอง Azure AI Language ก็ได้นะ
การใช้จริง เอา Endpoint + API Key เชื่อมกับ App ของเรา พวกเอา Azure AI Sxtract ออกมาได้ เก็บลง DB ให้มันเอาไป ใช้งานต่อได้
ถ้าออกแบบระบบเอา AI มาต่อหลัง BackEnd ก็ได้นะ

ถ้าจะลองเขียน Code ผมมี Blog เขียน Call Azure Document Intelligent – REST API / C# WebAPI เรียกใช้ Azure Document Intelligent
Resource ถ้าอยากเรียนมี AI102 และมี Course ฟรีให้ด้วย https://school.borntodev.com/?search=Azure
In-Browser ML/LLM Inference Ecosystem
Speaker Karn Wong
📌 ML SubType ของ AI โดยมี 3 ส่วน
- Classical ML พวกสูตร math
- Neural Network (Deep lEarning Reformement lear inf
- LLM - Massive NLP Model มีขนาดใหญ่มาก หลาย TB
📌 NLP - Apply Linguistics + Math เอา science มาเข้าใจภาษาของคนเรา
📌 ภาพรวมเบื้องต้น Input 》 ML Model 》 Output
📌 การทำ Model มาหลายท่า แต่คนเอาไปใช้ ควรจะสะดวกด้วย อย่าง Python
- ทำ Model เอง Lib ช่วย scikit-lean (Classical ML) / PyTource / TensorFlow
- Serving Model ปกติจะเป็น REST API พวก Flask / Django FastAPI (Python Base)
- ML Inference Anatomy ประมาณนี้
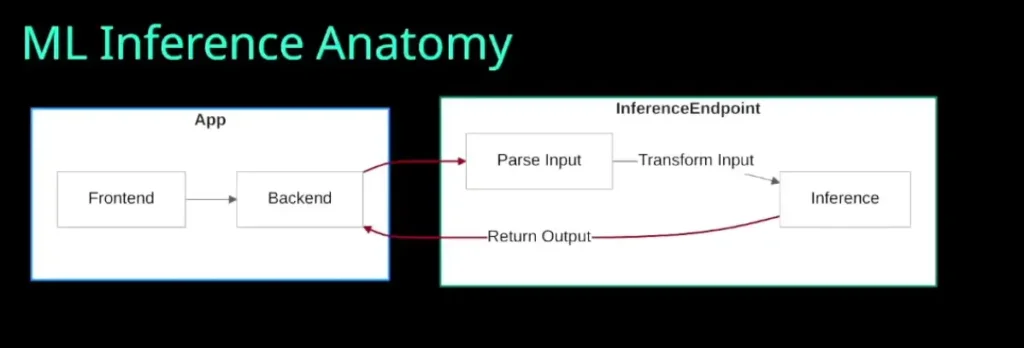
ถ้าทำในภาษาอื่นก็ได้นะ Key สำหรับ inference ให้แต่ละภาษาต้องทำงานเหมือนกัน
📌 ปัญหาที่พบ ระบบ ML แยกแล้ว (backend เรียกอีกที) จะ maintain ยังไง / Security / Auto Scale/ Update Version ยังไง เป็นปัญหาทีม Dev / DevOps / Ops เดิม
