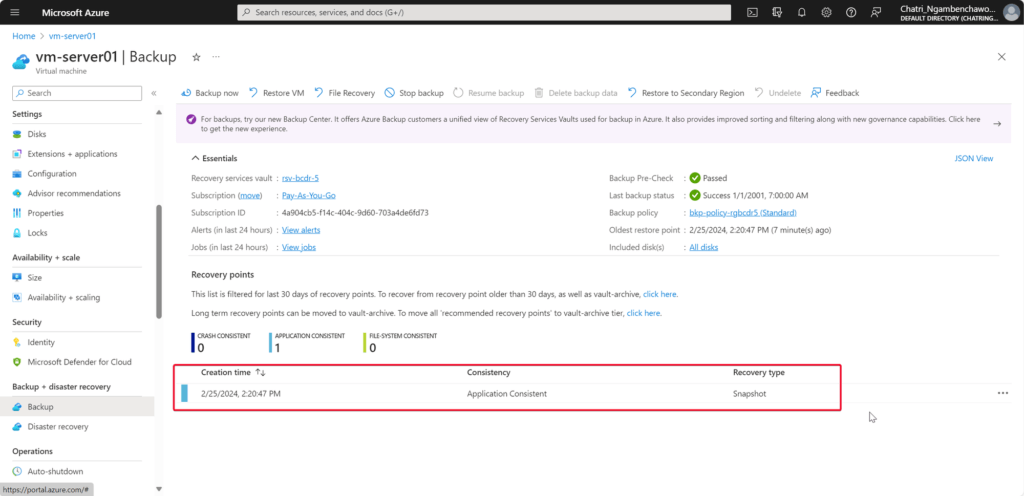
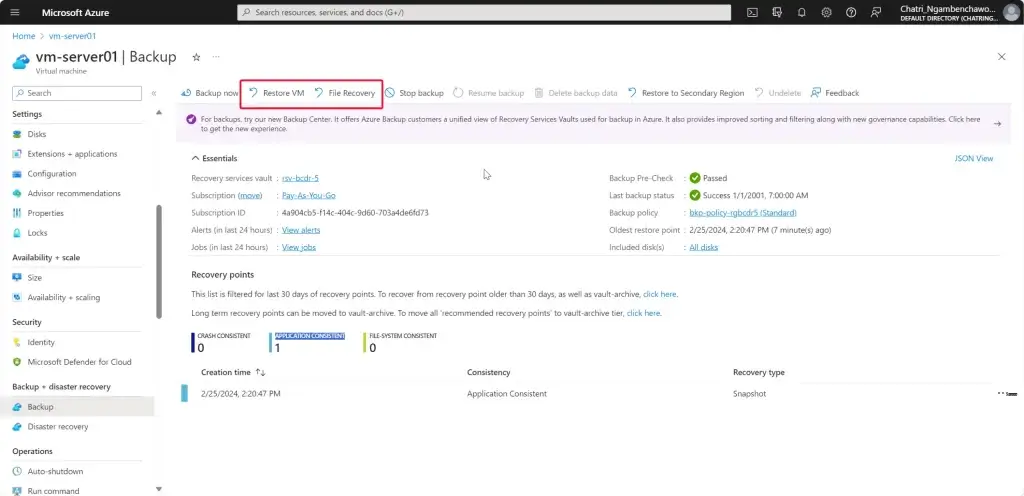
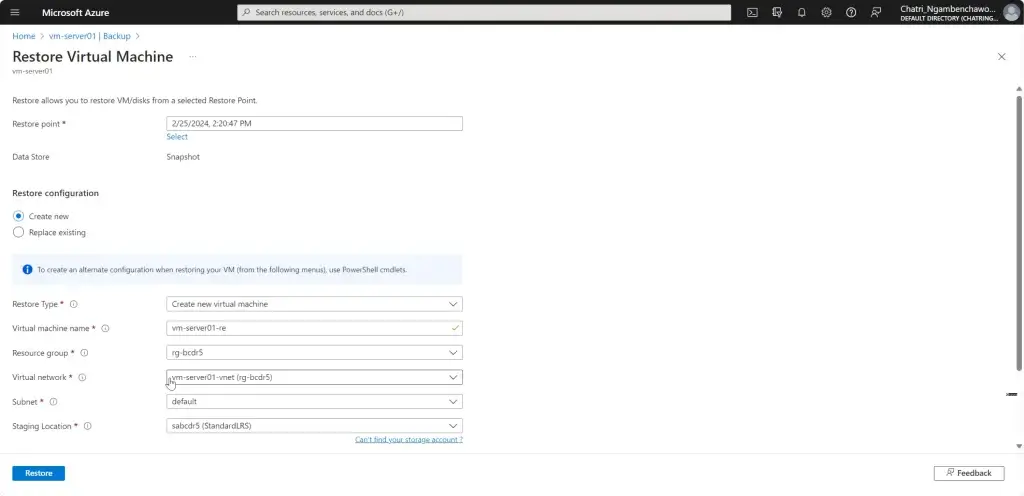
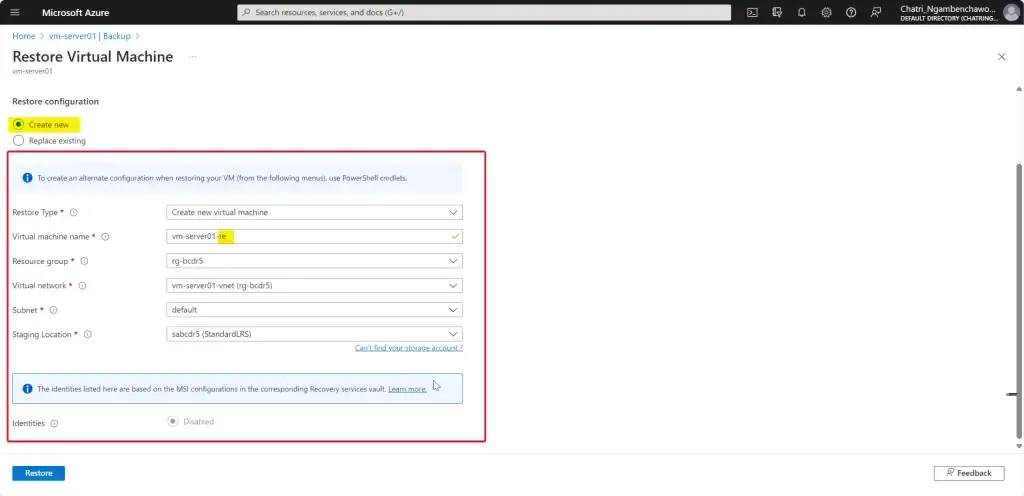
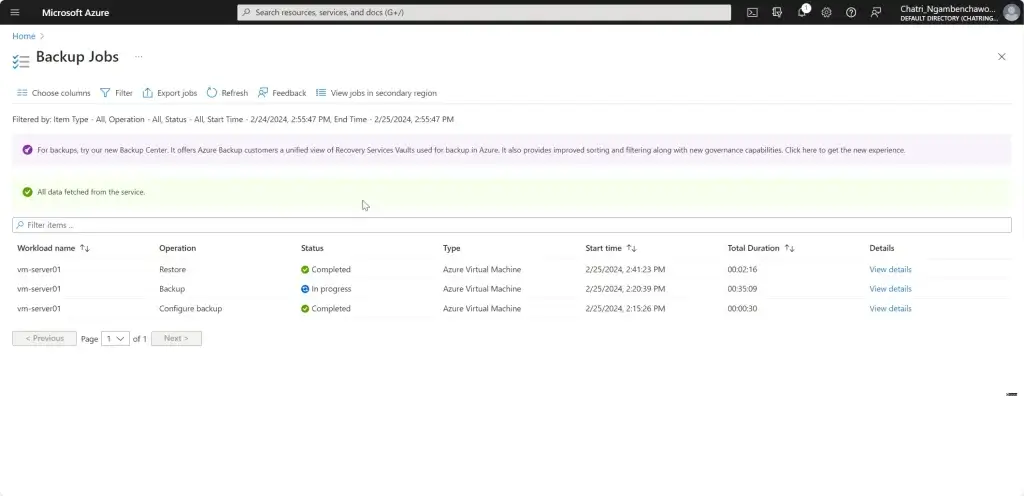
การทำให้เกิด Business Continuity ต้องทำให้เกิดความพร้อม (Readiness) จากเหตุการณ์ต่างๆ โดยปกติจะอยู่ในรูปของแผน BCP (Business Continuity Plan) เกิดอะไรขึ้นมา แล้วใครต้องมีหน้าที่อะไรบ้าง Contract Point ถ้าเอาตามมาตรฐานอย่าง ISO มีบังคับนะ
BCP ทำมาเพื่อ - reduce downtime - mitigating risk + remediating issue เช่น ลด data loss / data corruption / ธุรกิจหยุดชะงักได้ กระทบรายได้ เป็นต้น
