Describe high availability and disaster recovery strategies
- Identify the availability requirements of Azure resources
- High Availability คือ อะไร การทำให้ระบบมันยืดหยุ่น (Resilient) ในเคส Component Failure หรือ ระบบไม่มี Downtime ขึ้นตอนเกิดปัญหา
- Azure มี Local (LRS) ใน DC/ Zone (ZRS) ใน Region / GEO-(GRS) - Multi-Region
- Key กำหนด SLAs สำหรับ workload แต่ละชิ้น + time windows (ระยะเวลาพร้อมให้บริการ)
- หลังจากได้ SLA มา Consider cost and complexity
- หาว่าอะไรที่ Resource ใน Flow ไหน Critical จริงๆ >> เพิ่ม Cost และอะไรที่ยอม Down ได้ >> ลด Cost
- 99.99% ยิ้ง 9 เยอะ มันแก้ปัญหาแบบ Manual ไม่ต้อง ระบบต้อง self-diagnosing + self-healing
- ดู Metric
-> Mean time to recover (MTTR) //RTA - average time it takes to restore a component after a failure.
-> Mean time between failures (MTBF) - how long a component can reasonably expect to last between outages. (เวลาที่เฉลี่ย Component Fail เช่น ระบบทำงานได้ 13 ชั่วโมง / Fail 3 ครั้ง รวม 1 ชั่วโมง ดังนี้ (13-1)/3 = 4
และคุยกับลูกค้าให้ชัด และบันทึก SLA ไว้
พวก Metric ดูจาก RPO และ RTO คือ อะไร และสัมพันธ์กับ Disaster Recovery อย่างไร เพิ่มได้ - คำถามต่างๆที่ช่วงให้ SLA ชัด
- What are the availability requirements?
- How much downtime is acceptable?
- How much will potential downtime cost your business? //Down เท่าไหร่ที่กระทบธุรกิจ
- How much should you invest in making the application highly available?
- What are the data backup requirements?
- What are the data replication requirements?
- What are the monitoring requirements?
- Does your application have specific latency requirements? - หลาย Component มีคิด Composite SLA ด้วย ดูเพิ่ม
- Business Metrics
- Reliability design principles - Multi-Region - ทำไม ?
- ลด Latency ลงจากการ Access Global
- เน้น business continuity and disaster recovery (BCDR)
- Explore high availability and disaster recovery options
มันต้องย้อนกลับไปในส่วน Share Responsibility ถ้า
- IAAS - เราต้องดู VM (Feature เลือก) + Service ในนั้นด้วยนะ เช่น DB ต้อง DBA ต้องมา implement solution เอง
- PAAS - พวก Service ต่าง เช่น DB มันจะเป็น Feature มาให้กดเสียเงินและ
- SAAS - เราเป็น User นี่ หน้าที่นี้เป็นของผู้ให้บริการนะ
แล้วที่นี้ แต่ละตัวมีอะไรบ้างนะ เอาที่เด่น
- Azure VM (IAAS) แต่อย่างลืมว่ามันระดับ VM พวก App ข้างใน DB มันไม่รู้นะ
- Availability sets - ใน DC เดียวกัน ต้องสน Fault domains (ของเราพัง) / Update domains (รอบ MA ของ Azure) ที่ต้องกำหนด เพราะ เราจะได้มั่นใจว่า VM ของเรา ตัวหลัก สำรอง มันไม่บังเอิญไป Run ที่ Physical เดียวกัน (Server / Network / Power Source เดียวกัน)
- Availability zones - คนละ DC ใน region เดียวกัน
- Azure Site Recovery ข้าม region ไปเลย - Azure VM - SQL Server HADR Features - เลือก Azure VM (IAAS) Solution อาจจะต้องคิดถึง Latency ด้วย
- Always On Failover Cluster Instance (FCI) [Instance Level]
- Always On Availability Group (AG) [Database Level]
- Log Shipping [Database Level]
- Explore an IaaS high availability and disaster recovery solution
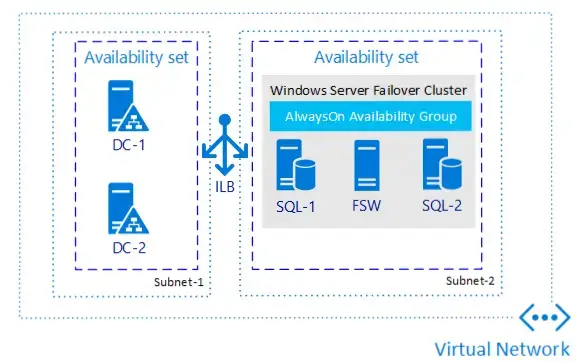
- Single Region High Availability Example 1 – Always On availability groups
- easy, standardized method for applications to access - primary / secondary เปิด read ได้
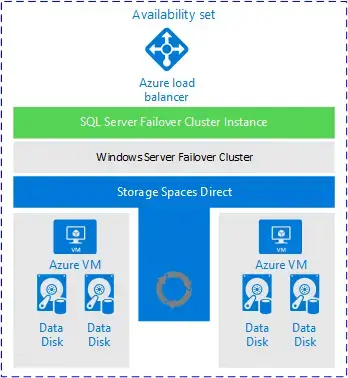
- enhanced availability during patching scenarios. - Single Region High Availability Example 2 – Always On Failover Cluster Instance
- required shared storage (Azure Shared Disk)
- App เข้าง่าย ไปอ้างอิงผ่าน Cluster
- provides enhanced availability during patching scenarios.
