Blog ตอนนี้มาเขียน-กึ่งบ่นครับ 555 ปกติแล้วผมจะใช้ Model จากที่มีใน Ollama นี้เอง แล้วบังเอิญว่าเจอ X ของคนนี้ มันมี Model ของ Microsoft เค้าว่ากันว่ากันว่า Model นี้ Run บน CPU ก็ไหวนะ ถ้าใช้แบบพวก M2 จะไวขึ้นอีก
Microsoft just a 1-bit LLM with 2B parameters that can run on CPUs like Apple M2.
— Shubham Saboo (@Saboo_Shubham_) April 18, 2025
BitNet b1.58 2B4T outperforms fp LLaMA 3.2 1B while using only 0.4GB memory versus 2GB and processes tokens 40% faster.
100% opensource. pic.twitter.com/kTeqTs6PHd
และเจ้า Model นั้นตัว microsoft/BitNet b1.58 2B4T ครับ หลังจากเห็นข่าวมาตอน APR-2025 ผมก็รอว่าจะมีใครสักคนลองเอามาทำใน Ollama ไหมนะ เห็นมีคนถามเหมือนกันนะ แต่ยังไม่มี Update
ผมรอจนนานและมาจนถึงเดือน 6 ยังไม่มีนะ เอาหวะ เดี๋ยวมาหาทาง Run เองจาก Code และกัน ตอนแรก ตั้งโจทย์แบบง่ายๆ เอา Model ขึ้น Container และไปหาอะไรสักตัวที่ทำ Endpoint เข้ากับตัว Open WebUI (เว็บหน้ากากให้ Chat เหมือนตัว ChatGPT) ได้ก็พอครับ Blog นี้เลยมาจดประสบการณ์ที่เจอมาครับ
Table of Contents
เตรียมตัวสำหรับ Run microsoft/BitNet
- Linux จริงๆ ผมลองใน docker นะ
เอา image ของ Python ตั้ง และลงตามนี้เลย
# Use official Python 3.12 image
FROM python:3.12-slim
# Install system dependencies for PyTorch and build tools
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
cmake \
git \
curl \
ca-certificates \
libopenblas-dev \