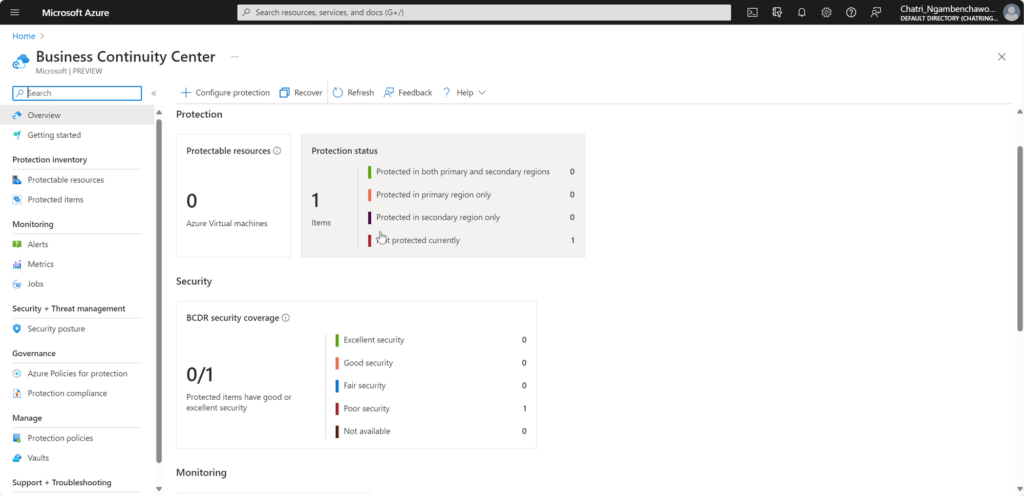
Key ของ BCDR มี 3 ส่วน ได้แก่ - Process - เวลาเกิดเคสจริงขึ้น ต้องมี Step รับมืออย่างไร - People - ทุกคนต้องรู้หน้าที่ของตัวเอง - Technology - เครื่องมือช่วยให้ Process + People ทำงานได้ไว สะดวกขึ้นตามแผน BC / DR
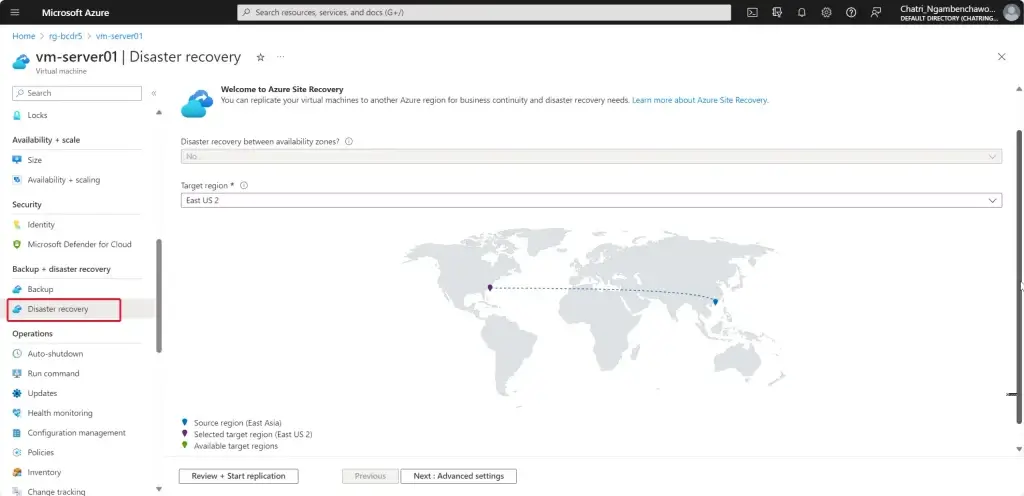
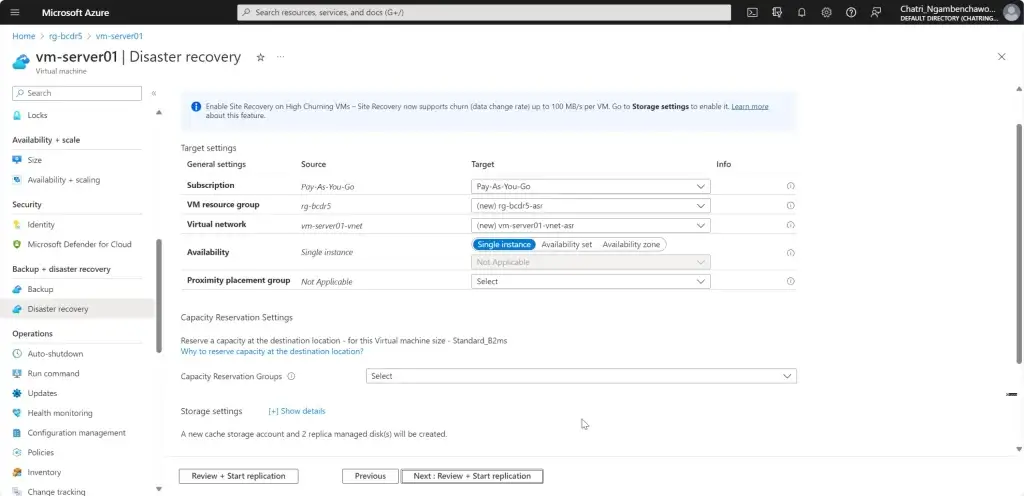
Disaster Recovery - เรียกว่าเป็น ส่วนนึงของ BCP ก็ได้ โดยจะไป focus กับงาน IT ไม่ให้ล่ม โดยจะมองว่าเป็นส่วน เพื่อช่วยให้ Business เสริมกัน
Compnent หรือ Key ของ BCP ที่ควรพิจารณา
