สำหรับหัวข้อที่จดๆไว้มี ดังนี้ครับ
Create an Azure AI Search solution
- Manage capacity
Service tiers and capacity management
- Free (F)
- Basic (B) 15 indexes and 2 GB
- Standard (S)
S1-S3 เพิ่ม indexes + storage
S3HD, which is optimized for fast read performance on smaller numbers of indexes.
- Storage Optimized (L) - Large indexes, at the cost of higher query latency
Replicas and partitions
- Replicas service multiple concurrent query requests
- Partitions split I/O operations for read / index
- Azure AI Search components
- Data source - Unstructured files in Azure blob storage containers.
- Tables in Azure SQL Database.
- Documents in Cosmos DB. - Skillset
- AI skill ที่มาช่วย indexer มันอาจจะแอบไปเรียก Azure AI Language Service เพื่อให้รู้ว่าภาษาที่ใช้ / Key Phase / Location เป็นต้น หรือทำ Custom Model ก็ได้
- เขียน Logic เอง Deploy webapi / Azure Function - Indexer - engine ทำ index ข้อมูลที่เก็บ จะอิงไปทำ Skillset ที่มี ถ้าเพิ่ม Field / Skill ควร ReIndex ใหม่ เช่น เอาเอกสารที่มีรูปเข้าไป มันจะแยก
document - metadata_storage_name - metadata_author - content - normalized_images -> image0 -> image1 //ถ้ามี Skillset language จะมีตัว document - metadata_storage_name - metadata_author - content - normalized_images -> image0 -> image1 - language
- Index - searchable result of the indexing process. It consists of a collection of JSON documents
- key: Fields that define a unique key for index records.
- searchable: Fields that can be queried using full-text search.
- filterable: Fields that can be included in filter expressions to return only documents that match specified constraints. - sortable: Fields that can be used to order the results.
- facetable: Fields that can be used to determine values for facets (user interface elements used to filter the results based on a list of known field values).
- retrievable: Fields that can be included in search results (by default, all fields are retrievable unless this attribute is explicitly removed).
- Search an index: Full text search
mode based on the Lucene query syntax
- Simple
- Full complex filtering, regular expressions, and other more sophisticated queries\
query include:
- search - A search expression that includes the terms to be found.
- queryType - The Lucene syntax to be evaluated (simple or full).
- searchFields - The index fields to be searched.
- select - The fields to be included in the results.
- searchMode - Criteria for including results based on multiple search terms. For example, suppose you search for comfortable hotel. A searchMode value of Any returns documents that contain "comfortable", "hotel", or both; while a searchMode value of All restricts results to documents that contain both "comfortable" and "hotel"
Query processing consists of four stages:
