
Thai Version (ภาษาไทย): Back to Basic: Fundamental Data Structure in C# (Thai Version)
For this blog, I wrote to share my experience at meetup .NET Developer Day 2025 - Thailand. The inspiration for writing about this topic came from last month when I helped put out fires in the Performance Test section, whose solutions are WEB API / WinApp.
The one root cause of the slow processes was choosing the wrong data structures. There are many examples, but I found people using IList<T> / List<T> in almost every case. If the data is small, you won't notice much difference, but when the data increases from tens to hundreds, thousands, ten thousands, hundred thousands, or millions, the impact becomes very obvious.
Problem
- MoverBox component responds very slowly when selecting a large amount of data"
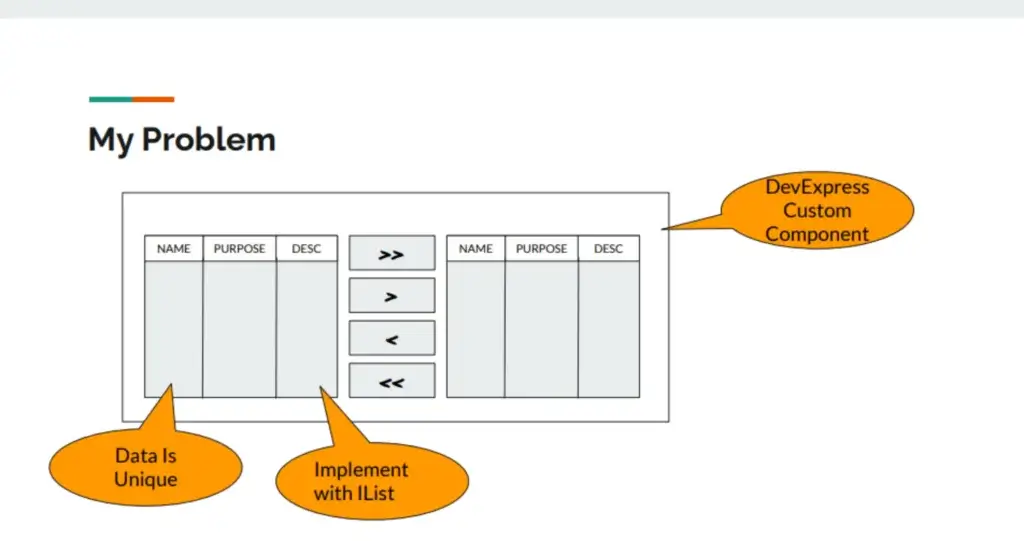
This MoverBox component that helps select large amounts of data, made from DevExpress, has been around for a long time, probably more than 10 years. It includes:
- Grid Source / Grid Destination where users can use the Grid Filter feature to filter data
- >> / << buttons to select all data to move to Source / Destination
- > / < buttons to select some data to move to Source / Destination
- Data in the Grid is always unique
- The Data Structure used is List<T>
- Various processes significantly increase when data is increase
In the loop, besides 'for', there's also 'Where' or 'FirstOrDefault' searching in the List. The example would look something like this:
public static void ProcessTransactionWithOnlyList(IList<TransactionDTO> pTransactions, IList<PortfolioDTO> pPortfolios, IList<PortPriceSouceDTO> pPortPriceSources)
{
// Iterate through transactions and find corresponding portfolio
foreach (var transaction in pTransactions)
{
// Use LINQ to find the portfolio with the matching PortfolioId
var portfolio = pPortfolios.FirstOrDefault(p => p.PortfolioId == transaction.PortfolioId);
if (portfolio != null)
{
// You can save or process the transaction with the portfolio here
//....
}
var portPriceSource = pPortPriceSources.FirstOrDefault(p => p.PortfolioId == transaction.PortfolioId);
if (portPriceSource != null)
{
// You can save or process the transaction with the portfolio here
//....
}
}
}
Recap Data Structure
I'm not sure if others have encountered the same issue, but I've found people who use List instead of every other data structure(List Lover).
Let's review Data Structure + Big O.