resilience - ผู้ใช้ / business ต้องได้รับผลกระทบน้อยที่สุด ถ้าเกิดเหตุจริงต้องอะไร พังแล้วไปใช้ อีกระบบอีก Region แต่ ผู้ใช้ / business ไม่รู้หรอกว่ามันพัง ใช้ส่วนอื่นไป
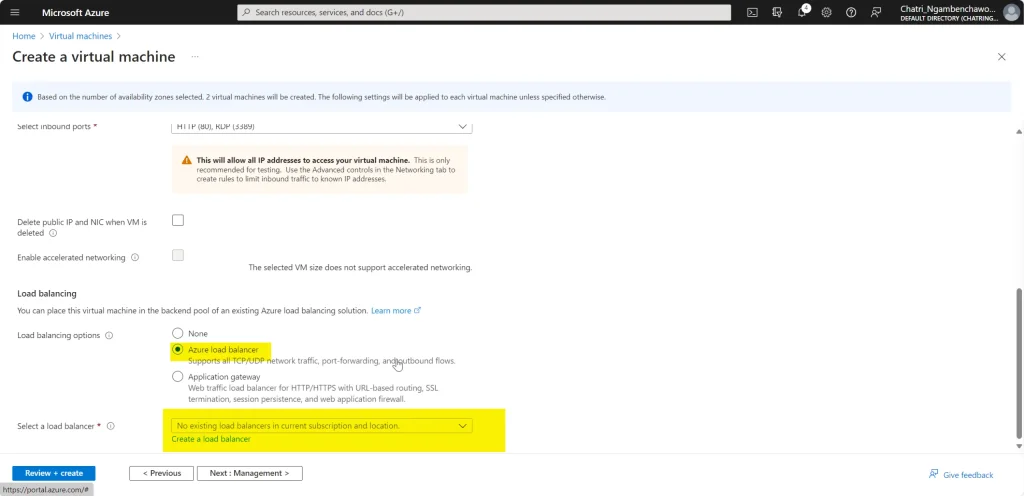
Azure Load balancer (OSI Layer4) - region scope - กระจาย Traffic โดยมีแบบ External (Traffic Internet) / Internal เหมาะกับ App ที่ Stateless Note: - ถ้าเป็น Stateful พวก DB / Blob มันมี option ของมัน Note: service ส่วนใหญ่ของ Azure ทำงานในระดับ Region
Azure Traffic Manager - Global Scope - DNS based เลือก region access ที่เหลือจะเป็นตัว Internal แต่ละ region