- Query parsing - evaluated and reconstructed as a tree of appropriate subqueries โดยใน subqueries ประกอบไปด้วย
- term queries free
- phrase queries “free parking”
- prefix queries - air* - *Lexical analysis - based on linguistic rules เช่น
- stopwords* พวก "the", "a", "is”
- แปลงศัพท์ root เช่น comfortable >> comfort - Document retrieval
- Scoring - (TF/IDF) calculation
filtering and sorting (OData)
- Filtering results
search=London+author='Reviewer' queryType=Simple search=London $filter=author eq 'Reviewer' queryType=Full
- Filtering with facets
search=* facet=author search=* $filter=author eq 'selected-facet-value-here'
- Sorting results
search=* $orderby=last_modified desc
Enhance the index
- Search-as-you-type - 2 แบบ Suggestions / Autocomplete
- Custom scoring and result boosting - defining a scoring profile that applies a weighting value to specific fields
- Synonyms - define synonym maps that link related terms together
Exercise - Create a search solution
Knowledge check - Knowledge check - Training | Microsoft Learn / mslearn-knowledge-mining (microsoftlearning.github.io)
Create a custom skill for Azure AI Search
- dev customer skill ไม่น่าจะเป็น AI Service / webapi / Azure Function แล้วเอา Endpoint ออกมา โดยต้องมีรูปแบบ Input output ตามนี้ Create a custom skill - Training | Microsoft Learn
- เพิ่ม Skill Add a custom skill to a skillset - Training | Microsoft Learn
Exercise - Implement a custom skill / Create a Custom Skill for Azure AI Search
Knowledge check - Knowledge check - Training | Microsoft Learn / mslearn-knowledge-mining (microsoftlearning.github.io)
Create a knowledge store with Azure AI Search
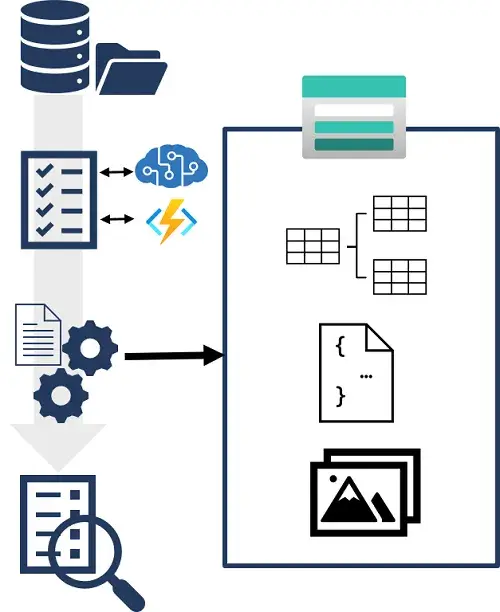
Knowledge stores ผลจาก Data Source > Indexer ที่เป็น
- JSON
- Normalize the index records
- Extracted embedded images from documents - metadata + file
ถ้าต้องการเก็บข้อมูลอื่นๆเพิ่มเติม เราต้องทำ Projection
- JSON ใช้ object projection ถ้าแปลง json ไปเป็นอีก pattern ใช้ #Microsoft.Skills.Util.ShaperSkill
- ข้อมูลจาก RDBMS ใช้ table projection
- แยกรูปจากเอกสารใช้ file projection
กำหนด knowledgeStore - Define a knowledge store - Training | Microsoft Learn
"knowledgeStore" : {
"storageConnectionString": "DefaultEndpointsProtocol=https;AccountName=<Acct Name>;AccountKey=<Acct Key>;",
"projections": [
{
"tables": [ ],
"objects": [ ],
"files": [ ]
}
]
}
Exercise - Create a knowledge store
Knowledge check - Knowledge check - Training | Microsoft Learn
Enrich your data with Azure AI Language
Azure AI Language features into the following areas:
- Classify text
- Understand questions and conversational language
- Extract information
- Summarize text
- Translate text
Step
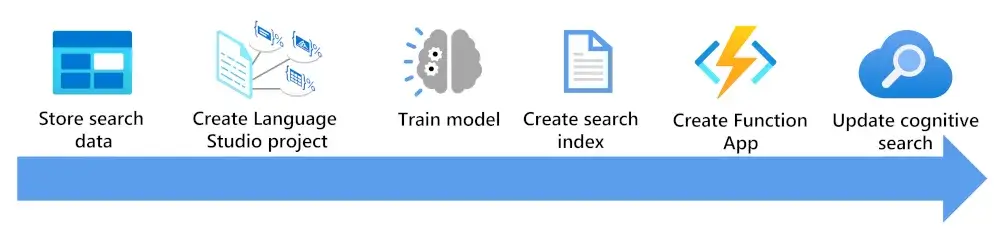
- store search data
- Create Language Project - Train
- Create Search Index - Create an Azure AI Search solution.