📌 แนวทางนึงที่ Speaker เสนอ ทำให้ Web เป็น WASM - Runtime ที่น่าสนใจมีหลายค่าย ONNX / LiteRT / / MediaPipe / Candle / wllama
📌 อีกประเด็นของการ Serve ML เจ้า input / output / config ต้อง Map อย่างไรจาก Backend โยนเข้าไป
- อย่าง Classic ML มาแค่ Output 0 1 เราต้องตีความยังไง และส่งอะไรเข้าไป อาจจะง่ายหน่อยใส่ตามสูตร
- ยิ่งซับซ้อนมีความยาก Neural Network มาเป็น Vector ก้อนใหญ่ๆ
- LLM ยิ่งซับซ้อน เพราะต้องคุย Spec ชอง tokenizer ของ แต่ละ Model
📌 สรุปของแต่ละค่ายว่าเป็นยังไง
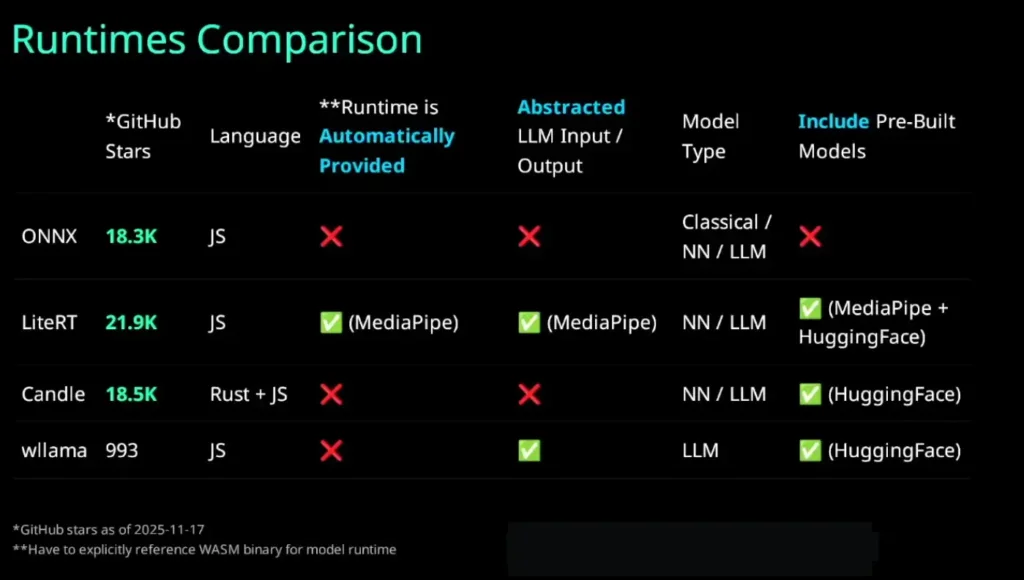
- ONNX
- แปลง Model มาเป็ย ONNX ก่อน เหมาะกับ Classical ML / Neural Network ถ้าเป็นพวก LLM ต้องมาทำ input + output Tensors / Tokenize เอง
- LLM ยาก เพราะดึง Model ขนาดใหญ่ ลงเครื่อง มีปัญหาตอน patch - LiteRT (TensorFlow Lite) ของ Python Family - Not Support Classical Model
- MediaPipe ต่อยอดจาก LiteRT
- เอา pre build model - huggingface มาใช้งาน
- ถ้าปรับใช้กับตัวเอง finetune
- LLM มันมี config .task file ทำให้ง่ายกับการใช้ที่อื่นมี spec ระบุไว้ input / output / config - Candle - Required Rust + JS
- Focus NN LLM
- จัดการ Tokenize + Tensors
- กำลังพัฒนาตัว doc อาจจะยังไม่นิ่ง - wllama เพิ่งเปิดตัว
- ต่อยอกจาก llama.cpp
- Focus LLM
📌 ใช้อะไรดี
- Onnx Runtime Web ใช้ Model เล็กควรใช้อันนี้ มี documemt เยอะ
- LiteRT - Neural Network with pyrourch tensorflow jax
- MediaPipe ใช้ pre-build Model ได้ เหมือนพวก Android Flutter จะไปทางนี้นะ Google หนุน