แล้ว LB > App - กำหนด Time To Live(TTL) ให้เหมาะสม - ทำได้หลายอย่างนะ นอกจาก Solution High Availability ยังมีเรื่อง Geo-Location
DNS พวก Backend IP แต่มันอาจจะมี Cache และไม่มีกระบวนการตรวจนะ มันโยนไปใส่ IP ใน pool ตายไหม
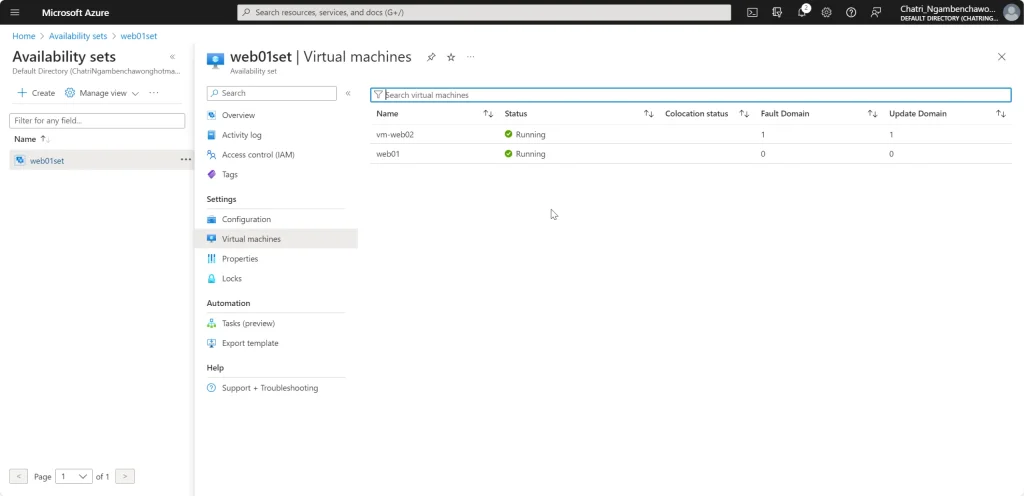
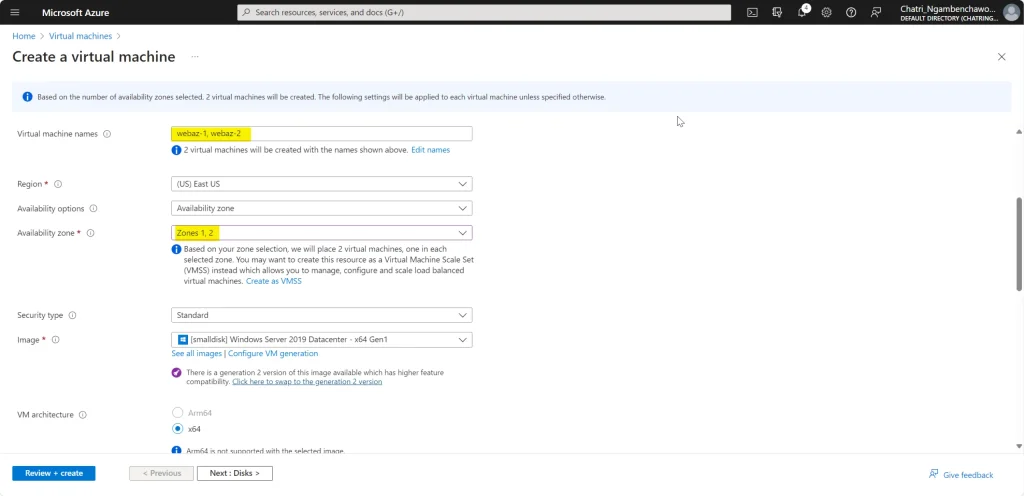
หลังจากมี Workshop ลองทำตัว Availability Set / Availability Zone ตอนสร้าง Resource อย่างตัว VM มันจะมีให้เลือกเลยนะ ทั้ง Availability Set / Availability Zone
Workshop1: Availability Set + Manual Create Load Balance
1. ตออนสร้าง Resource กำหนด AS ด้วย