- Create Function App - เป็น Skill และแปลงด้วยจาก AI Search มาเป็น AI Language ต้องการส่ง และรับผลลัพธ์กลับ
- Update your Azure AI Search solution
- make to enrich your search index add field / add a custom skillset / map result**
Exercise: Enrich a search index in Azure AI Search with custom classes
Knowledge check - Knowledge check - Training | Microsoft Learn
Implement advanced search features in Azure AI Search
- Search an index
ขยายเรื่อง query ถ้าเคยใช้ Apache Lucene ไม่น่าจะติดอะไร
- simple
search=luxury&$select=HotelId, HotelName, Category, Tags, Description&$count=true //can be improve search=luxury + air con&$select=HotelId, HotelName, Category, Tags, Description&$count=true
- Full
(&queryType=full)แบบ Full ช่วยให้ได้ผลลัพธ์ที่ตรงใจมากกว่า
- Boolean operators:AND,OR,NOTfor exampleluxury AND 'air con'
- Field search:fieldName:searchterm for exampleDescription:luxury AND Tags:air con
- Fuzzy search:~for exampleDescription:luxury~returns results with misspelled versions of luxury
- Term proximity search:"term1 term2"~nfor example"indoor swimming pool"~3returns documents with the words indoor swimming pool within three words of each other
- Regular expression search:/regular expression/use a regular expression between/for example/[mh]otel/would return documents with hotel and motel
- Wildcard search:*,?where*will match many characters and?matches a single character for example'air con'*would find air con and air conditioning
- Precedence grouping:(term AND (term OR term))for example(Description:luxury OR Category:luxury) AND Tags:air?con*
- Term boosting:^for exampleDescription:luxury OR Category:luxury^3would give hotels with the category luxury a higher score than luxury in the description ตรง Term Boosting ทำ Priority Score
ตรง Term Boosting ทำ Priority Score
search=luxury AND air con&$select=HotelId, HotelName, Category, Tags, Description&$count=true&queryType=full
- adding scoring profiles
อารมณ์เหมือนเพิ่ม Weight ให้ Result
Add a weighted scoring profile
You can add up to 100 scoring profiles to a search index. The simplest way to create a scoring profile is in the Azure portal.

- Navigate to your search service.
- Select Indexes, then select the index to add a scoring profile to.
- Select Scoring profiles.
- Select + Add scoring profile.
- In Profile name, enter a unique name.
- To set the scoring profile as a default to be applied to all searches select Set as default profile.
- In Field name, select a field. Then for Weight, enter a weight value.
- Select Save.
Function
| Function | Description |
| Magnitude | Alter scores based on a range of values for a numeric field |
| Freshness | Alter scores based on the freshness of documents as given by a DateTimeOffset field |
| Distance | Alter scores based on the distance between a reference location and a GeographyPoint field |
| Tag | Alter scores based on common tag values in documents and queries |
- analyzers and tokenized terms
ปกติใช้ตัว Lucene analyzer แต่มี Built-In อื่นๆด้วย
- Language analyzers
- Specialized analyzers - จับ Field พิเศษ เช่น zip codes or product IDs โดยใช้ PatternAnalyzer + regular expression
ถ้าไม่พอทำ custom analyzer มาประกอบ
- Character filters. These filters process a string before it reaches the tokenizer.
- html_strip
- mapping
- pattern_replace - Tokenizers. These components divide the text into tokens to be added to the index. Tokenizers also break down words into their root forms
- classic - euro grammar
- keyword
- lowercase
- microsoft_language_tokenizer - grammar ตามภาษา
- pattern
- whitespace - Token filters. These filters remove or modify the tokens emitted by the tokenizer.
- Language-specific filters, such as arabic_normalization.
- apostrophe‘
- classic. This filter removes English possessives and dots from acronyms.
- keep. This filter removes any token that doesn't include one or more words from a list you specify.
- length. This filter removes any token that is longer than your specified minimum or shorter than your specified maximum.
- trim
โดยทำเป็น json config
"analyzers":(optional)[
{
"name":"ContosoAnalyzer",
"@odata.type":"#Microsoft.Azure.Search.CustomAnalyzer",
"charFilters":[
"WebContentRemover"
],
"tokenizer":"IcelandicTokenizer",
"tokenFilters":[
"ApostropheFilter"
]
}
],
"charFilters":(optional)[
{
"name":"WebContentRemover",
"@odata.type":"#html_strip"
}
],
"tokenizers":(optional)[
{
"name":"IcelandicTokenizer",
"@odata.type":"#microsoft_language_tokenizer",
"language":"icelandic",
"isSearchTokenizer":false,
}
],
"tokenFilters":(optional)[
{
"name":"ApostropheFilter",
"@odata.type":"#apostrophe"
}
]
เรียกใช้
"fields": [
{
"name": "IcelandicDescription",
"type": "Edm.String",
"retrievable": true,
"searchable": true,
"analyzer": "ContosoAnalyzer",
"indexAnalyzer": null,
"searchAnalyzer": null
},
- Add language specific fields
Using the
searchFieldsandselectproperties in the above results would return these results from the real estate sample database.