- What is Data Structure + Big O
For me, it's a way to organize information to Add/Retrieve/Remove/Search efficiently—simply put, it's a method of managing data. There are good collections available to choose from. Each operation (Add/Retrieve/Remove/Search) has a measurement method called Big O.
You don't need to memorize , just remember that O(1) is good, but O(n) is ok but O(n²), which involve multiple nested loops, are not good
- C# Data Structure
There are many types, as shown in the image.
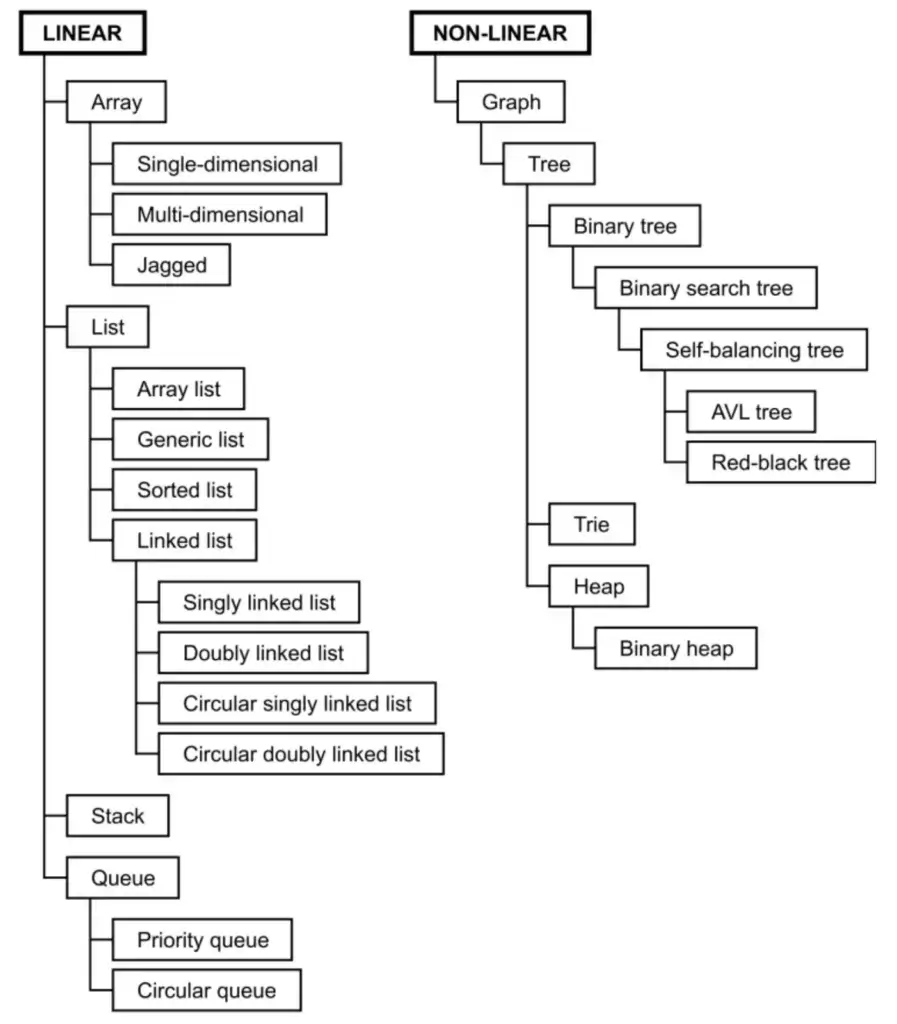
I don't use all of them. Mainly I use List / Dictionary / Queue / HashSet.