2. ตอนสร้าง VM เลือกได้เลยนะ เลือกแล้วจะดูได้ประมาณนี้
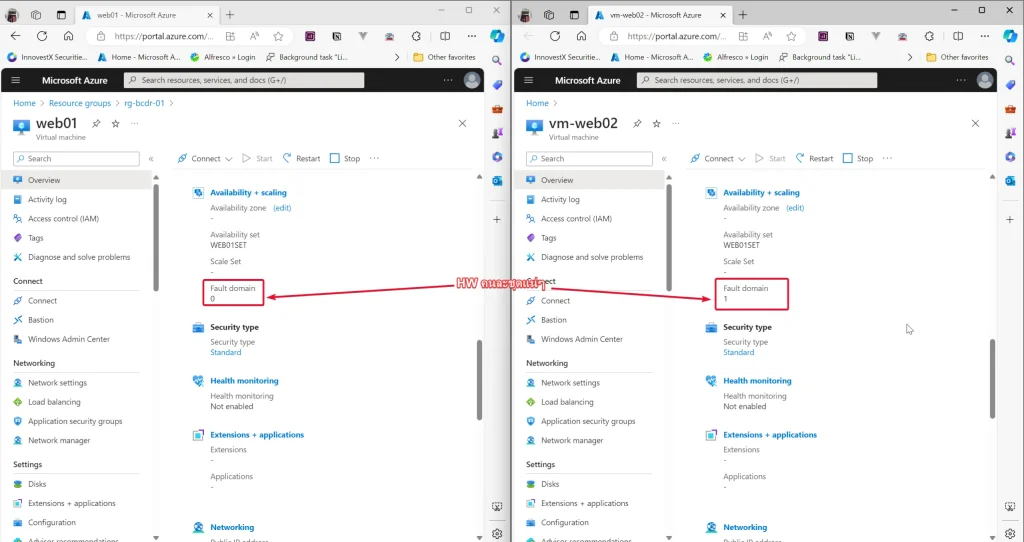
3. เข้าไปดูในแต่ละ VM จะเห็นว่ามีนแยกคนละ Fault Domain / Deploy App
Create IIS + Deploy App
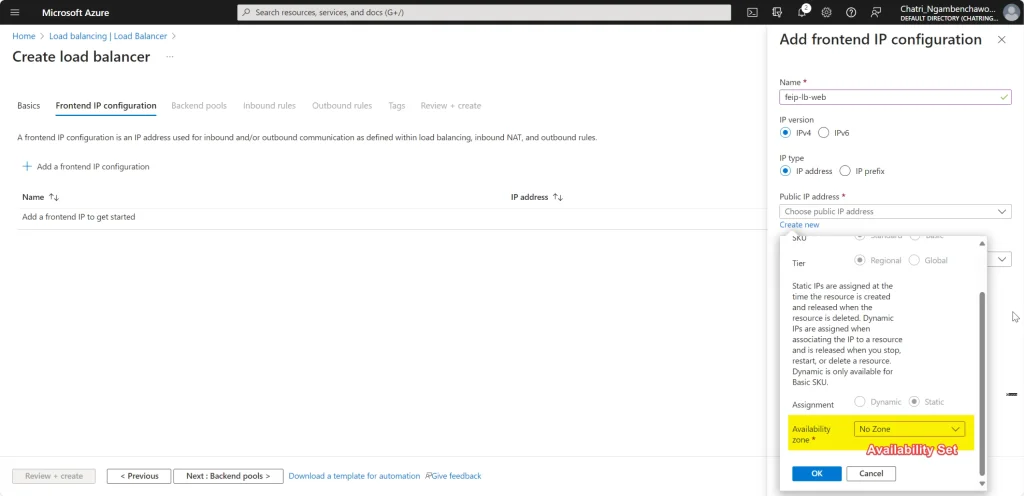
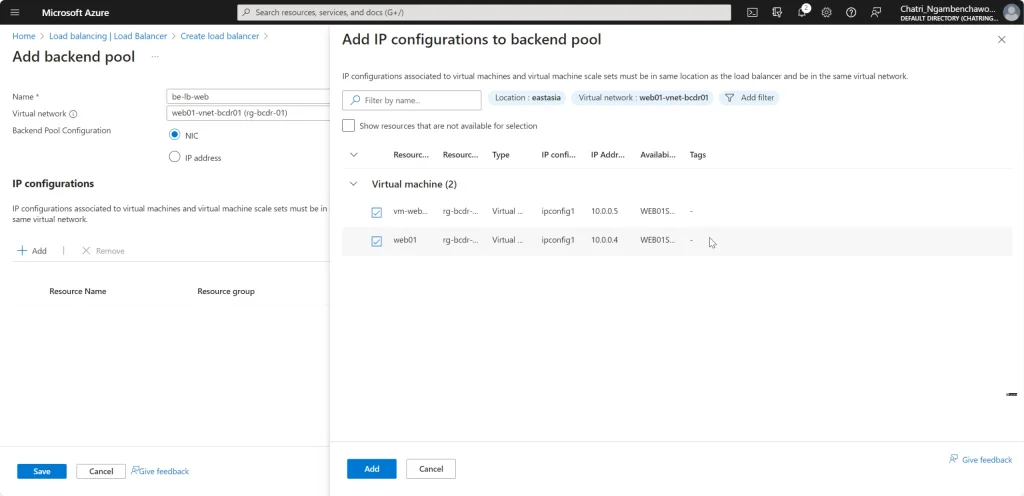
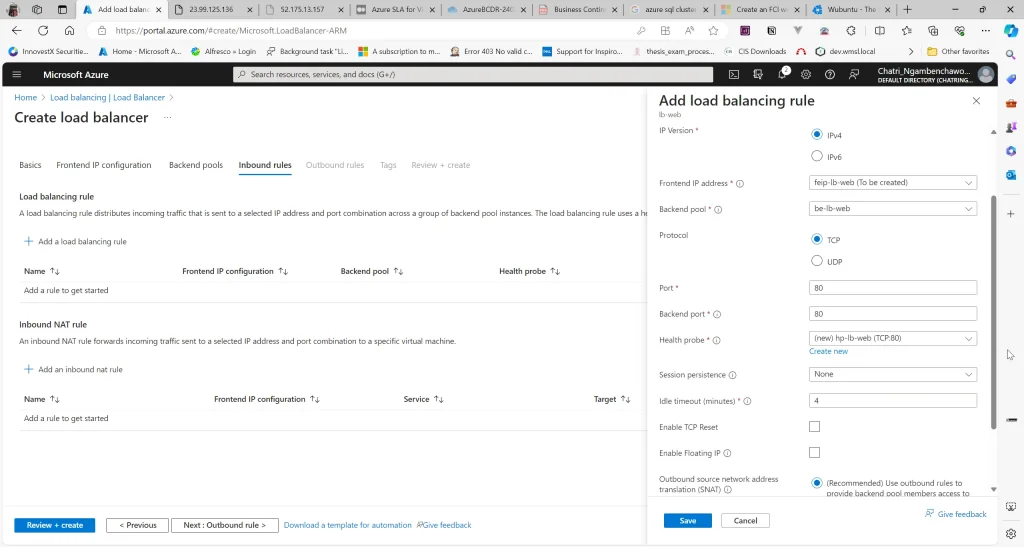
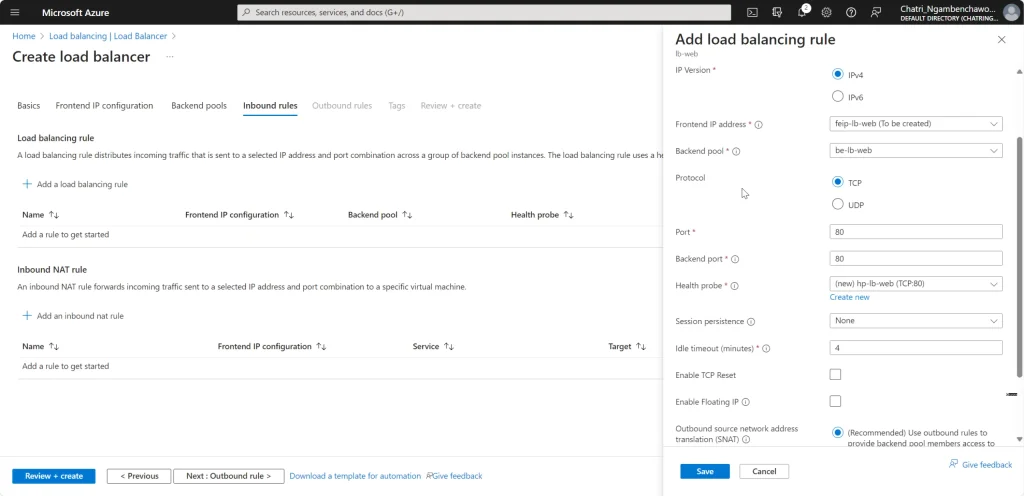
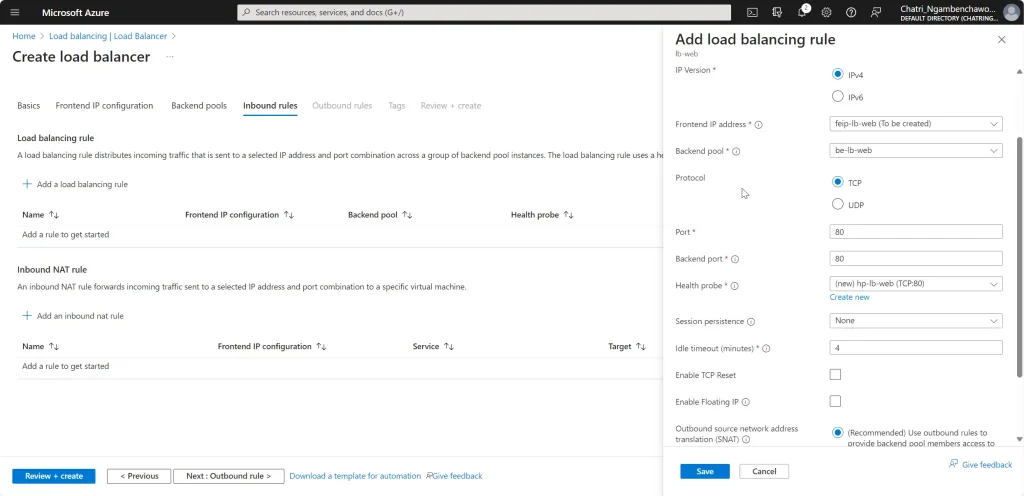
Create LB มี 2 Type External (Request จาก Internet) และ Internal - FrontEnd IP - ส่วนที่มาจากรีบ Request - Backend IP - ส่วนของ Resource เช่น AS / AZ