libomp-dev \
libssl-dev \
libffi-dev \
wget \
&& rm -rf /var/lib/apt/lists/*
# (Optional) Set a working directory
WORKDIR /app
# Copy your requirements.txt if you have one
COPY requirements.txt .
RUN pip install --upgrade pip && pip install -r requirements.txt
และกำหนด requirement ดังนี้
fastapi==0.110.2 uvicorn[standard]==0.29.0 transformers==4.52.4 torch==2.7.0 numpy==1.26.4 accelerate==0.29.0
จากนั้นจะ Run แบบปกติ
# Build the image docker build -t python-bitNet . # Run the container with port forwarding and mounting your code docker run -it -p 8888:8888 -v "$PWD":/app python-bitNet /bin/bash
หรือ จะใช้ DevContainer ก็ได้นะ ผมลองใช้อันนี้สะดวกดี
- Windows อันนี้ขั้นตอนเยอะนิดนึงครับ สำหรับคนที่ชอบความท้าทาย
ที่เขียนว่าท้าทาย เพราะผมลองแล้วติดมา 2 week 555 ขา Linux มันแปบเดียวจบ โดยสำหรับใครที่อยากลองต้องมีของตามนี้
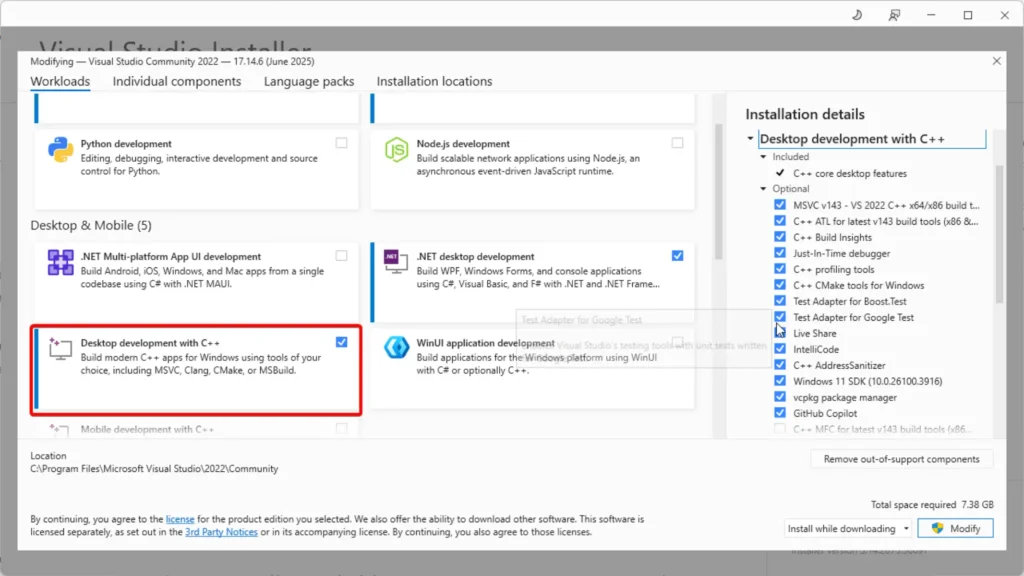
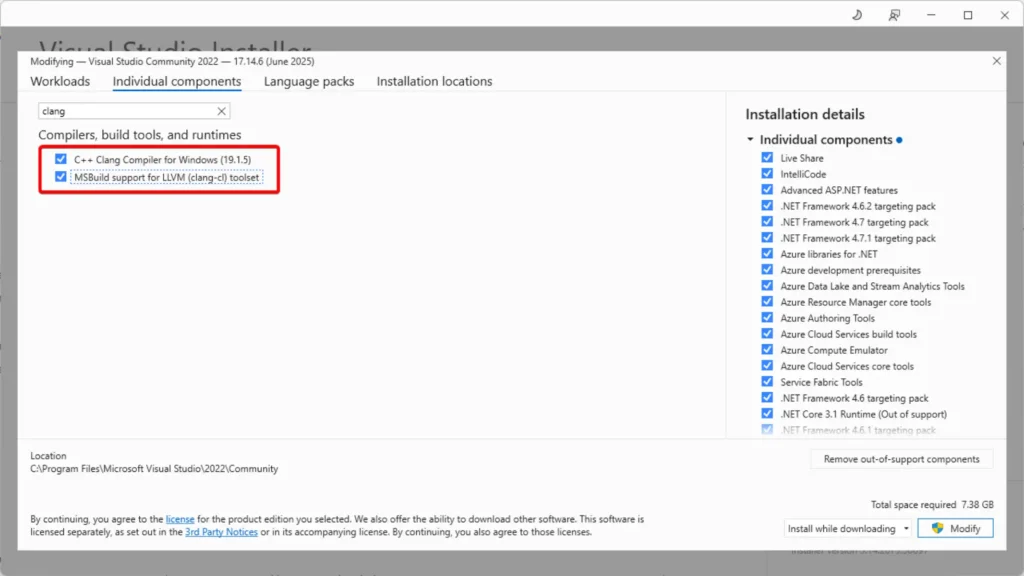
- สำหรับใน Visual Studio ต้องลงส่วนของ C++ เพิ่ม ดังนี้
- รัน PowerShell ไม่รอด ต้องไป Run ใน Developer Command Prompt for VS 2022 หรือ Developer Command Prompt for VS 2022 เหมือนตัว Terminal ปกติ มัน Set ตัวแปร พวก Path อะไรไม่ครบ จะเจอ Error แนวๆ
Error C1083: Cannot open include file: 'algorithm': No such file or directory
แม้ว่าจะลอง set vcvarsall.bat x64 จะอารมณ์ผีเข้าผีออก บางรอบได้ บางรอบไม่ได้