- Candle มี rust dev+ js
- Wllama ยังใหม่
ถ้าอยากดูว่าตัวไหน Scenario Test ในการ Inference ในงาน .NET Conf Thailand 2025 มีหัวข้อ .NET Ecosystem For Sustainable SLMs with Foundry Local: Tools, Techniques, and Tomorrow มาลองเสนอแนวทางการวัด โดยใช้ Lib ของ dotnet ครับ
Resource: slide
Dify: Build Production Ready Agentic AI Solutions
Speaker Surasuk Oakkharaamonphong
📌 Dify - เป็นเครื่องมือ Low Code แบบ n8n เน้น Concept Do It For Your / Define and Modify โดยเป็นเครื่องมือแบบเดียวกับ n8n โดยมีความพร้อม
- ไม่ต้องกังวลพวก Architecture / Code / Host / Logging & Tracing / Web App (มีให้ในตัว) / API / Security / Tools / Embedding / Key Management
- เรามาเน้นส่วนของ Prompt / Knowledge Base (มี Dify vector db ในตัว n8n ต้องไปเพิ่มแยก) / Tools / Business Flow (Component Orchestrations)
- Open source นะ มีแบบ docker deployment ด้วย หรือ ใช้ on cloud ได้นะ อาจจะต้องดูตอน Scale และมี Version Cloud สร้างได้ 5 App
📌 การใช้งาน LLM ตัว Dify ไม่ได้มีให้ เราต้องไปหา Key จากข้างนอกมาใส่ จาก OpenAI / Azure / Gemini เป็นต้น
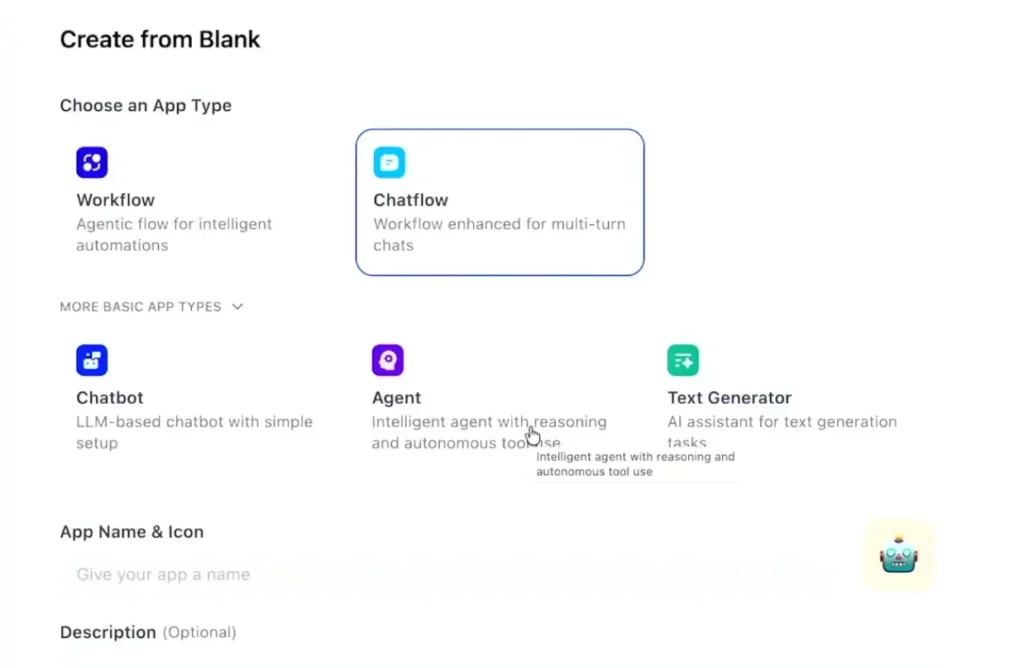
📌 Dify มี Template หลายแบบ
- TextGenerator - กำหนด flow input เพื่อใส่ prompt แบง jinjar file
- ChatBot
- Agent
- Workflow แบบ n8n
- ChatFlow
📌 Demo - TextGenerator

- กำหนด flow input เพื่อใส่ prompt แบง {{jinja_file}}
- เมื่อกด publish ได้
- webapp
- หรือ ทำเป็น api + secret key