Workshop2: Availability Zone + Load Balancing ทำพร้อมกันไปเลย //เสียเงินง่าย
สรุป ระหว่าง Availability Set / Availability Zone >> ควรเลือก Availability Zone นะ
จบวันแรก และต่อวันที่ 2 ตัว Azure Traffic Manager
Workshop3: Azure Traffic Manager
Sample Arch
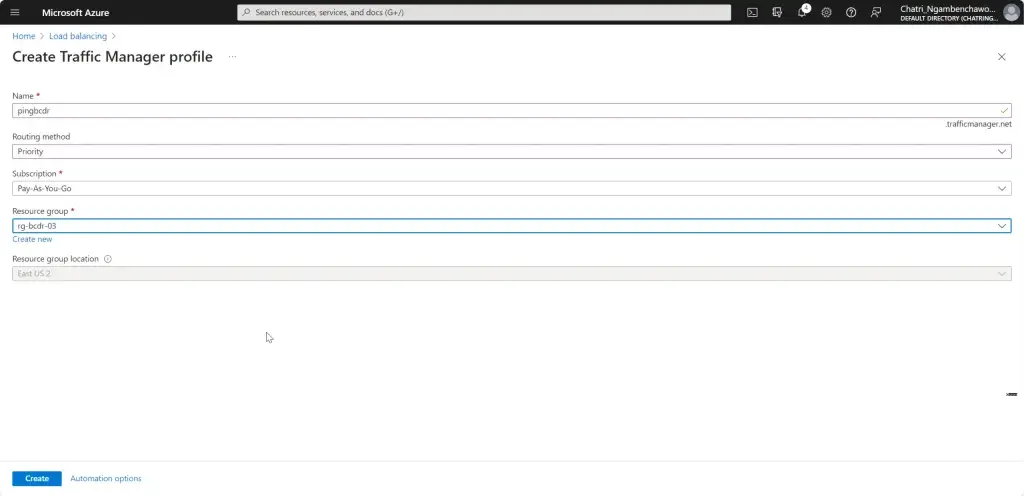
Config Azure Traffic Manager
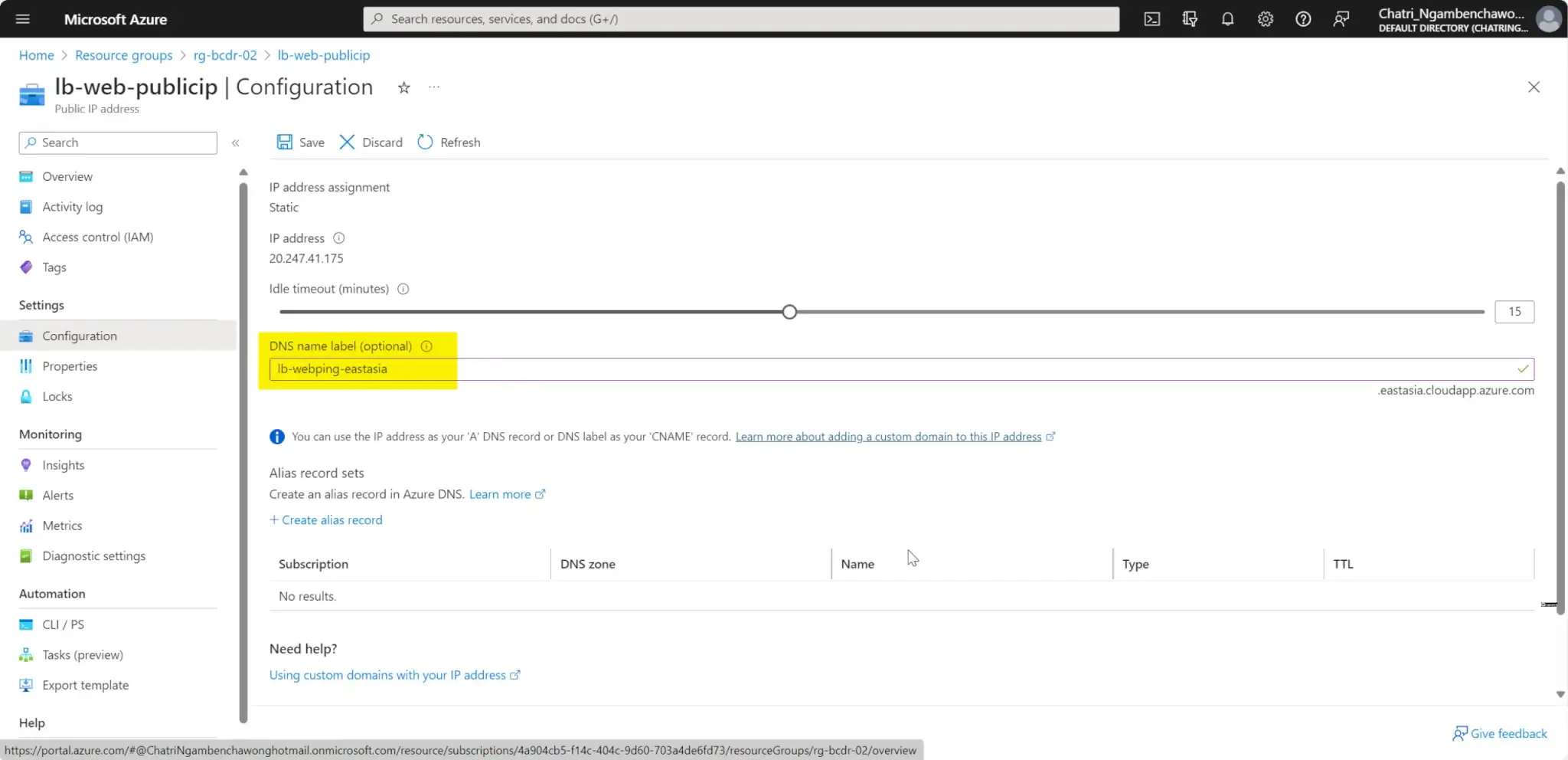
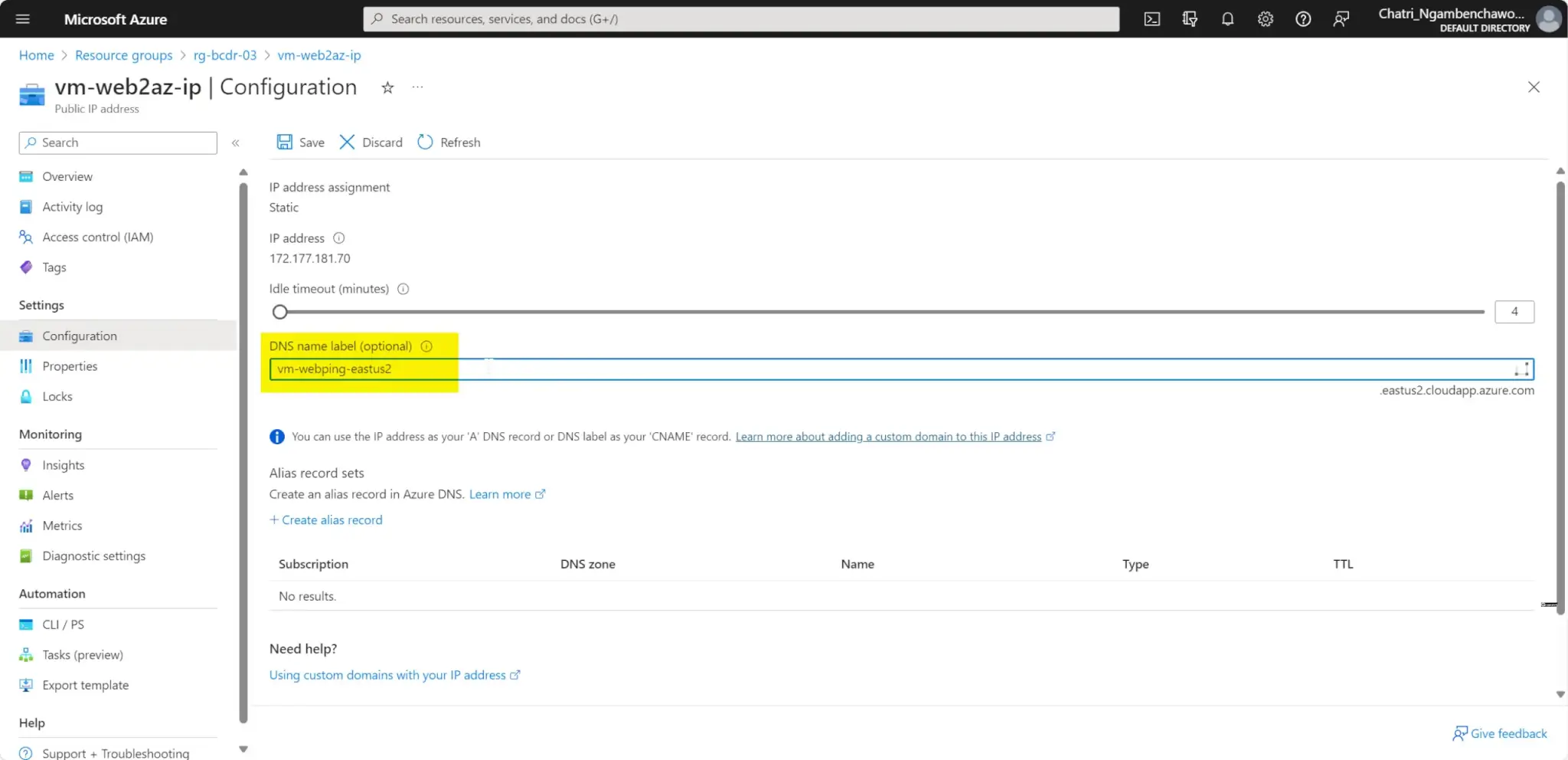
กำหนด DNS สำหรับ public ip ที่ผูกกับ Load Balance หรือ VM
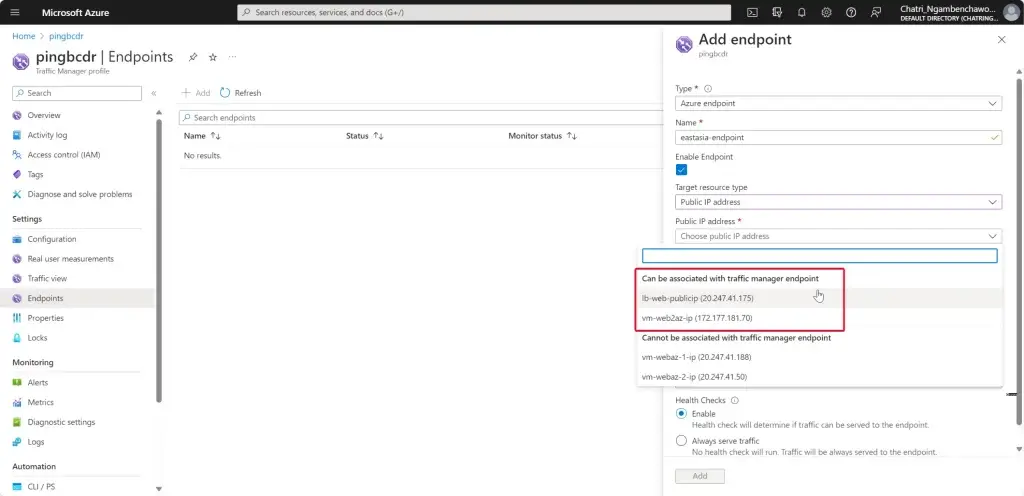
ถ้าลืมกำหนด DNS ตอน Add End Point ที่ Azure Traffic Manager มันจะแจ้ง