ปล. vcvarsall.bat
อยู่ใน "C:\Program Files\Microsoft Visual Studio\2022\Community\VC\Auxiliary\Build\vcvarsall.bat"
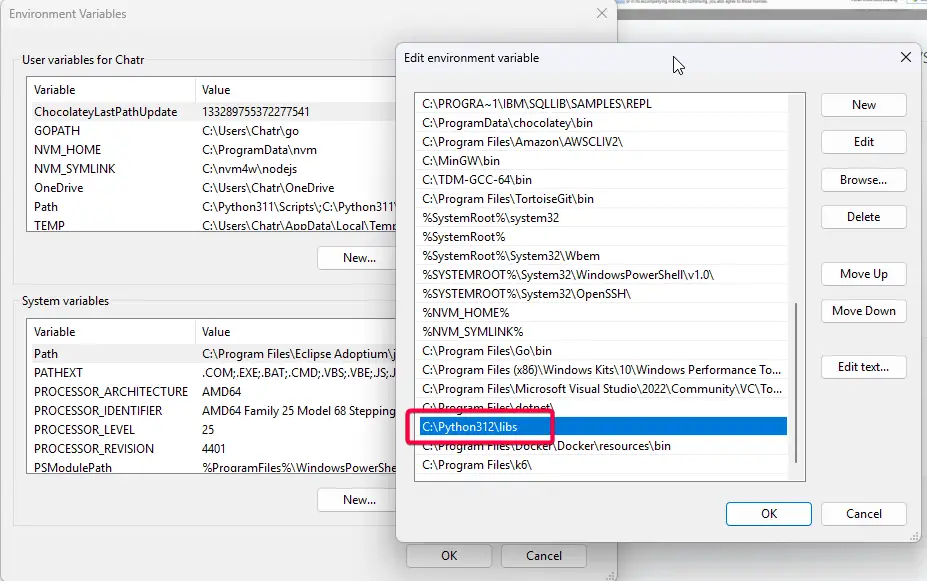
- set python lib .tlb ใน path > ไม่ใส่จะพัง
fatal error LNK1104: cannot open file 'python312.lib'
และ หลังจาก Env พร้อมแล้ว กำหนด
- Set Virtual environment
# Set ENV python3 -m venv bitnet-env # or python -m venv bitnet-env
- Activate Virtual environment
# Linux source bitnet-env/bin/activate # Windows - Powershell .\bitnet-env\Scripts\Activate.ps1 # Windows - CMD .\bitnet-env\Scripts\activate.bat
- Install Require Lib ตาม requirements.txt ถ้าดูจาก Linux (Docker มันจะมีแล้ว)
fastapi==0.110.2 uvicorn[standard]==0.29.0 transformers==4.52.4 torch==2.7.0 numpy==1.26.4 accelerate==0.29.0
pip install --upgrade pip && pip install -r requirements.txt pip install git+https://github.com/huggingface/transformers.git@096f25ae1f501a084d8ff2dcaf25fbc2bd60eba4
เขียน Code เรียกใช้ Model จาก Hugging Face
หลังจากหมดปัญหาเรื่อง ENV มาลอง โจทย์ดีกว่า ตอนแรก ผมบอก อยากให้ต่อกับ OpenWebUI ได้ เลยทำมา 2 Version แบบ Command Line / แบบ API
- แบบ Command Line
ลองเขียน Code โดยใช้
- Transformers - เพือดึง pre-trained มาจาก Hugging Face
- PyTorch (torch) - เพื่อ inference จาก Model ที่ตัว Transformers ดีงมาให้ (ในตอนนี้นะ จริงๆ Spec ที่ Run น่าจะได้เท่านี้แหละ ส่วน Train / Fine Tune) จุดที่ใช้มีหลายส่วน