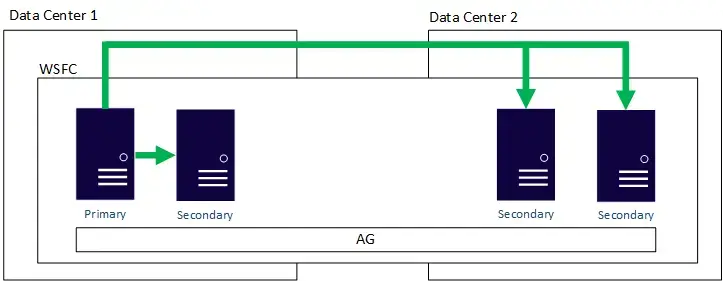
- Disaster Recovery Example 1 – Multi-Region or Hybrid Always On availability group
- This architecture would require AD DS and DNS to be available in every region and on-premises
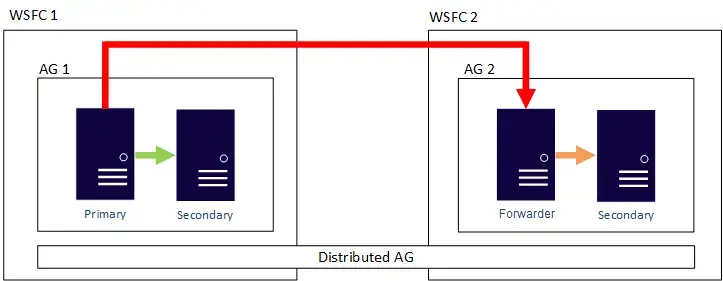
- HA + DR Support - Disaster Recovery Example 2 – Distributed availability group
- This architecture makes it easier to deal with things like quorum since each cluster would maintain its own quorum, meaning it also has its own witness. A distributed AG would work whether you are using Azure for all resources, or if you are using a hybrid architecture.
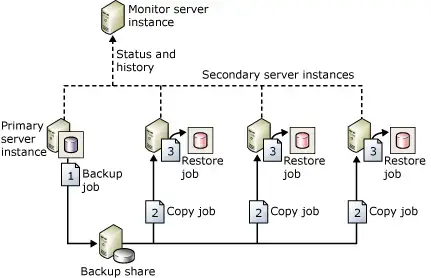
- Disaster Recovery Example 3 – Log shipping แบบ Classic เหมาะกับเคส Network ไม่เสถียรด้วย
- Disaster Recovery Example 4 – Azure Site Recovery - อันนี้ไม่ใช้ Solution ของ Database แล้ว ทำที่ Infra เลย แต่ต้อง Sync ตลอด
NOTE: จริงๆ SQL Server มัน Solution อื่นๆนะ แต่ Azure ไม่ได้รองรับแบบ Official เช่น Database Mirroing
Read More: Explore an IaaS high availability and disaster recovery solution
- Describe high availability and disaster recovery options for PaaS deployments
- Azure SQL
| Service | SLA | active geo-replication | autofailover groups |
|---|---|---|---|
| Azure SQL Database | 99.995% | ✅ | ✅ |
| Azure SQL Database Managed Instance | 99.99% | ❌ | ✅ |
ปกติตัวอื่นๆ นอกจากจะได้ SLA 99.99%
- Azure Database for MySQL มีแบบ Single (แต่จะ retired ปีนี้) / Flexible (Node)
- Azure Database for PostgreSQL มีแบบ Single / Flexible (Node) จากตัว Citus