2. มีหลาย Option ให้เลือก ทั้งการเลือก Zone ว่าจะเอาความใกล้ (Geo Location) / Performance / Priority เป็นต้น + Health Probe
3. เลือก Priority
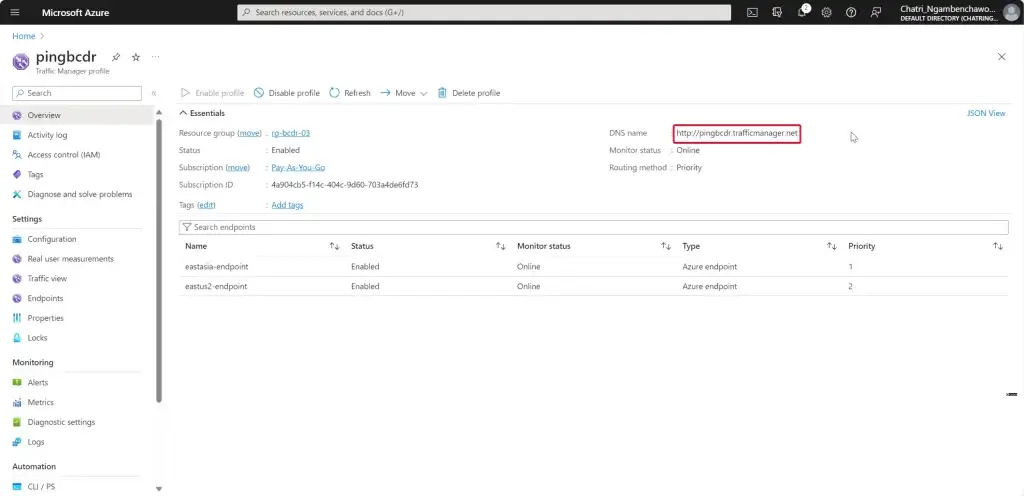
4. ได้แล้ว มันจะให้ DNS มาด้วย xxx.trafficmanager.net
5. ถ้าเข้าไปใน Profile แก้ Config ได้นะ
เข้าไปที่ Traffic Manager Profile ที่เพิ่งสร้าง เพิ่ม End Point เข้าไป
1. ถ้ากำหนด DNS แล้วมันจะเลือกได้
2. เลิอก Save
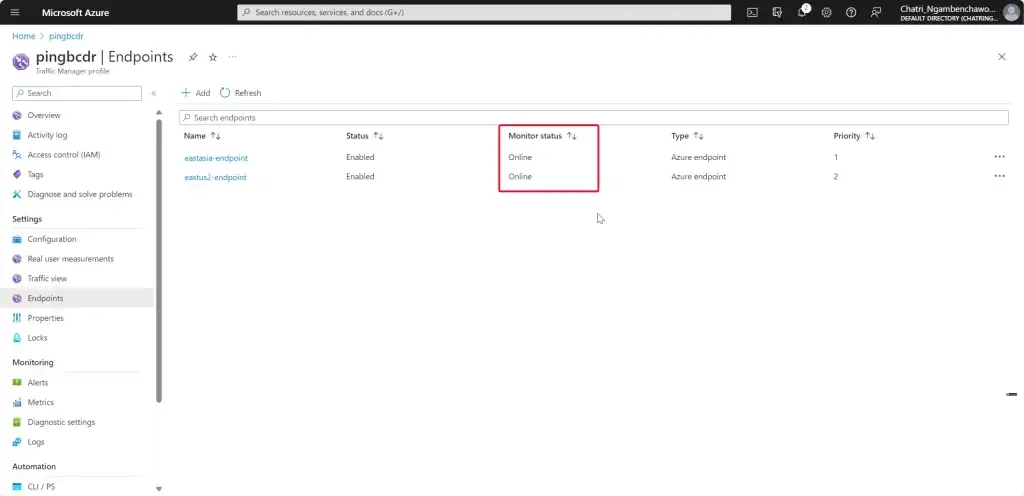
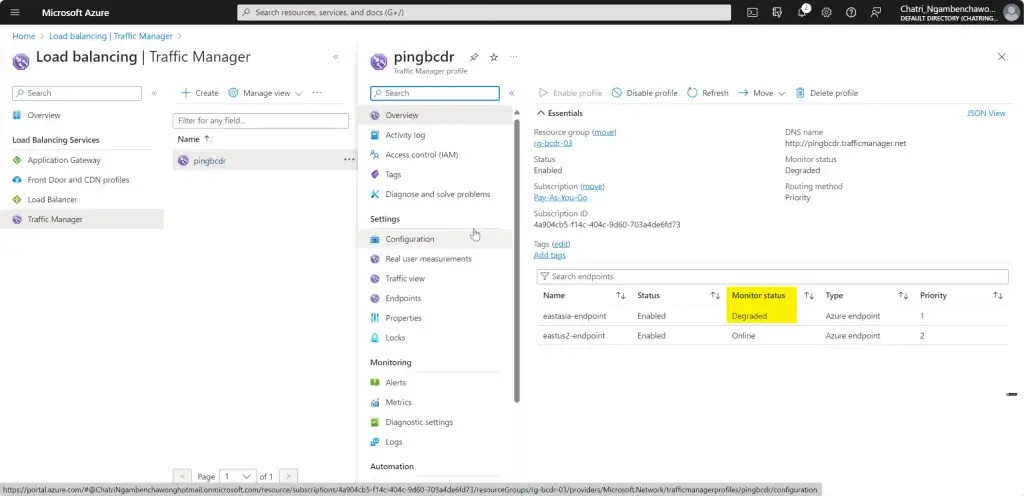
3. รอมัน Check ถ้าพังมันจะบอกเป็น degrade
4. พร้อมแล้ว
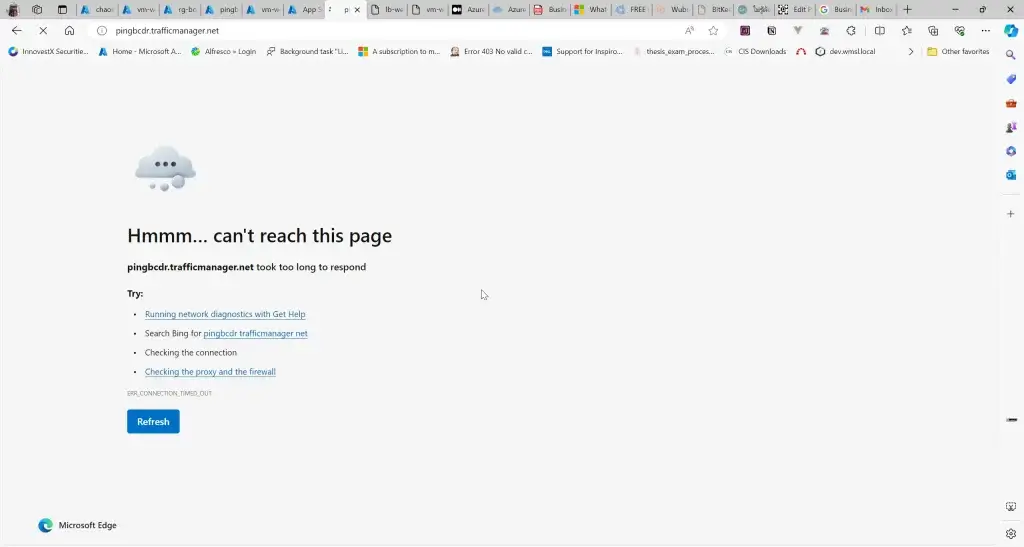