- torch_dtype=torch.bfloat16 ใช้ตัวนี้มันกิน Memory น้อย ตอนคำนวณมันจะเอามีทศนิยมแหละ แต่ไม่ละเอียด เท่า FP16
- return_tensors="pt" ให้ใช้รูปแบบของ PyTorch (pt)
- to(model.device) ถ้ามีพวก cuda เอามาเสริมความแรงได้
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "microsoft/bitnet-b1.58-2B-4T"
# Load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
force_download=True,
)
# Apply the chat template + Role
messages = [
{"role": "system", "content": "You are a Senior Programmer."},
{"role": "user", "content": "Can you help me with a coding problem?"},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
chat_input = tokenizer(prompt, return_tensors="pt").to(model.device)
# Generate response
chat_outputs = model.generate(**chat_input, max_new_tokens=50)
response = tokenizer.decode(chat_outputs[0][chat_input['input_ids'].shape[-1]:], skip_special_tokens=True)
print("\nAssistant Response:", response)
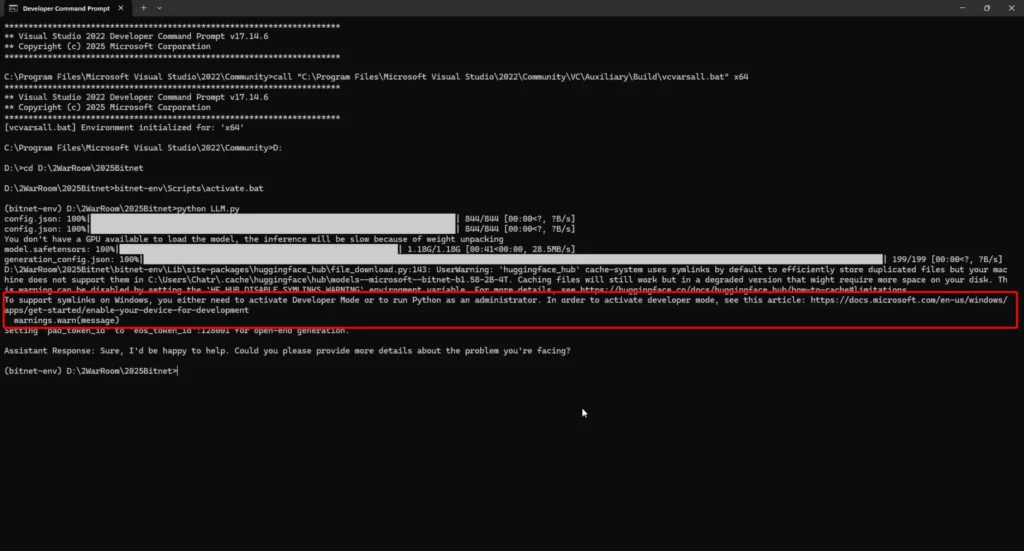
อีก version จริงๆเติม Loop ไป และให้วนถามไปเรื่อยๆ จนกว่าพิมพ์ Thank you BITNET อันนี้ดู Code เต็มๆได้ในนี้
- แบบ API
อันนี้ผมบอกก่อนเลยนะ ว่าไม่ได้ Research ว่ามี Lib อะไรที่ทำได้ ให้ API ของเรา ต่อกัน Open WebUI ได้เลย ตอนแรก ผมลองไปดูก่อนว่า Open WebUI มันรองรับมาตรฐานการเชื่อมต่อแบบไหน ถ้าเป็นส่วน Text Prompt จะมีส่วน OpenAI / Ollama