ซึ่ง Field พวกนี้ เราอาจจะให้ skill แปลไว้ แล้วจัดเก็บ Enhance an index to include multiple languages - Training | Microsoft Learn
- Ordering results by distance from a given reference point
geo.distancegeo.intersectstrueif the location of a search result is inside a polygon that you specify
Exercise - Implement enhancements to search results
Knowledge check - https://learn.microsoft.com/en-us/training/modules/implement-advanced-search-features-azure-cognitive-search/08-knowledge-check
Build an Azure Machine Learning custom skill for Azure AI Search
ใช้ #Microsoft.Skills.Custom.AmlSkill
- กำหนด Skill บอก input output ด้วยนะ
{
"@odata.type": "#Microsoft.Skills.Custom.AmlSkill",
"name": "AML name",
"description": "AML description",
"context": "/document",
"uri": "https://[Your AML endpoint]",
"key": "Your AML endpoint key",
"resourceId": null,
"region": null,
"timeout": "PT30S",
"degreeOfParallelism": 1,
"inputs": [
{
"name": "field name in the AML model",
"source": "field from the document in the index"
},
{
"name": "field name in the AML model",
"source": "field from the document in the index"
},
],
"outputs": [
{
"name": "result field from the AML model",
"targetName": "result field in the document"
}
]
}
- ใน AML รับ input และ json ตามที่ตกลงไว้ ในที่นี้ (Ref: Enrich a search index using an Azure Machine Learning model - Training | Microsoft Learn)
- control the performance of the skill aretimeoutanddegreeOfParallelism.
- ไม่มีรับงานแบบ batch ถ้าต้องการให้เร็วต้องเพิ่ม node AKS

"outputs": [
{
"name": "result field from the AML model",
"targetName": "result field in the document"
}
]
Exercise: Enrich a search index using Azure Machine Learning model
Knowledge check Knowledge check - Training | Microsoft Learn
Search data outside the Azure platform in Azure AI Search using Azure Data Factory
เอา ADF มาช่วยอะไร
- Use Azure Data Factory to copy data into an Azure AI Search Index.
- Use the Azure AI Search push API to add to an index from any external data source.
ทำ Data Update
- pipeline automate Index data from external data sources using Azure Data Factory - Training | Microsoft Learn แต่มีข้อจำกัดด้าน Data Type นะ String / int / double /boolean / DataTimeOffset
- PUSH REST API operations Index any data using the Azure AI Search push API - Training | Microsoft Learn
backoff retry strategy - If your index starts to throttle requests due to overloads, it responds with a 503 (request rejected due to heavy load) or 207 (some documents failed in the batch) status
Exercise: Add to an index using the push API
Knowledge check - Knowledge check - Training | Microsoft Learn
Maintain an Azure AI Search solution
- Manage security of an Azure AI Search solution
Data encryption
- Data in transit is encrypted using the standard HTTPS TLS 1.3 port 443
- แต่ใช้ key ตัวเองที่เก็บใน Azure Key Vault ก็ได้
Secure inbound traffic
- on-premises resources, you can harden security with an ExpressRoute circuit, Azure Gateway, and an App service.