From an application standpoint, you will need to code the necessary retry logic because all connections are dropped as part of spinning up the new node and any in flight transactions are lost
นอกจากนี้แล้ว Solution เดียวไม่เหมาะนะ อาจจะต้องพิจารณา Hybrid ตามงบ จากตัวอย่างเห็นทำ Azure Iaas แล้ว ยังต้องมาดู Service อื่นๆ เช่น DB ทำ HA เพิ่มด้วย
Knowledge check: Describe high availability and disaster recovery strategies
Design for high availability (หัวข้อเก่าของ AZ-305 นะ)
หัวข้อเก่าของ AZ-305 นะ เขียนดองไว้แบบนี้ พอจะสอบหัวข้อหาย 55 แต่จดไปแล้ว ก็ไม่อยากลบอ่านะเสียกด
- Design for Azure Front Door
- Azure Front Door เป็น Service ที่ช่วยจัด Traffic + Caching เอาจริงๆ ตอนแรกที่อ่านสงสัยว่ามันต่างกับ Application Gateway ยังไง เลยลองหาดู
- Azure Front Door - Region Fail / Reverse Proxy + WAF / require SSL offload
- Application Gateway - DC Fail + Scale Set
Ref Azure Front Door - Frequently asked questions
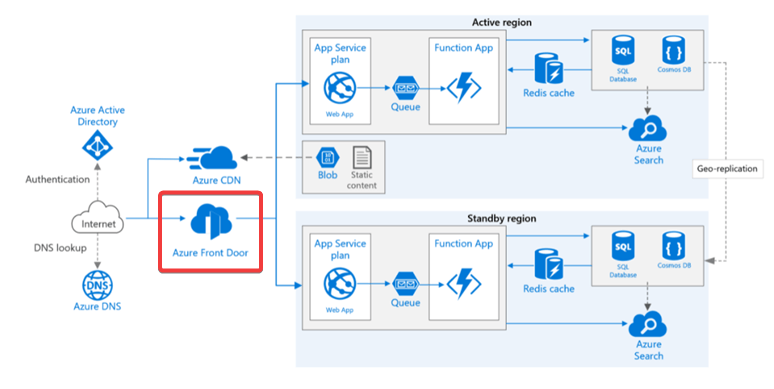
- Azure Front Door Mode //Cost License จะต่างกัน
- Active/passive with cold standby - Traffic เข้า Region เดียว
- Active/passive with hot standby - Traffic เข้า Region เดียว + Resource ทำงานหมด
- Active/Active - load balanced ของแต่ละ Set
- Design for Azure Traffic Manager
- Azure Traffic Manager a DNS-based traffic load balancer //เคยเล่นตอน AZ-400 ใช้ทำ Deployment
- แล้วมันต่างกับ Azure Front Door ยังไง ?
- มันอยู่ Level เดียวกันนะ Layer 7 Application Layer Load balancer
- DNS-based (DNS Lookup) และไม่มี Caching แบบ Front Door
- ดูเพิ่มได้
-> It is Azure Traffic Manager or Azure front Door in-front for multi region system architecture? - Stack Overflow