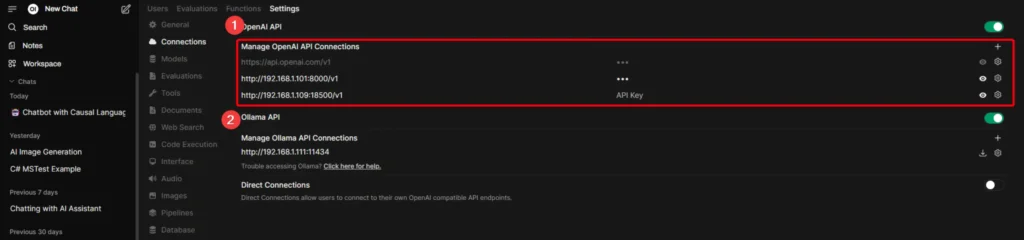
ตอนนี้ผมปักเลือก OpenAI API เพราะที่เคยลองเล่นตัว dotnet semantic kernel มันจะมีแนว /v1/chat/completions เลยลองเริ่มจากตรงนั้น และลอง Add ใน WebUI และดูว่ามันยิง Path ไหนมาที่ Code ของเราครับ
จากที่ลองมาพบว่ามี API 3 เส้นที่น้อยที่สุดที่ Open WebUI ยิงมาขอเรา ครับ ได้แก่
- /v1/chat/completions
- /v1/models
- /health
อย่างของ /v1/chat/completions ผมก็เติมๆ ตามที่มันฟ้อง + ถาม AI จนครบ 3 API ประมาณนี้
import datetime
import time
import uuid
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
from pydantic import BaseModel
from typing import List, Dict, Optional
import torch
import uuid
from datetime import datetime
from transformers import AutoModelForCausalLM, AutoTokenizer
app = FastAPI()
# Load model and tokenizer at startup
model_id = "microsoft/bitnet-b1.58-2B-4T"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
force_download=True,
)
device = "cuda" if torch.cuda.is_available() else "cpu"
model = model.to(device)
class Message(BaseModel):
role: str
content: str
class ChatRequest(BaseModel):
messages: List[Message]
max_new_tokens: Optional[int] = 700
class Choice(BaseModel):
index: int
message: Dict[str, str]
finish_reason: str
class ChatResponse(BaseModel):
id: str
object: str