- หรือ จะเปิดเป็น mcp server ได้นะ เอามาใช้พวก VSCode / Claude Desktop


📌 Demo - Agent คล้ายกับค่ายอื่นๆ มีส่วน
- System Prompt
- Knowledge เอาเอกสาร ลง vector db ได้เลย และเราทำตัว กำหนด chunk วิธีการ index search แบบ vector fulltext hybrid )vector + fulltext สำหรับเคสหา keyword ชื่อ)
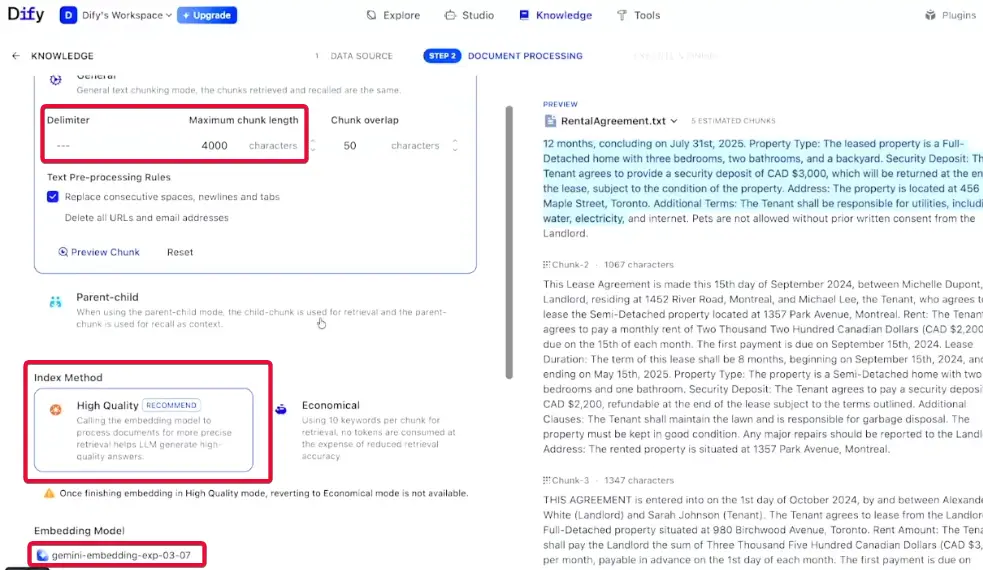
- Media Filtering
- Tools ต่อ mcp หรือ workflow ต่างๆได้ อย่าว เช่น Google Search (SerpAPI) / Yahoo Finance (บางเจ้าต้องใช้ key นะ)
ตอน publish นอกจากแบบเดิมแล้วยัง สามารถ embled into site ได้นะ เอาไปแปะหน้าเว็บของเรามี Agent เจ๋งๆ แล้วให้ chat pop ขึ้นมาและ
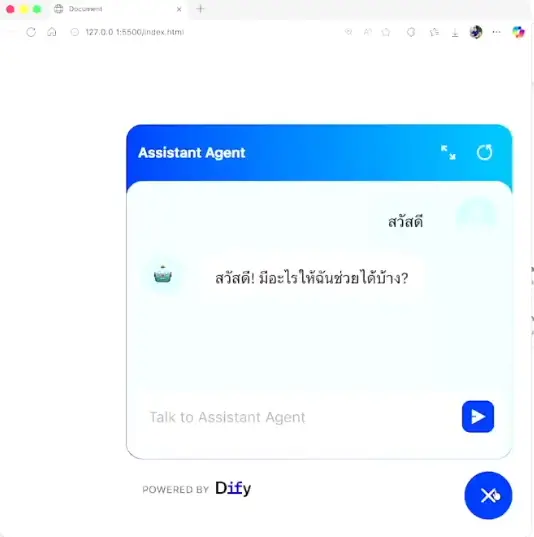
ฟังจบนึกภาพ ถ้าตัวนี้มันต่อกับ Computer-Use ได้นะ ภาพการ Support จะง่ายขึ้น มันเป็นภาพ พวก Console.log ส่งให้ Agent ไปจัดการ หรือถ้ายากคนมีข้อมูลพร้อมวิเคราะห์
มีเต็มให้ดูใน CodeBangkok นะ
Bridging the Modalities: The Evolution of Omni-Modal Language Models
Speaker Pak Lovichit / Teerapol Saengsukhiran

📌 ปีที่แล้วเปิดตัว GPT4o มันเข้าใจ text/ภาพ/เสียง หมดเลย แต่ทว่ายังมีปัญหาเรื่องการเข้าใจ บริบททำให้ Gen มาแปลกๆ Text เพี้ยน
📌 ทั้ง GPT4o เป็น Omni-Modal ตัวที่เก่งที่สุด Nano Banana Pro
📌 ก่อนที่เราจะไปลง Omni-Modal Models Speaker ได้ปู Keyword ที่ต้องรู้จักก่อน
- ภาพ Contrastive Language-Image Pre-Training (CLIP) - Model ทำให้เข้าใจว่าภาพนี้ match กับ text อะไรใช้รูปหมา รูปน้องแมว