-> Difference between Azure Front Door Service and Traffic Manager (iamashishsharma.com) - High availability scenarios
- Active/Passive with cold standby - cost-effective เพราะฝั่ง Standby ปิดอยู่ แต่ failover นานขึ้น
- Active/Passive with pilot light - ฝั่ง standby บาง resource run อยู่ (critical solution) เช่น พวก DB
- Active/Passive with warm standby - ฝั่ง standby เปิดอยู่ / Auto scaling ได้
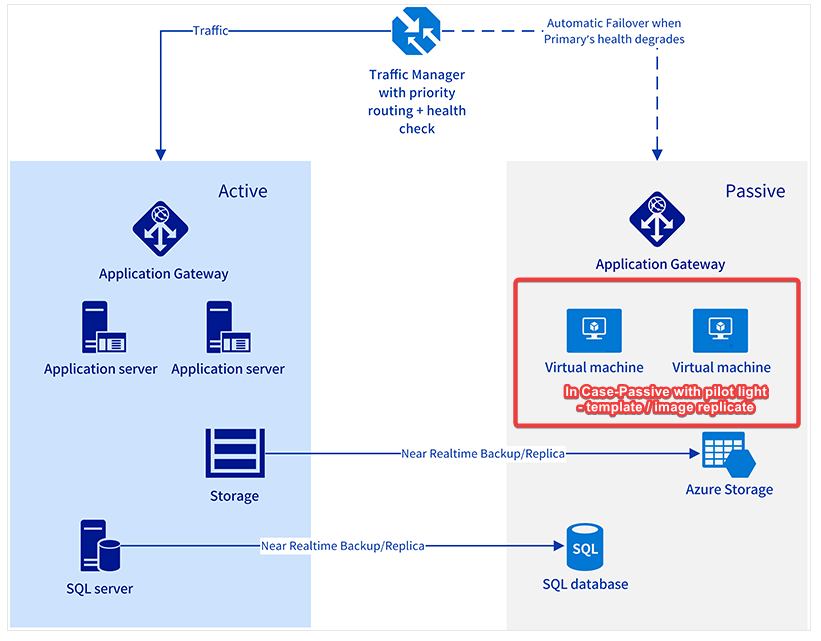
Recommend a high availability solution for compute
Azure Availability Zone
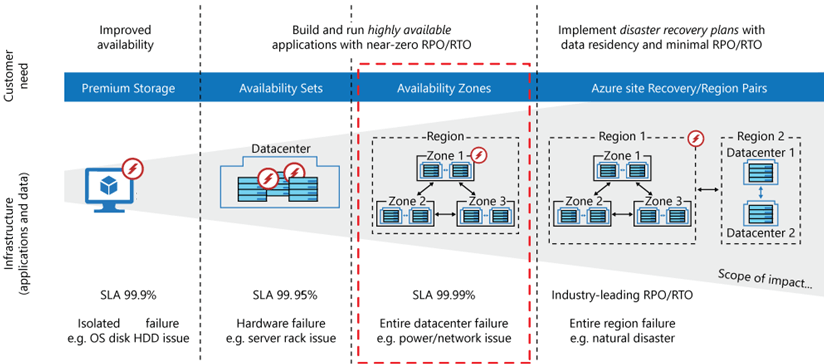
- VM Availability Set - SLA 99.95% โดยScenario ที่ใช้งาน Availability Set
-> add VM instances for changing workload
-> balance and distribute workloads
-> high availability and redundancy
-> monitor and then scale VM - Availability Zones - Zone Fail SLA 99.99% นอกจาก VM แล้วมีอื่นๆด้วย
- Design a highly available container solution
- ปกติ K8S มันมี Self-Healing ระดับนึงนะ AKS ได้มาด้วย ในเคสนี้ จะคุยถึง Cluster ใน Region Fail โดยมีสิ่งที่ต้องสนใจ ดังนี้
- AKS region availability - เอาใกล้กับเรา เมื่อไหร่จะมี BKK 55
- Azure paired regions กำหนด Pair Region สำหรับเคส Plan Maintenance และต้องดูด้วยว่า Pair ให้ availability แบบไหน hot/hot, hot/warm, or hot/cold
Describe Azure Storage replication options - ถ้าเรา Deploy AKS + multiple regions
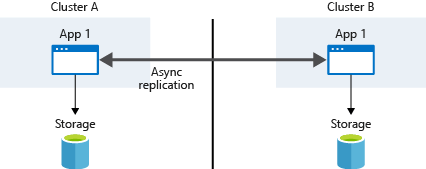
- Infrastructure-based asynchronous replication
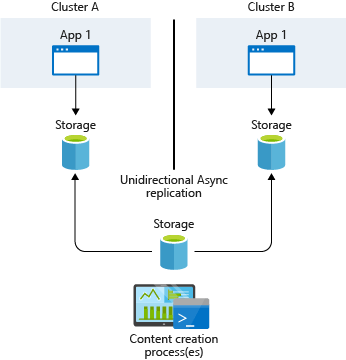
- Application-based asynchronous replication ให้ App ทำเขียนเองก็ได้ หรือเอา Tools ที่มีมาใช้ตัว Tools มี Azure Backup / Velero (backup volumes + resource + config)