- Lists (List<T>)
Use Case:
- Used in cases where you need to keep storing data but don't know the size (dynamic size)
- Simple and can be used in many different ways/use cases
Note: Array Fixed Size
Big O Complexity:
- Access: O(1)
- Search: O(n)
- Insert: O(n) (O(1) if adding at the end)
- Delete: O(n)
Sample Code:
🚅 https://dotnetfiddle.net/CeShV4
🚅 https://dotnetfiddle.net/EN9v51 (C# Built-In InsertRange For inserting on specific position)
- Dictionary<TKey, TValue>
Use Case:
- Use in case you need to store data in key/value format (use key to find a value)
- Simple Caching / Lookup / Count Freq
Big O Complexity:
- Access: O(1)
- Search: O(1)
- Insert: O(1)
- Delete: O(1)
Sample Code:
🚅 https://dotnetfiddle.net/fjmgK1
Actually, a common problem is using List incorrectly such as
list.where( x => x.yourkey)orlist.FirstOrDefault( x => x.yourkey)If you need to do lookups, convert the data into a Dictionary (key/value) format. This approach can help reduce the cost from Search: O(n) to Search: O(1)
- HashSet<T>
Use Case:
- Used in cases where you need to store unique data (not duplicated), such as when you need non-duplicated data in a lookup
- Don't forget to implement Equals / GetHashCode
Big O Complexity:
- Access: O(1)
- Search: O(1)
- Insert: O(1)
- Delete: O(1)
Sample Code:
🚅 https://dotnetfiddle.net/KjkiPn
- Stack<T> & Queue<T>
Use Case:
- Stacks - Last-In-First-Out (LIFO) sample use case
- Undo/Redo operation
- Syntaxes / Expression Parsing - check html tags - Queues ใFirst-In-First-Out (FIFO) with order sample use case
- Simple Message Queue
- Job scheduling with/without priority
Big O Complexity:
- Access: O(n)
- Search: O(n)
- Insert: O(1) Enqueue / Push
- Delete: O(1) Deque / Pop
Sample Code:
🚅 https://dotnetfiddle.net/5R2eAo (Stack)
🚅 https://dotnetfiddle.net/lPcTST (Queue)
from my blog List / Dictionary / Hash / Stack / Queue is only little sample because in .NET there are many types of data structures, such as:
- System.Collections for Basic Type int string ….
- System.Collections.Generic for Generic Such as . Object / DTO
- System.Collections.Concurrent for multiple threads are accessing (Thread-Safe) such as ConcurrentBag / ConcurrentDicionary / ConcurrentQueue
For generics and various DTOs, don't forget to implement Equals/GetHashCode. If you want to know what this is, you can check out this blog (Written in Thai). It will provide methods to determine what makes an object unique.
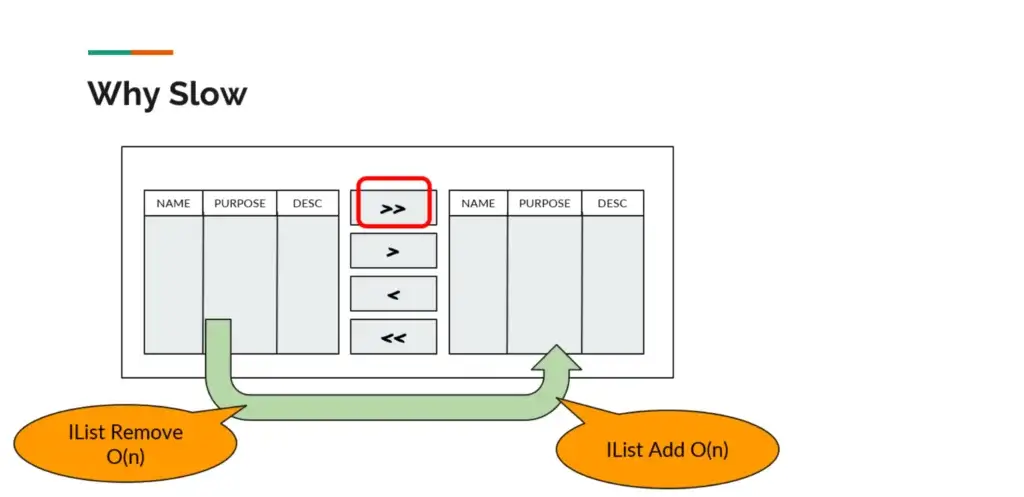
Solution
- MoverBox component responds very slowly when selecting a large amount of data"
Previously IList<T> was a solution to store data on the Source/Desc side. At now I changed the data structure to HashSet<T> because the data in MoverBox is already unique and i want fast access when move from Source/Desc side
Sample Code: https://dotnetfiddle.net/MrFiYg (List vs Hash Map)
Apart from choosing the right data structure, there's also the step of calling 3rd party APIs. The Code call these API frequently, in this case DevExpress, which creates latency. If possible, fetch everything at once first, then process and pick what you need in one time.