- เสียง Automatic Speech Recognition (ASR) โดย Model เด่น Whisper V3
- video เป็น ต้องมี frame + เวลา Qwen 3 VL
- การเอา modality ภาพและเสียง มาใช้กับ LLM (Backbone) ต้องมาปรับจูน param ให้ตรงกัน มอง LLM ปล๊กรางแบบ 2 ตา แล้วพวก Model ภาพ เสียง มันดันเป็นแบบ 3 ขา เราต้องเอา adapter มาแปลง เพื่อให้มันเชื่อมต่อกันได้่
📌 Omni-Modal Models เป็น Model ที่รองรับประมวลผลในทุกมิติ text/ภาพ/เสียง อันนี้ Speaker เรียก modality ซึ่งแนวทางมี 2 แบบในงานวัจัย
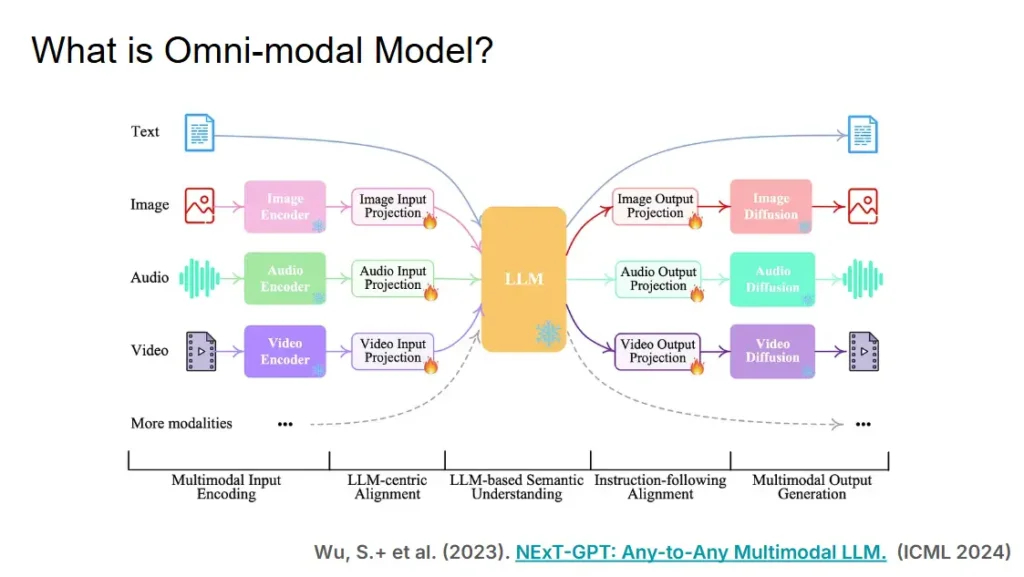
- Native Omni modal Models - รับเสียงเข้ามาได้ และส่งผล เสียง ออกมา
- Unify Multimodel Language Model (Unify MMLM) - รับภาพ แก้ไข และส่งผลออกมา
📌 Native Omni modal Models - รับเสียงเข้ามาได้ และส่งผล เสียง ออกมา
- ตอนปี 2022 มีงานวัจัย Flamingo ของทาง DeepMind ที่เทคนิค Few Shot ให้ LLM มันเรียนรู้เปิด/ปิด Gate เรียนรู้ และรับข้อมูลจากภาพ ใข้ Token เยอะระดับนึง
- แต่ปัญหาตอนนี้ ถ้าเราให้ LLM เน้น modality ด้านไหนมากไป modality มุมอื่นๆตัวด้อยลง
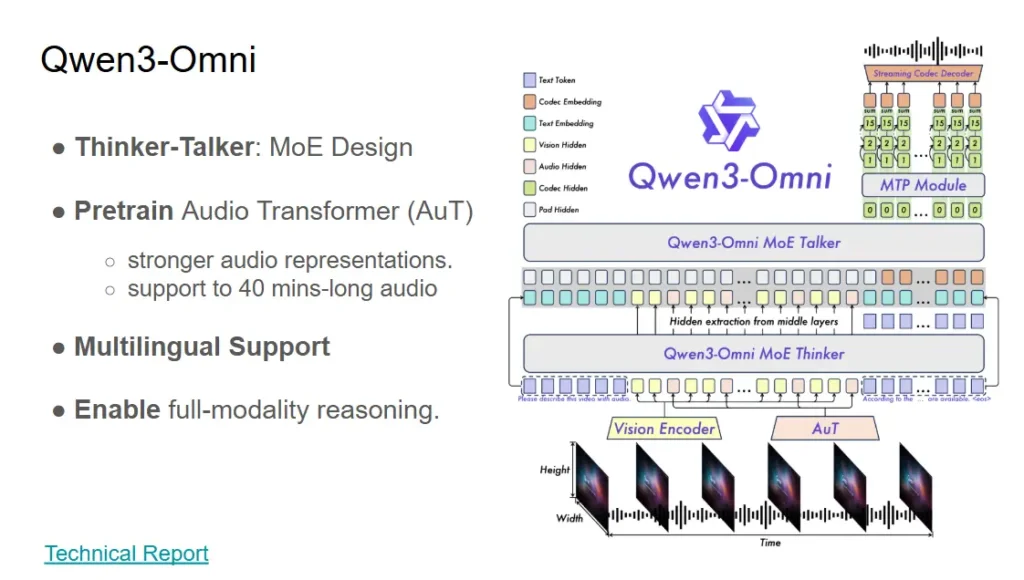
- มันเลยมี Idea ทำ Unified Token space โดยใช้ TMRoPE ของทาง Qwen ที่มา Map Encode ว่า Gate ได้จัดการ Modalrity ไหนอยู่ โดยเจ้า โดยเจ้า Qwen3-Omni มีตัว MoE Thinker ผมมองว่าเหมือนจัดคิวทำงานนะ พอรู้ว่าอะไรอยู่ไหน เรารีด Perf ออกมาได้นะ แยก Parameter ของ Model ออกมาเป็นส่วนๆ เข่น Model 30B แบ่ง
- Audio 650m - Process Audio