- Storage อย่าง Azure Disk มีเรื่อง Snapshot ด้วยนะ
- Note Velero นอกจาก Backup ยังทำเรือง Migration ได้ด้วยนะ
- Recommend a high-availability solution for relational data storage
- relational นึกถึงตัว database โดยมันจมี Model ของ Cost 2 แบบ
- vCPU - แยก Cost Compute / Storage
- DTU(Database Transaction Unit) - เหมา Compute + Storage
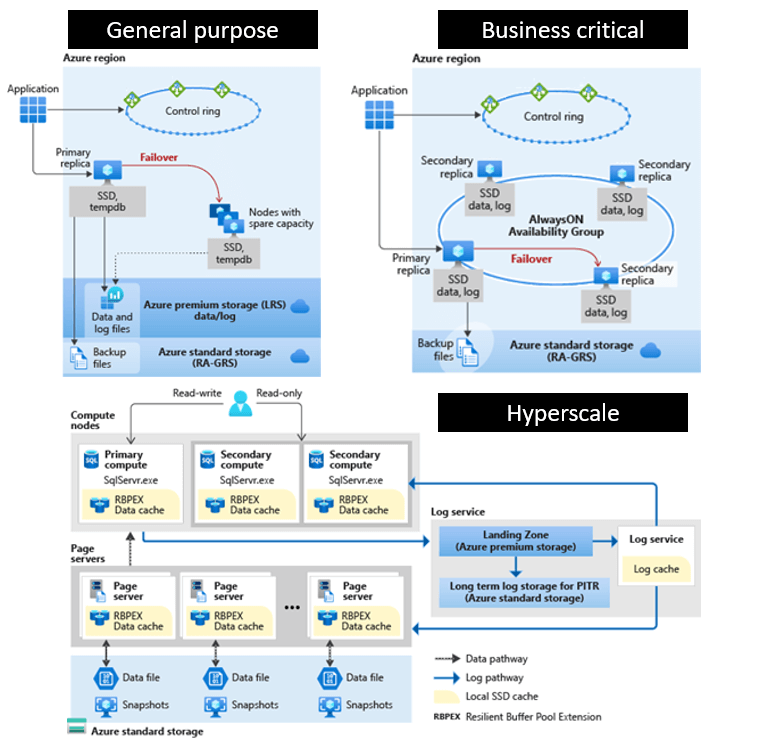
- service tiers
- General purpose
- Business critical - need low latency and minimal downtime. ใช้ Storage แบบ Direct Access ลด Latency / ทำ Always On availability group (AG) และ Read scale-out
- Hyperscale - Azure SQL Database Only เน้น tiered layer of caches and page servers ทำให้ access ได้เร็วขึ้น
Database service tiers for availability
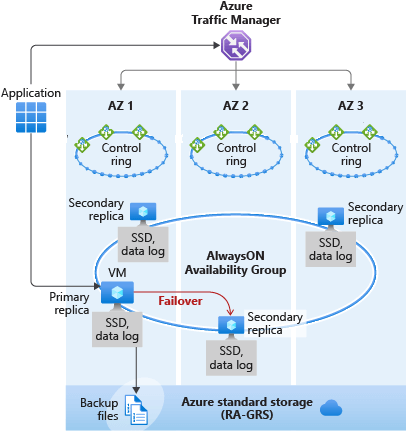
- Database service tiers for availability
- Availability Zones + Always On availability group (AG) - no additional fee) for a zone-redundant เพิ่ม SLA ตาม replicas 0 = 99.5% / 1 = 99.9% และ 2++ = 99.99%
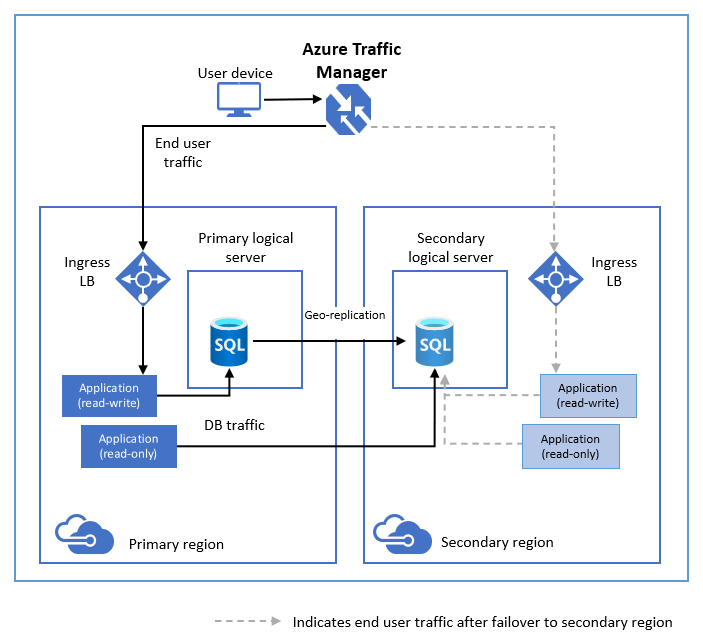
- What is active geo-replication?
- replicate ไปในหลายๆ Region 1 Write N Read รองรับทั้ง Azure SQL และ CosmosDB"
- Feature:
-> Automatic Asynchronous Replication
-> Readable secondary databases
-> Planned failover
-> Unplanned failover
-> Multiple readable secondaries
-> Geo-replication of databases in an elastic pool - can fail over to a secondary database if your primary database fails or needs to be taken offline.
-> User-controlled failover and failback อันนี้น่าจะชอบ ตอนซ้อมย้าย DC/DR 555
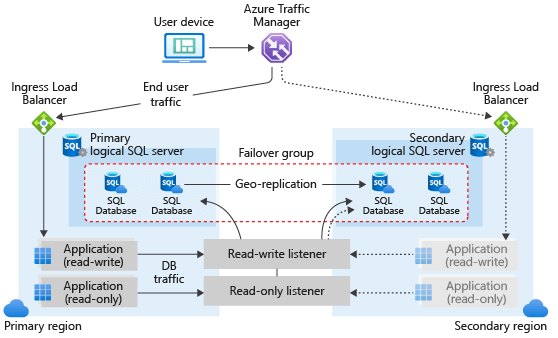
- What are auto-failover groups?