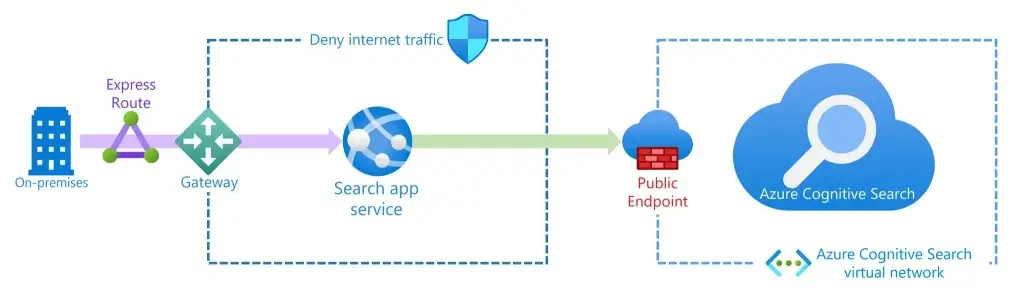
Authenticate requests to your search solution
- ACS is key-based authentication
- admin key
- Query keys - Role-based access control (RBAC)
build-in role: Owner / Contributor / Reader manage the data plane for example search indexes or data sources
- Search Service Contributor
- Search Index Data Contributor - A role for developers or index owners who will import, refresh, or query
- Search Index Data Reader - Read-only access role for apps and users who run query
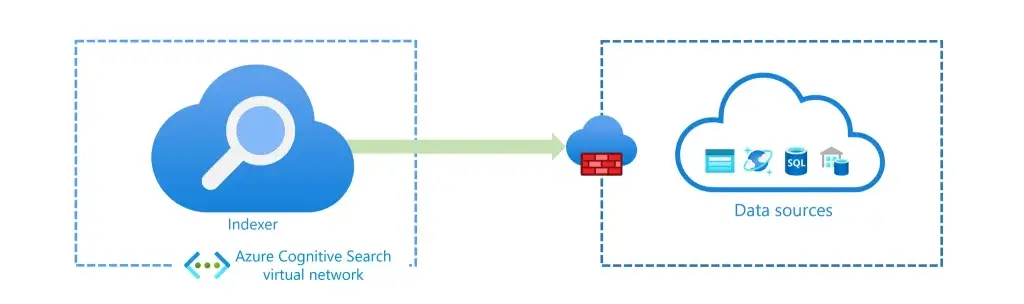
Secure outbound traffic
- private link
- firewall
Secure data at the document-level
Controlling who has access at the document level requires you to update each document in your search index.
- add a new security field to every document that contains the user or group IDs that can access it.
- The security field needs to be filterable so that you can filter search results on the field.
- Optimize performance of an Azure AI Search solution
Measure your current search performance
- ต้องมี Log Analytic Workspace ก่อนนะเสียเงินก่อน
- แล้ว AI Resource > diagnostic > Add new Log / Metric ที่ต้องการส่งไป
นอกจากนี้ยังดู Flow
Check if your search service is throttled (Client เจอ 503)
- จาก Log ที่ส่งไปมา ลอง KQL
AzureDiagnostics | where TimeGenerated > ago(7d) | summarize count() by resultSignature_d | render barchart
- หรือจะดูจาก REST API ที่ยิงก็ได้ ดูจาก Response Header > elapsed-time
Optimize your index size and schema
- indexes can grow over time. You should review that all the documents in your index are still relevant and need to be searchable. index ไหนไม่จำป็นเอาเอาออก
- can you reduce the complexity of the schema?
- จำเป็นต้องไปใช้ใน SkillSet / Search / Filter ไหม ถ้าไม่ให้เอาออกไป
Improve the performance of your queries (//แอบคล้าย SQL)
- searchFields parameter เอาเท่าที่ใช้
- Return the smallest number of fields
- avoid partial search terms like prefix search or regular expressions. - ใช้ compute เยอะ
- high skip values. This forces the search engine to retrieve and rank larger volumes of data.
- Limit using facetable and filterable fields to low cardinality data.