- Old Code
int[] sourceIndex = new int[this._sourceGridView.SelectedRowsCount];
for (int row = this._sourceGridView.SelectedRowsCount - 1; row >= 0; row--){
if (_sourceGridView.GetSelectedRows()[row] >= 0){
sourceIndex[row] = this._sourceGridView.GetDataSourceRowIndex(this._sourceGridView.GetSelectedRows()[row]);
}
else{
sourceIndex[row] = this._sourceGridView.GetSelectedRows()[row];
}
}
- New Code - After Apply Solution. Data of tens of thousands of records in the Grid that previously took 2-3 minutes to load now takes just a moment.
int[] selectedRows = this._sourceGridView.GetSelectedRows();
int[] sourceIndex = new int[selectedRows.Length];
for (int row = 0; row < selectedRows.Length; row++){
if (selectedRows[row] >= 0){
sourceIndex[row] = this._sourceGridView.GetDataSourceRowIndex(selectedRows[row]);
}
else{
sourceIndex[row] = selectedRows[row];
}
}
while the performance improvement is good, the current approach is still just a workaround. Because having hundreds of thousands or millions of records to select from one by one is still strange. I suggest that UX/UI + Business Flow for improve as the next step to address this issue.
- Various processes significantly increase when data is increase
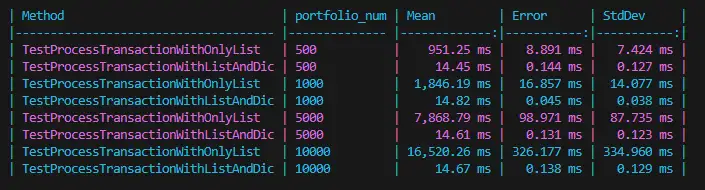
The solution attempts to preprocess the data first. For anything that's like a lookup, put it into a dictionary before entering the loop.
public static void ProcessTransactionWithListAndDic(IList<TransactionDTO> pTransactions, IDictionary<int, PortfolioDTO> pPortDic, IDictionary<int, PortPriceSouceDTO> pPortPriceSourceDic)
{
foreach (var transaction in pTransactions)
{
var portfolio = pPortDic.ContainsKey(transaction.PortfolioId) ? pPortDic[transaction.PortfolioId] : null;
if (portfolio != null)
{
// You can save or process the transaction with the portfolio here
//....
}
var portPriceSource = pPortPriceSourceDic.ContainsKey(transaction.PortfolioId) ? pPortPriceSourceDic[transaction.PortfolioId] : null;
if (portPriceSource != null)
{
// You can save or process the transaction with the portfolio here
//....
}
}
}
Sample Code: https://dotnetfiddle.net/h07dZg
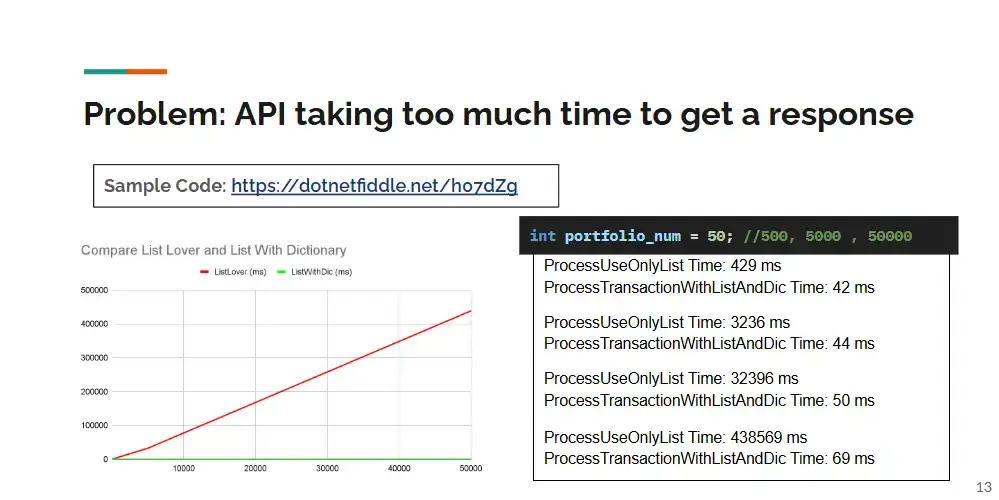
And the case list lover , I encounter frequently.