- สำหรับ Azure SQL Managed Instance สำหรับ 1 App หลาย DB
- หรือ requires a stable connection endpoint and automatic geo-failover support
- Feature: Automatic failover policy / Planned failover / Unplanned failover / Unplanned failover / Manual failover - ระหว่าง geo-replication / auto-failover groups เลือกยังไง ?
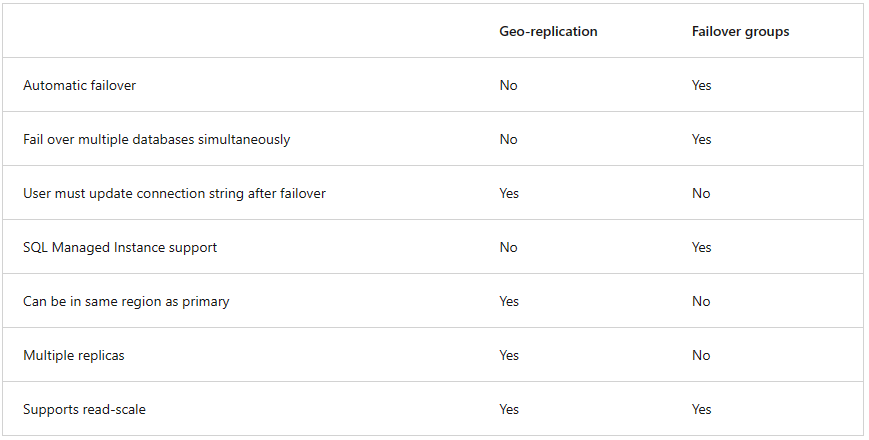
- Recommend a high-availability solution for non-relational data storage
- AZ-900 - Azure Storage Redundancy
- Summary of storage redundancy options
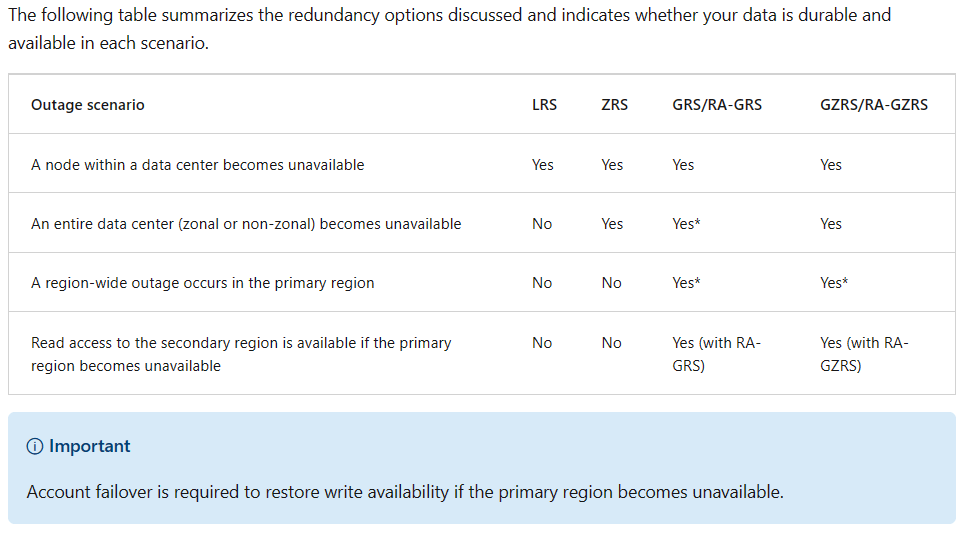
- which redundancy option is best - Tradeoffs lower costs vs higher availability
- primary เพียงพอไหม
- geographically distant
- second region ต้อง read ได้ด้วยไหม - Data Lake Storage redundancy (built on top of Azure Blob Storage)
- ดูจาก throughput / IOPS (input/output operations per second)
- ส่วน redundancy option เหมือน Blob มันมองต่างมุมกัน ตามตาราง

Knowledge check: Design for high availability
Design a solution for backup and disaster recovery
- Design for backup and recovery
- Reliable apps - Resilient (ทนกับ) to component failure / Highly available with no significant downtime. การที่เราจะได้ Reliable apps key requirements มาจาก Business Need
Guidance to Build your resiliency plan
- What are your workloads and their usage?
- What are the usage patterns for your workloads?
- หาช่วงเวลา critical/non-critical periods - What are the availability metrics?
- mean time to recovery (MTTR) - average time it takes to restore a component after a failure
- mean time between failures (MTBF) - how long a component can reasonably expect to last between outages - What are the recovery metrics?
- recovery time objective (RTO)
- recovery point objective (RPO)
- recovery level objective (RLO) - ถ้าระบบมันตุ้ยขึ้นมาจริงๆ อะไรที่สำคัญกับต้อง Recover ขึ้นมา ตรงนี้ต้องดูจากการทำ Risk Assessment เทียบ Cost / Risk กับ Data Loss - What are the workload availability targets?