- ใช้ in ดีกว่าไป ดักทีละอัน แล้ว or
Use the best service tier for your search needs
ต้อง plan estimate ว่า index โตขนานไหน เพราะ
- The largest index supported currently is 12 partitions แบบทางซ้ายจะเพิ่มลำบากและ
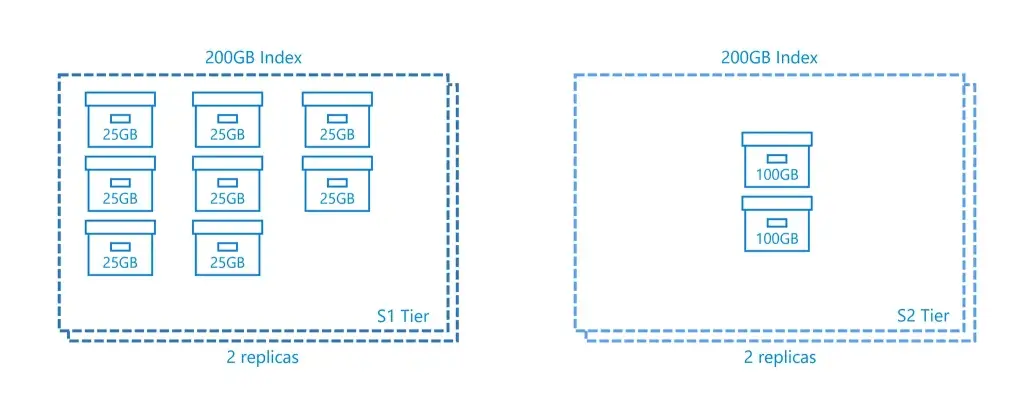
Note: A search unit (SU) is the product of replicas and partitions.
Ref: Service limits for tiers and skus - Azure AI Search | Microsoft Learn
- Manage costs of an Azure AI Search solution
- Azure AI Search pricing calculator.
- Understand the billing model
| Feature | Unit |
|---|---|
| Indexer usage | Per 1000 API calls |
| Image extraction (AI enrichment) | Per 1000 text records |
| Built-in skills (AI enrichment) | Number of transactions, billed at the same rate as if you had performed the task by calling Azure AI Services directly. You can process 20 documents per indexer per day for free. Larger or more frequent workloads require a multi-resource Azure AI Services key. |
| Custom Entity Lookup skill (AI enrichment) | Per 1000 text records |
| Semantic Search | Number of queries of "queryType=semantic", billed at a progressive rate |
| Private Endpoints | Billed as long as the endpoint exists, and billed for bandwidth |
Tips to reduce the cost of your search solution
These tips can help you reduce the cost of running your search solution:
- Minimize bandwidth costs by using as few regions as possible. Ideally, all the resources should reside in the same region.
- If you have predictable patterns of indexing new data, consider scaling up inside your search tier. Then scale back down for your regular querying.
- To keep your search requests and responses inside the Azure datacenter boundary, use an Azure Web App front-end as your search app.
- Enable enrichment caching if you're using AI enrichment on blob storage.
Reduce Cost: Tutorial: Create and manage Azure budgets
- Improve reliability of an Azure AI Search solution
- Two replicas guarantee 99.9% availability for your queries
- Three or more replicas guarantee 99.9% availability for both queries and indexing
Azure ไม่มี Tools ดังนั้น build your own tools to back up index definitions as a series of JSON files
-Monitor an Azure AI Search solution
- เอาจาก Log Analytic มี Sample Query Monitor an Azure AI Search solution - Training | Microsoft Learn
- Create Alert ได้
- Debug search issues using the Azure portal
เอามาช่วยตรวจ
- SkillSet
- Validate the field mappings
โดยมี Visual Graph แสดงผลให้ Track
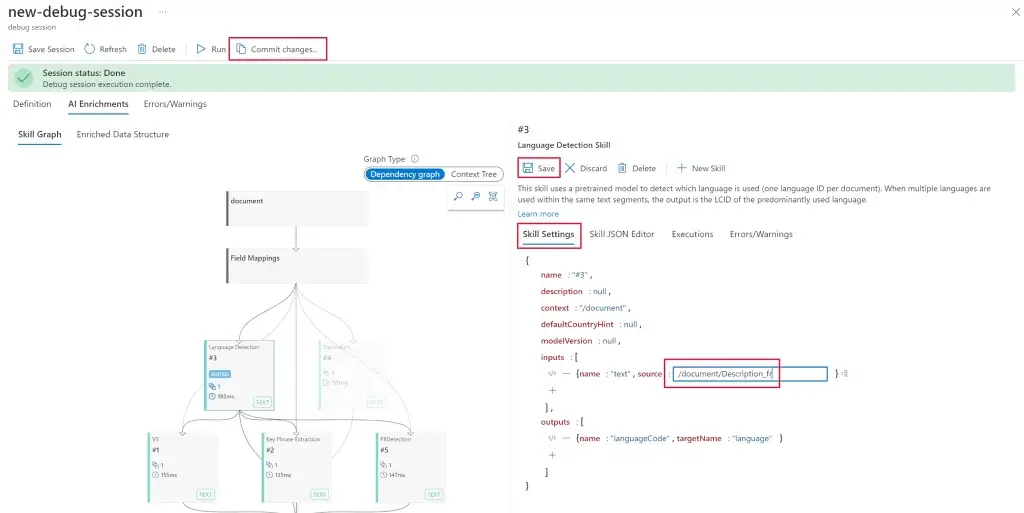
Sample: Debug search issues using the Azure portal - Training | Microsoft Learn
Exercise - Debug search issues
Knowledge check - Knowledge check - Training | Microsoft Learn
Q: Azure AI Search service has been created, which three metrics can be viewed in graphs without any other configuration?