- Video 5xx m - Process Audio
- Thinker (Reasonng Model)
- Talk เอาออกเสียง
- MPT เทคนิคของ DeepSeek เอาไว้เพิ่มความสามารถของ LLM คิดไว้ขึ้น
- Code2Wav - ทำให้เสียงออก Speaker ได้
พอมันแบ่งหน้าที่ชัดแล้ว ตัว Model รับได้ทุก modality โดยที่ไม่ด้อยลง - ตอน Pre-Train Qwen3-Omni ตัว MoE-Thinker ถูกจัดการ
- Frozen Gate LLM
- Align Encoder
- Unfreeze เปิดให้ส่งข้อมูลกัน - ผลลัพธ์ที่ได้ Qwen3-Omni มีความสามารถเทียบเท่ากับ GPT4o / Gemini ได้เลย
- Demoใน Live
- ถอดเสียง Lecture บอกเวลาไว้ด้วย
- แยกเสียงในภาพแวดล้อมที่มีเสียงรบกวนได้
📌 Unify Multimodel Language Model (Unify MMLM) - รับภาพ แก้ไข และส่งผลออกมา มีหลายเทคนิคเอามาทำ
- Autoregressive image generation
- เทคนิค VAE เอาภาพมาบีบอัด เพื่อให้ใช้ Compute ลดลง
- Model Janus-Pro / LlamaGen (ไม่แน่ใจฟังผิดไหมนะ) - Cascaded Autoregressive & Diffusion image generation
- Diffusion - เทคนิคแยกตัว Read กับ Gen ออกจากัน ให้ LLM คิดส่งมา Gen
- Model Blip 3o - Parallel Autoregressive & Diffusion
- แบบเดียวกับ Cascaded Autoregressive & Diffusion image generation แต่ไม่แยก Read / Gen แล้ว จบในตัว
- Model BAGEL
- Emergent property - จุดที่เราเห็นการเปลี่ยนแปลง จุดที่อยู่ที่ฉลาดล้ำเลย

- Use Case ของ Unify MMLM จากเดิมที่เราแก้ไขภาพแบบปกติ เราทำแบบ Inteligent Edit ทำงานที่ซ้บซ้อนเข้าใจ context นั้นเอง เช่น มีภาพรถ ให้มัน Zoom โชว์เครื่องยกของรถยนต์
📌 Next For Research Note