- define target SLAs for each workload และทำให้เหมาะกับ Cost / complexity of meeting availability requirements - What are your SLAs?
- บาง Service Composite SLA ถ้า A=99.9% + B=99.99% SLA มันไม่ได้ 99.99% นะ ต้องไปทำบางอย่างที่ A เพิ่ม
- Design for Azure Backup
Azure Backup service เป็น Service ที่มาช่วยปกป้อง Data ไม่ให้หายไป โดยรองรับได้หลายแบบ ถ้าใน On-premise เดิม จะเป็น Backup Server + Tape โดยรูปแบบตามตารางเลย
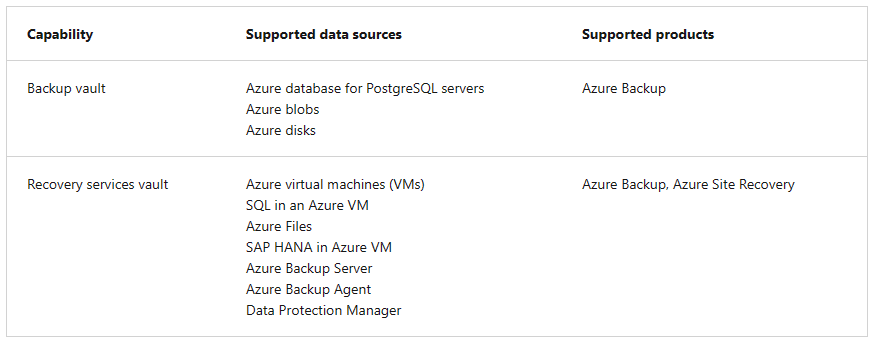
- สิ่งที่ต้องพิจารณาตอน Design Azure Backup
- how to organize the vaults / separate vaults for Azure Backup and Azure Site Recovery ตาม subscription หรือปรับตาม Cost
- ใช้ Azure policy มาทำให้ Policy ล้อกันทั้งองค์กร
- ใช้ Azure role-based access control (RBAC)
- Design for Redundancy - เคส Storage LRS / ZRS และ GRS - ตอนเขียนเจอเพิ่มมา เอา Ref ดูเพิ่มได้ WT Blog (ITGeist): Azure Backup-Immutable Vault (itgeist5blog.blogspot.com)
- Design for Azure blob backup and recovery
Operational backup for blobs is a local backup solution มันจัดการเอง เราไม่ต้องยุ่งอะไรเลย โดยการใช้งานมี 2 แบบ
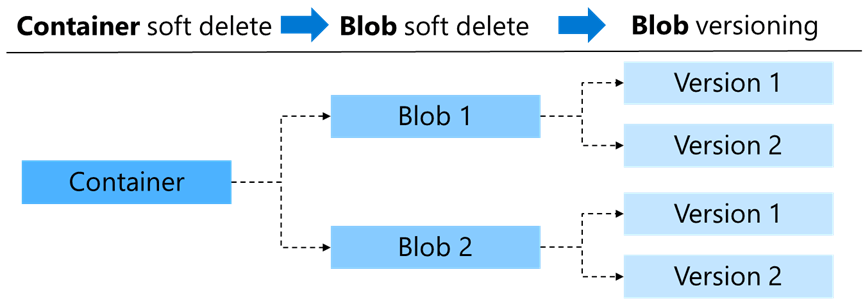
- Point-in-time restore โดยเราจะใช้ตัว soft delete and versioning มาช่วยในการ Restore
ทั้งตัว Container soft delete / Blob soft delete / Blob versioning
ดูเพิ่ม Point-in-time restore for block blobs - Azure Storage

- Resource locks กำนหดที่ตัว Resource มี 2 แบบ CanNotDelete / ReadOnly
- Design for Azure files backup and recovery
Azure Files provides the capability to take share snapshots of file shares
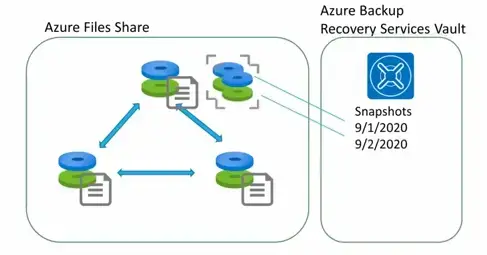
- Share snapshots - CRD แต่แก้ไม่ได้ / point in time / snap root level ของ file-share ลงไป / incremental (ถ้าเลือกตัวล่าสุด มันไป replay แต่ละอันมาจนครบ)
Backup: Manual กดเอา หรือ Code / Automate ต้องใช้ Azure Backup + backup policies
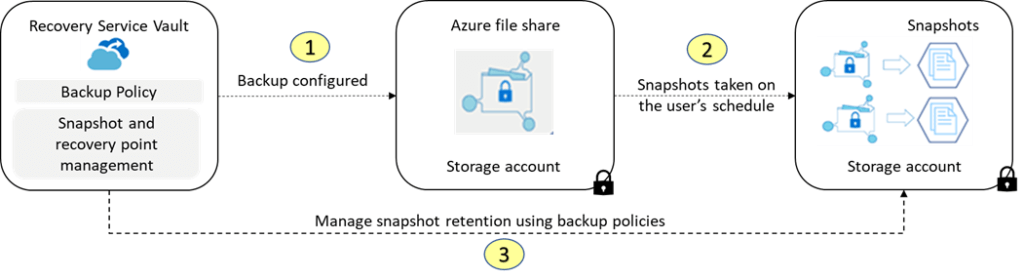
- สิ่งที่ต้องพิจารณาตอน Design file backup
- Use instant restore
- Implement alerting and reporting แจ้งเคสที่มีปัญหา
- self-service restore - ลดภาระ Admin
- on-demand backups - ให้กดเองได้ เพราะ Azure Backup Policies กำหนดได้ วันละรอบ
- Organize file shares for backup - แยก Share ให้เหมาะสมตามกลุ่ม
- Snapshot before code deployments - ระวัง Bug ทำข้อมูลหาย
- Design for Azure virtual machine backup and recovery
- Azure VM ใช้ Azure Backup มาจัดการ VM โดยมี 2 Step
1. ทำ Snapshot
2. The snapshot is transferred to the Azure Recovery Services vault. - Snapshot backups support different levels of consistency, including Application, System, and Crash.