A: Search latency, queries per second, and the percentage of throttled queries.
Perform search re-ranking with semantic ranking in Azure AI Search
Semantic ranking improves the ranking of search results by using language understanding to more accurately match the context of the original query.
- BM25 (default) - based on the frequency that the search term appears within a document.
- Semantic ranking
- Top 50 จาก BM25 ranking + Convert 256 unique tokens + check token matching with query
Setup: Set up semantic ranking - Training | Microsoft Learn
Exercise - Use semantic ranking on an index
Knowledge check - Knowledge check - Training | Microsoft Learn
Perform vector search and retrieval in Azure AI Search
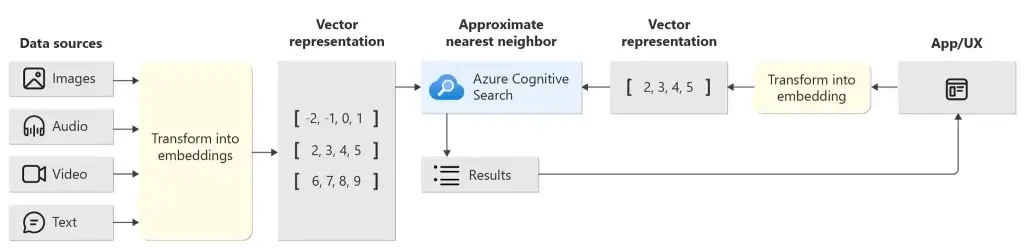
When to use vector search
- Use OpenAI or open source models to encode text, and use queries encoded as vectors to retrieve documents.
- Do a similarity search across encoded images, text, video and audio, or a mixture of these (multi-modal).
- Represent documents in different languages using a multi-lingual embedded model to find documents in any language.
- Build hybrid searched from vector and searchable text fields as vector searches are implemented at field level. The results will be merged to return a single response.
- Apply filters to text and numeric fields and include this in your query to reduce the data that your vector search needs to process.
- To create a vector database to provide an external knowledge base or use as a long term memory.
Limitations
- You'll need to provide the embeddings using Azure OpenAI or a similar open source solution, as Azure AI Search doesn't generate these for your content.
- Customer Managed Keys (CMK) aren't supported.
- There are storage limitations applicable so you should check what your service quota provides.
ต้องมาปรับ
- index has vector fields
field named vectorSearch of with the type Collection(Edm.single). This has an algorithm configuration and an attribute of 'dimension'.
- query input into a vector
embedding is type of data representation that is used by machine learning models. An embedding represents the
- Embedding models - model > vector
- Embedding space - ที่มีความสัมพันธ์กันของมิติ (Dimension) ต่าง ๆ ของ Vector ต่างๆ ที่ใน document มี
Exercise - Use the REST API to run vector search queries
Knowledge check - Knowledge check - Training | Microsoft Learn
Reference
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.