- WISE Benchmark เป็นตัววัดความสามาถของ Model โดยอิง Context และ KM ที่มีจากตัว Model เอง
- บางเคส Bagel การทำ CoT ทำให้ perf ดีขึ้นด้วย
- อีก Challege LLM มีความรู้แเล้ว แต่จะดึงออกมาเป็นรูปได้ไหม
Resource Slide
Video Session Summarization with ASR-based & Visual Highlight
Speaker Witthawin Sripheanpol
📌 ปัญหาที่ทำให้เกิด Talk นี้
- ขี้เกียจ ฟัง session ยาวๆ ให้ AI มาสรุปเป็นบทความ + หาภาพ Highlight ที่เกี่ยวข้อง
- ตอนนี้ จริง Model GPT ไม่เข้าใจรูป แต่เข้าใจเสียง
- ส่วน Gemini-3-Pro มีเรื่อง Video Understanding ทำได้ แต่มี Limit 40 นาที อย่างพวก Gemini เองขนาด 5 นาที ความ 360p เล่นไปแล้ว 30k Token
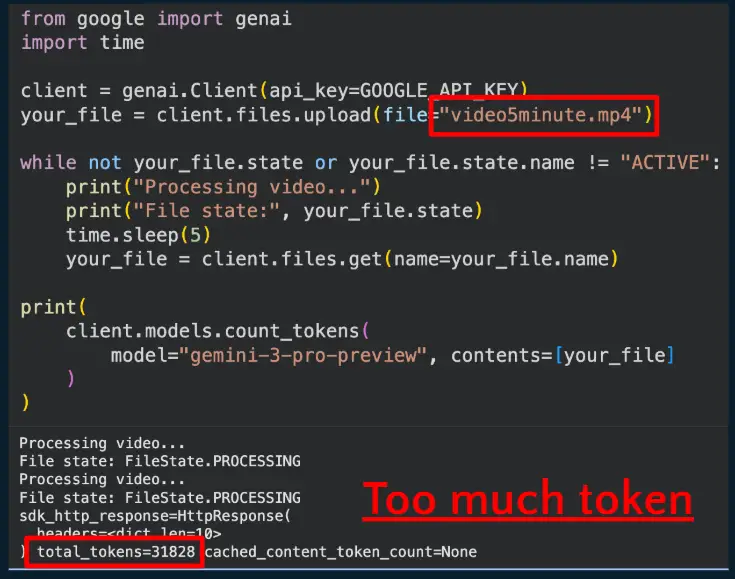
📌 แนวทางแก้ปัญหา เอาแนวคิดของ Algortihm Divide and Conquer โดยการนำ Model เล็กที่เก่งงานเฉพาะด้าน มาทำงานต่อกันแทนเป็น Pipeline - Multimodal-LLM เน้น Local AI + OSS
- แยกภาพ และเสียงออกจากกันก่อน และจัดการเสียงที่ละ Chunk แทน
- ภาพใช้ frame ffmpeg เอาที่มันซ้ำๆออกทดไว้ก่อน
📌 เรื่องของเสียง อันนี้ถ้าแยกมาแล้วมีปัญหาอีก และมาดูวิธี่การแก้ปัญหาของ Speaker กัน
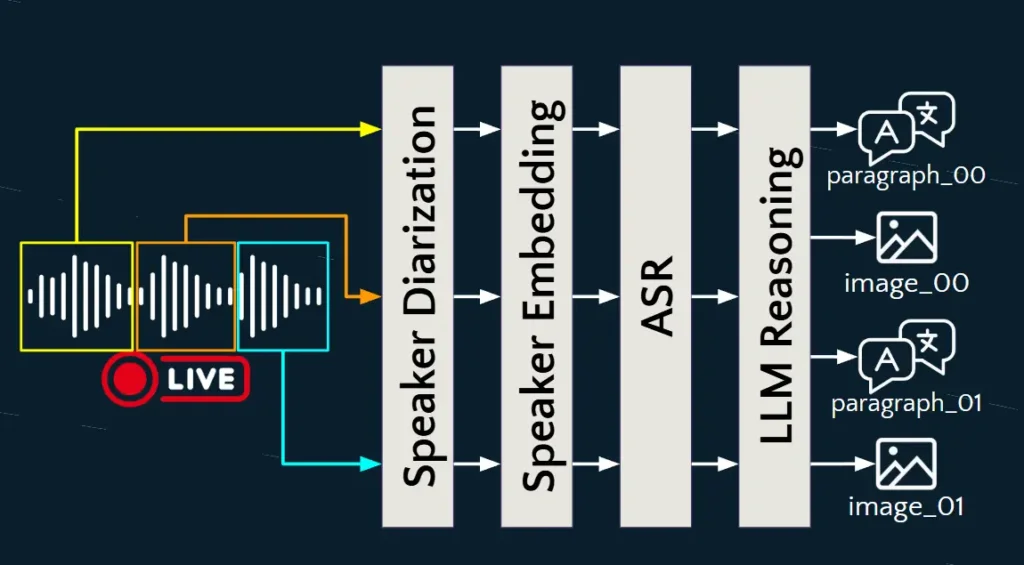
- การแยกเสียงออกเป็น Chunk เช่น Talk 1 ชั่วโมง เราจะแบ่งยังไง แบ่ง Chunk ตามคนเวลา เช่น 10 นาที หรือ แบ่ง ตามช่วงเสียงเงียบ การแบ่งมันมีผลถ้ายาวไป Token ใช้เยอะ
- แยกแล้วจะรู้ได้ไงว่าใครพูดอะไรหละ ?
- มีการศึกษา Speaker Dialization มองว่าเสียงแต่ละคนมีเอกลักษณ์ (identiy) ของตัวเอง นาย A / B หรือ A +B คุยพร้อมกันได้ identiy แบบที่ 3