created: int
model: str
choices: List[Choice]
@app.post("/v1/chat/completions", response_model=ChatResponse)
async def chat_completions(request: ChatRequest):
# Prepare prompt using chat template
prompt = tokenizer.apply_chat_template(
[msg.dict() for msg in request.messages],
tokenize=False,
add_generation_prompt=True
)
chat_input = tokenizer(prompt, return_tensors="pt").to(model.device)
chat_outputs = model.generate(**chat_input, max_new_tokens=request.max_new_tokens)
response = tokenizer.decode(
chat_outputs[0][chat_input['input_ids'].shape[-1]:],
skip_special_tokens=True
)
# Return response in OpenAI-compatible format
# return JSONResponse({
# "id": f"chatcmpl-{uuid.uuid4().hex[:12]}",
# "object": "chat.completion",
# "created": int(time.time()),
# "model": model_id,
# "choices": [
# {
# "index": 0,
# "message": {
# "role": "assistant",
# "content": response
# },
# "finish_reason": "stop"
# }
# ]
# })
return ChatResponse(
id=f"chatcmpl-{uuid.uuid4().hex[:12]}",
object="chat.completion",
created=int(time.time()),
model=model_id,
choices=[
Choice(
index=0,
message={"role": "assistant", "content": response},
finish_reason="stop"
)
]
)
@app.get("/")
def root():
"""Root endpoint with API info"""
return JSONResponse({
"message": "OpenAI-Compatible API for Open WebUI",
"version": "1.0.0",