Summary
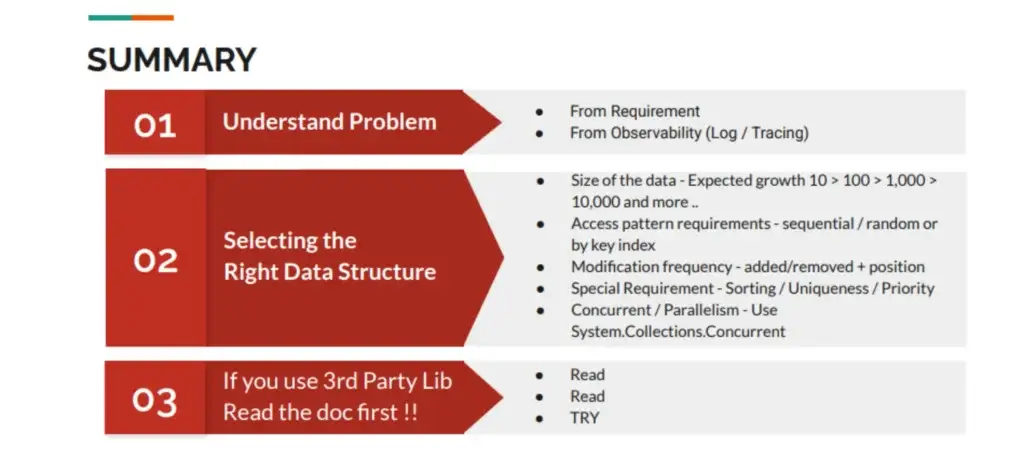
- You need to understand the problem first. In my case, before discovering the issue, everyone thought it was because of insufficient vCPU allocation or inadequate database indexing that needed to be increased. But actually, it came from the code. I knew this because I added observability (Tracing) to every method until I noticed something strange.
- Choose data structures appropriate for the task. Consider Size / Access Pattern / Frequency of modifications / whether it works with Single Thread or Multi-Thread, as well as other constraints.
- Before using anything, read the documentation first ^__^
Choosing the right Data Structure + Algorithm is a good starting point to prevent performance problems in our system. But there are many other components as well, such as Architecture Design / Database Schema Design / Your Logic like Algorithm, Business logic, Sorting / and the SQL you write!!!!!
My summary table of approaches for selecting Data Structures

| Data Structure | Best For | Avoid When | Key Strength | Key Weakness |
|---|---|---|---|---|
| Array | Fixed-size, direct indexing | Frequent size changes | Fast access | Fixed size |
| List | Dynamic collection with index access | Many inserts in middle | Flexible size | Middle insertions |
| Dictionary | Key-value lookups | Ordered data needed | Fast lookups | No ordering |
| LinkedList | Frequent inserts/deletes | Random access needed | Fast modifications | Slow lookups |
| Stack | LIFO processing | Random access needed | Simple model | Limited access pattern |
| Queue | FIFO processing | Random access needed | Simple model | Limited access pattern |
| HashSet | Unique item collection | Ordering needed | Fast lookups | No duplicates |
| SortedDictionary | Ordered key-value pairs | Huge collections with frequent changes | Ordered + lookup | Slower than Dictionary |
| SortedSet | Ordered unique items | Many duplicates needed | Ordered uniqueness | Slower than HashSet |
| PriorityQueue | Priority-based processing | FIFO/LIFO needed | Priority handling | Complex interface |
Resource: Slide / Source Code
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.