- backups
- VM backups - encrypted at rest with Storage Service Encryption (SSE)
- Azure Backup - เก็บ VM Azure Disk Encryption - สิ่งที่ต้องพิจารณาตอน Design file backup
- Identify the best backup schedule - เลือก non-peak time
- Determine backup frequency - scheduled backup permits only one backup per day
- Create backup policies - จะอาจจะแยก Zone VM critical / non-critical
- Monitor and review your plan
- Practice restoring from backup - Time Restore ขึ้นกับ IOPS + throughput ของ storage account.
- Consider throttling - ตอน Access Storage Account จะมี throttling limit ไว้ ถ้าต้องการ Restore VM คู่กับ Storage Account 1 ต่อ 1 ที่ไม่ใช่ให้กับ Resource อื่นๆจะดีสุด
- Consider Cross Region Restore (CRR) - restore resource in a secondary region
- Design for Azure SQL backup and recovery
- automated backups ของ Azure SQL Database / SQL Managed Instance ใช้ของ SQL Server เดิมๆที่มี
- full backups every week
- differential backups every 12-24 hours
- transaction log backups every 5 to 10 minutes //ขึ้นกับขนาด Compute
ตอน Restore Azure มันช่วยเลือกเอง - backup usage cases
- Restore an existing database to a point in time in the past
- Restore a deleted database to the time of deletion - only on the same server or managed instance
- Restore a database to another geographic region - recover from a geographic disaster กรณีที่ต่อ Primary Region ไม่ได้
- Restore a database from a specific long-term backup - Azure SQL Database automatic backups เก็บไว้ 35 days แต่ถ้าต้องการนานกว่านั้นตาม Policy / Regulator ต้องทำ long-term retention (LTR) feature ที่ยาวสุด 10 ปี
- Design for Azure Site Recovery
- Azure Site Recovery is a service that provides BCDR ทั้ง Azure / Hybrid Cloud / Multi-Cloud
- Azure Site Recovery Capabilities
- Simple BCDR solution
- Azure VM replication
- On-premises VM replication
- Workload replication
- Data resilience
- RTO and RPO targets
- Keep apps consistent over failover
- Testing without disruption
- Flexible failovers
- Customized recovery plans
- BCDR integration
- Azure Automation integration
Azure Site Recovery with Azure Backup
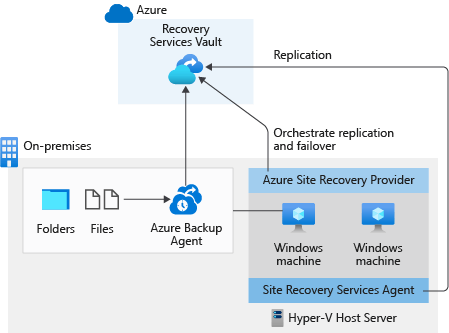
- เอามาใช้ HA Solution ได้
- Azure Backup - Backup periodically files and folders
- Azure Site Recovery - replicate VM กรณีที่พบว่ามันหยุดทำงาน ช่วย RTO ลดลง
Knowledge check: Design a solution for backup and disaster recovery
Reference
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.