"endpoints": {
"models": "/v1/models",
"chat": "/v1/chat/completions",
"health": "/health"
}
})
@app.get("/health")
def health_check():
"""Health check endpoint"""
return JSONResponse({"status": "healthy", "timestamp": datetime.now().isoformat()})
@app.get("/v1/models")
def list_models():
"""List available models"""
return JSONResponse({
"data": [
{
"id": model_id,
"object": "model",
"created": datetime.now().isoformat(),
"owned_by": "microsoft",
"permission": []
}
]
})
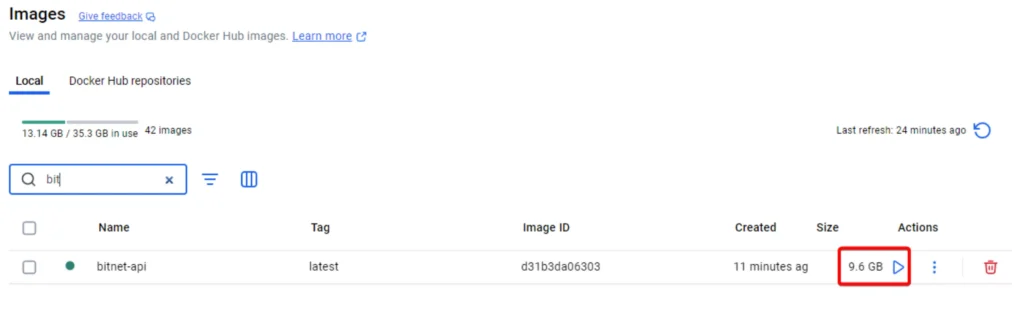
ตอนใช้งานผมทำเป็น Docker ไว้ ตอน Build แอบช็อคกับขนาดเกือบ 10 GB
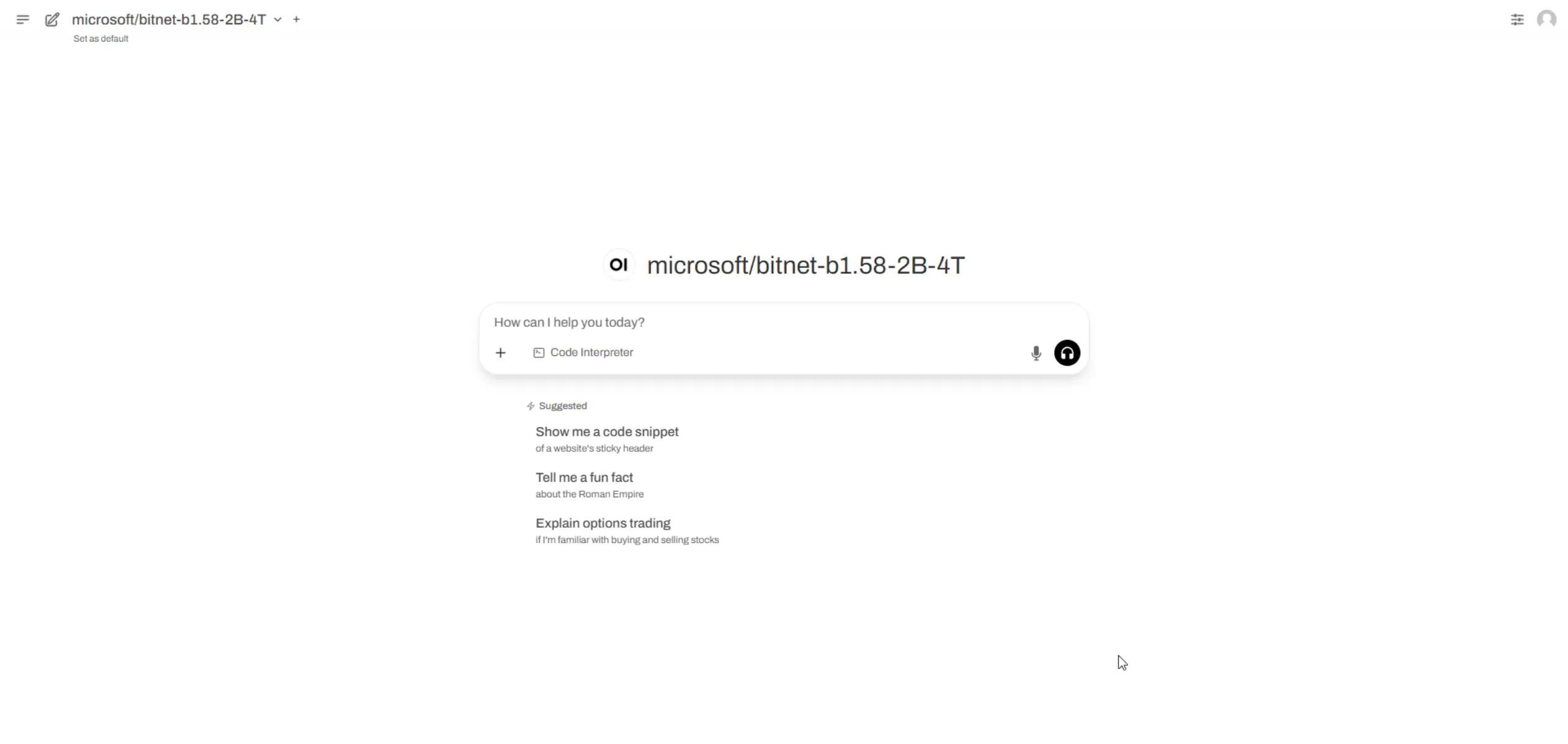
ลองใช้งานจริงและ เชื่อมกับ Open WebUI ลองและตอบโอเคบ้าง มโนบ้าง 5555
แต่ที่แน่ๆ CPU พุ่งครับ 55
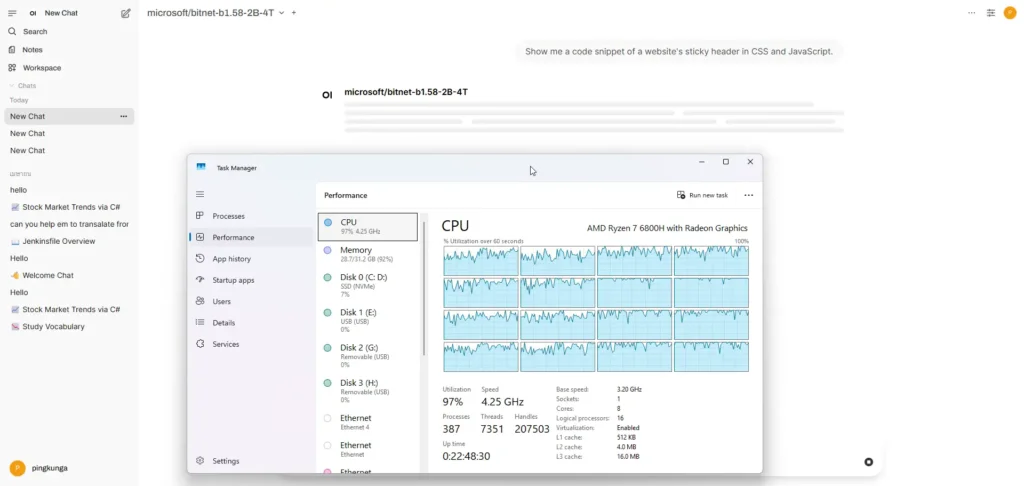
จบการลองแบบงูปลาๆ เอา Model มา Run และ ถ้าเจอที่ดีกว่า เดี๋ยวมาเขียน Blog ต่ออีกทีครับ ทักมาแนะนำได้ครับ อ๋ออย่าฝืนใน Model ใน Windows ของผมมันโดนบีบจาก WSL2 เอา Notebook เก่ามาลง Linux ทำ Local AI Inference Engine ยังไวกว่าครับ
สำหรับ Code ทั้งหมด ผม Up อยู่ใน Git แล้วครับ https://github.com/pingkunga/python_microsoft_bitnet-b1.58_sample
Reference
- https://github.com/microsoft/BitNet
- https://onedollarvps.com/blogs/how-to-run-bitnet-b1-58-locally.html#platform-specific-requirements
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.