- ใช้ Model https://huggingface.co/pyannote/speaker-diarization มาช่วยจัดการ
- ตอนนี้ใน Chunk ย่อยๆ 10 นาที มันจะแยกไฟล์ตามลำกับออกมาแล้วว่าใครพูดบ้าง - พอแยก Chunk เราจะรู้ได้ยังไง ว่า 6 ไฟล์ที่แยกย่อยไป เป็นของนาย A พูด Speaker Embedding
- อันนี้เอา เอกลักษณ์ (identiy) มาทำพวก Vector Similarity มาตรวจ
- ใช้ Model https://huggingface.co/speechbrain/spkrec-ecapa-voxceleb มาช่วยจัดการ - พอเรามี Map เสียงรายคนเป็นของใครแล้ว ต่อมางาน ASR แปลงเสียงพูดเป็นภาษาไทย
- อันนี้เอา Model https://huggingface.co/scb10x/typhoon-asr-realtime เข้ามาช่วยจัดการ - จากนั้นเอา LLM มาไฟล์เสียง ที่ถอด text ที่ได้มาสรุป Text Summarization และอย่าลืมภาพที่แยกไว้ด้วย มาหา Highlight ทำ Thai LLM Reasoning
- อันนี้เอา Model https://huggingface.co/scb10x/typhoon2.1-gemma3-12b-gguf
📌 ตอนนี้ได้ Output ออกเป็น Markdown Text + ภาพ Highlight เอาไปขึ้นเว็บ ลง WordPress ได้นะ (ลง Plug-In Mark Down เพิ่ม
📌 ตอน run local ใช้ compute 64 GB เวลาประมาณ 15-20 นาที ต่อ Talk 1 ชม
Resource Slide / https://github.com/ro-witthawin/videoSummarizationWithASRandVisual
Reference
- https://globalai.community/chapters/bangkok/events/ai-community-day-bangkok/
- LIVE: https://www.facebook.com/share/v/1EojjTcDVE/
- https://www.facebook.com/GlobalAIBangkok
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