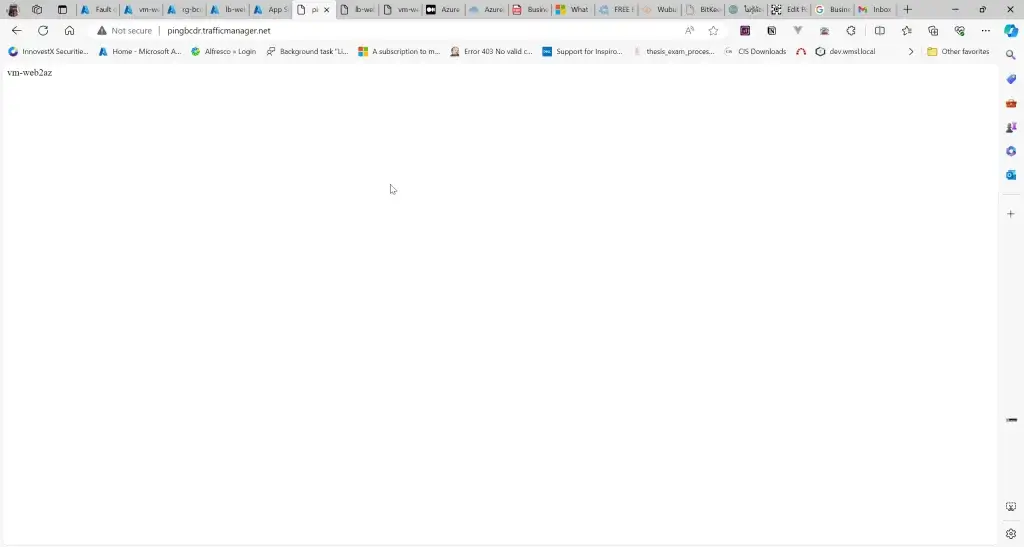
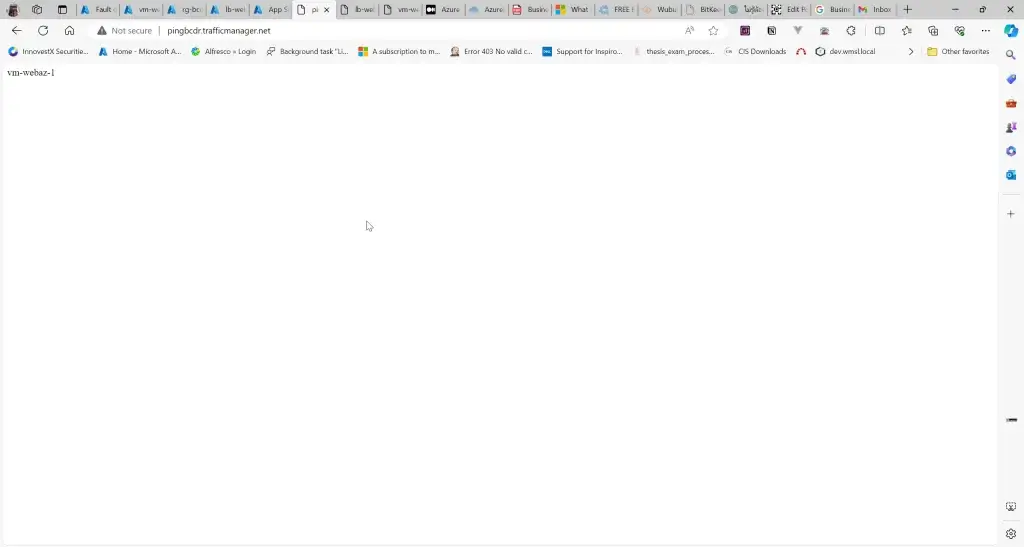
5. ลองเข้าตาม DNS
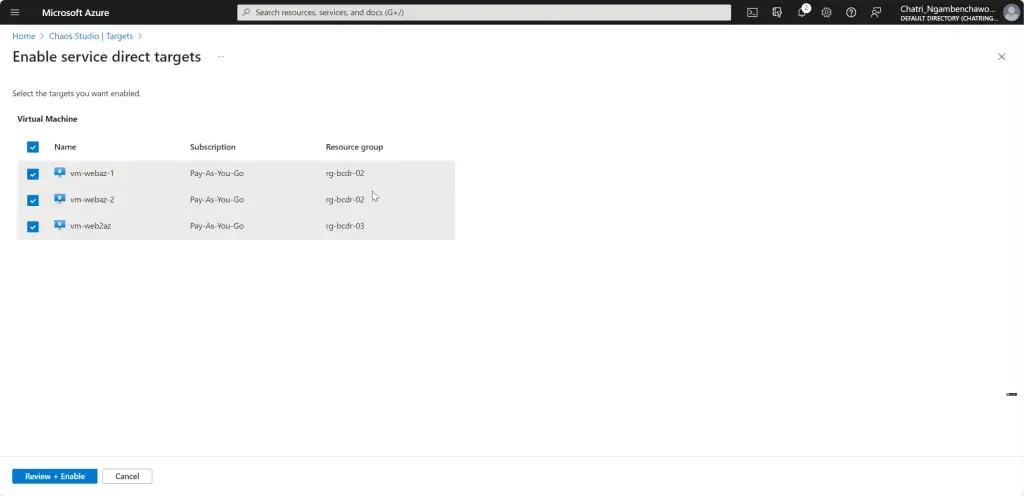
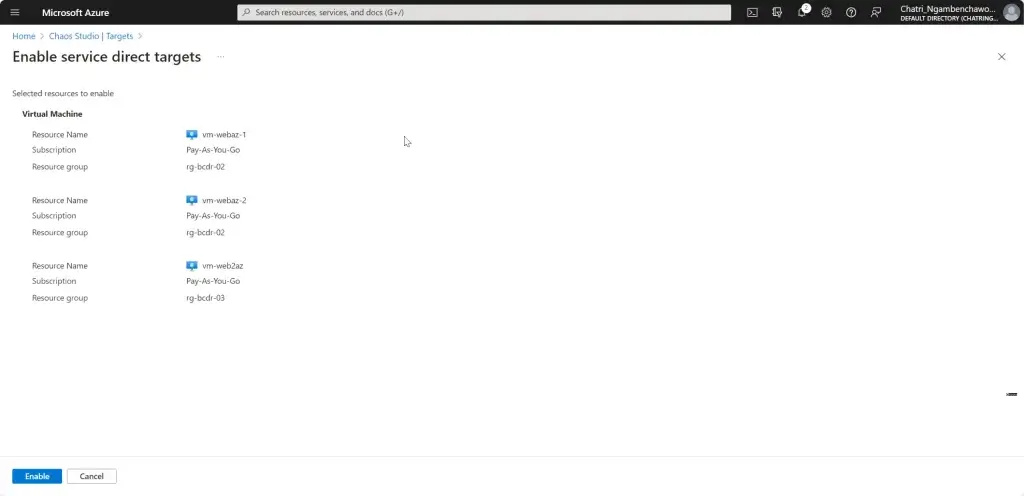
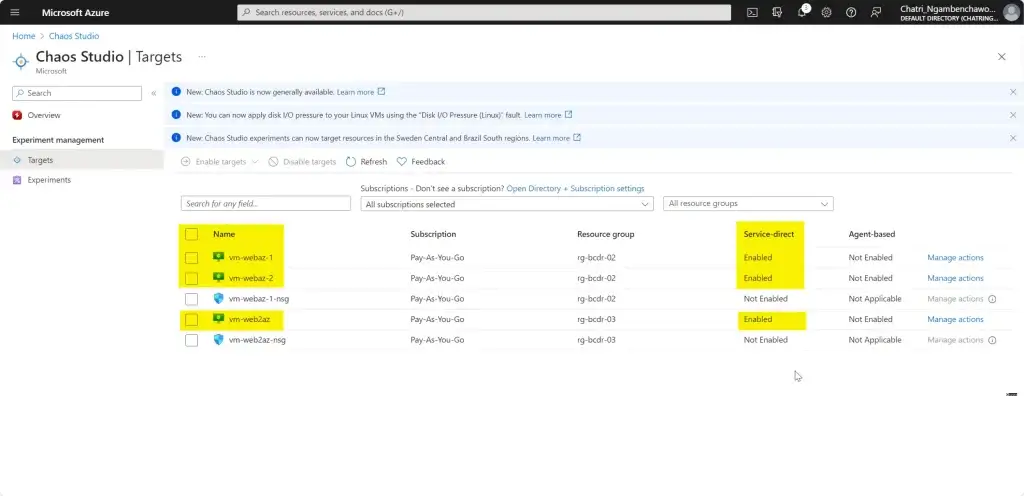
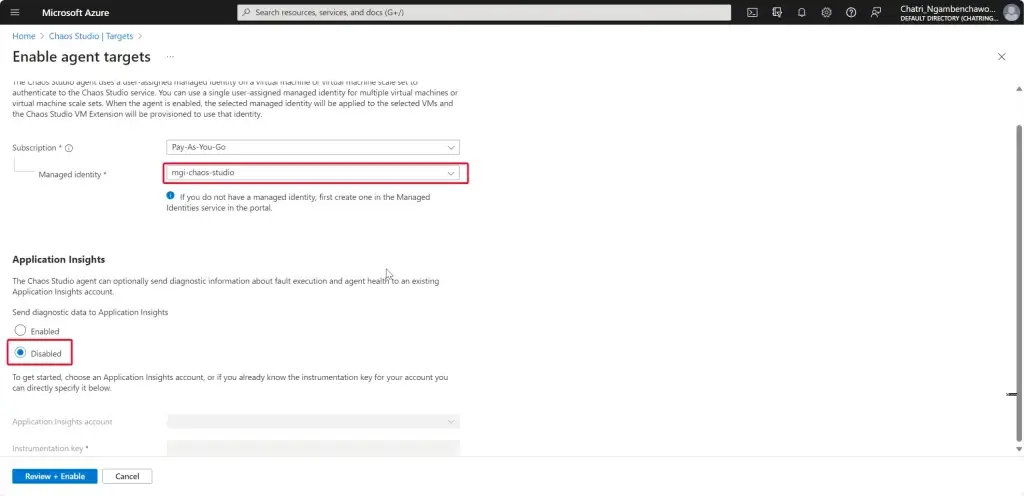
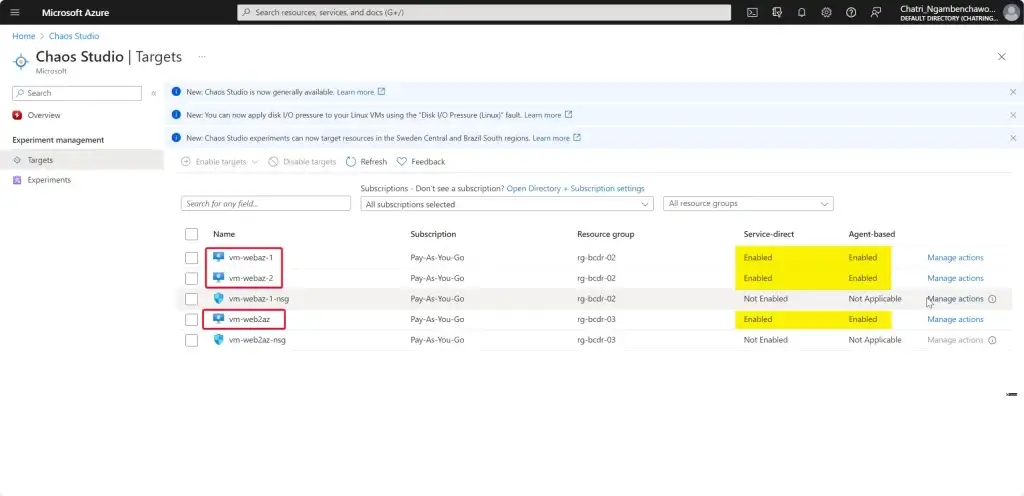
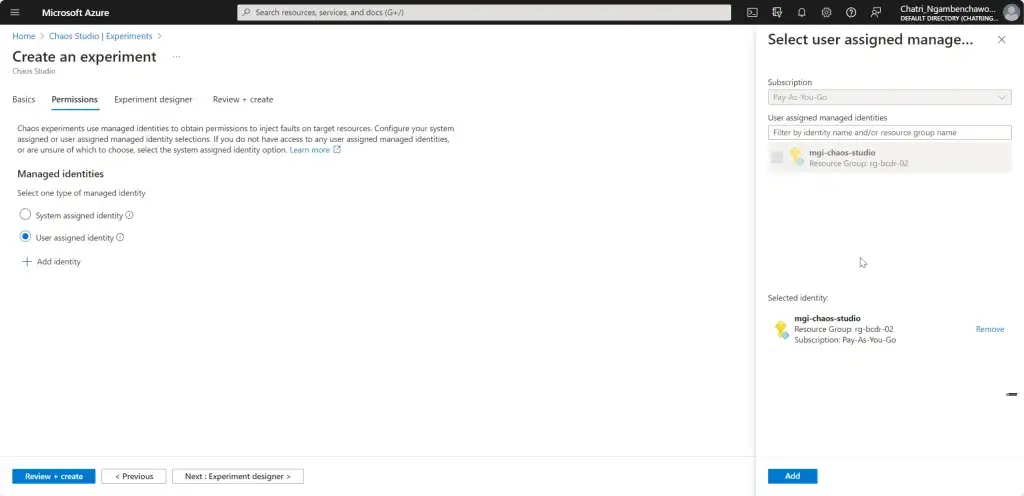
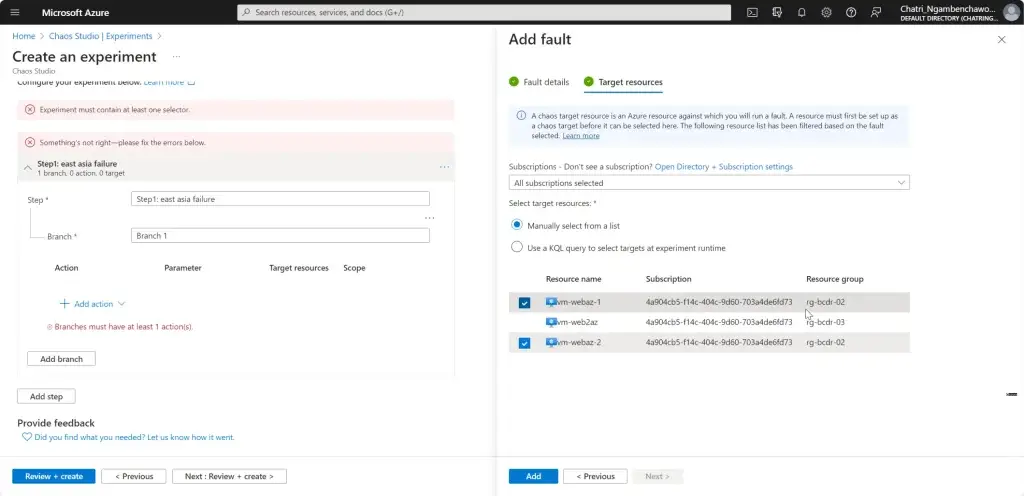
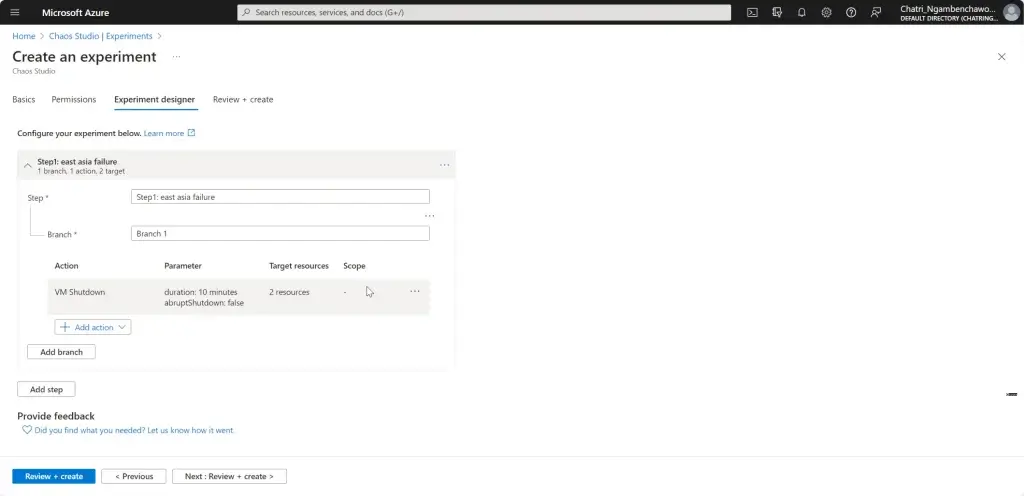
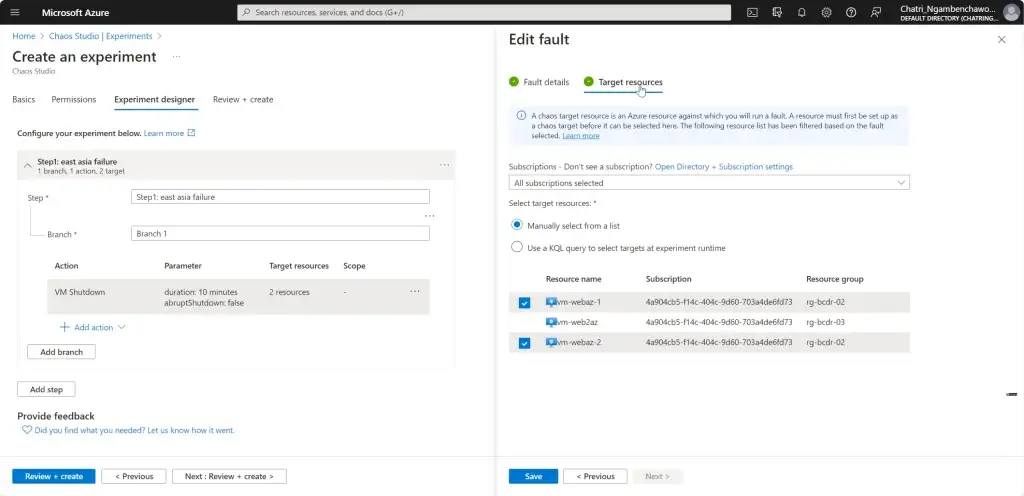
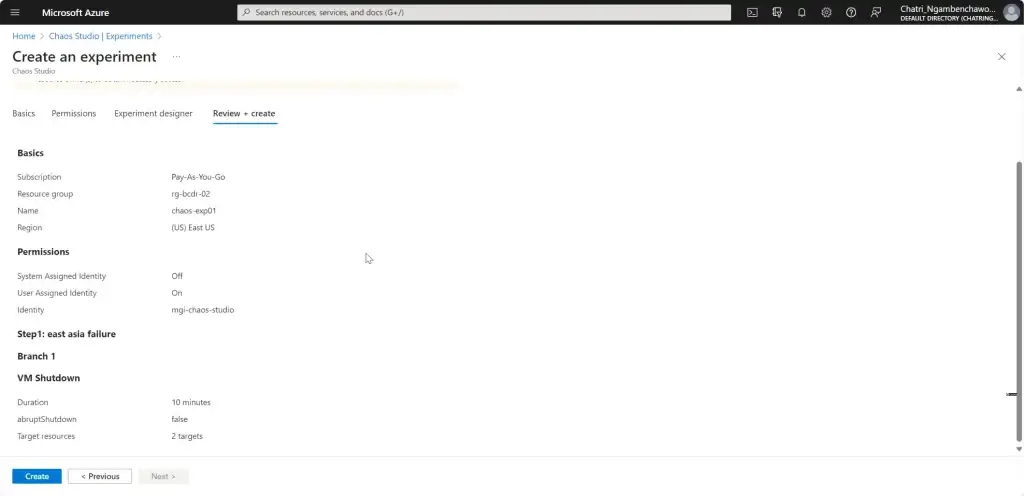
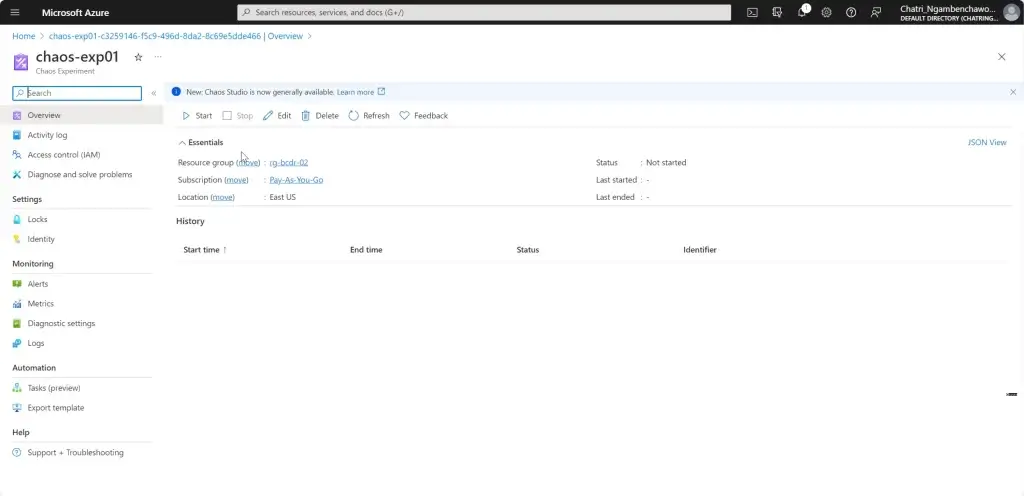
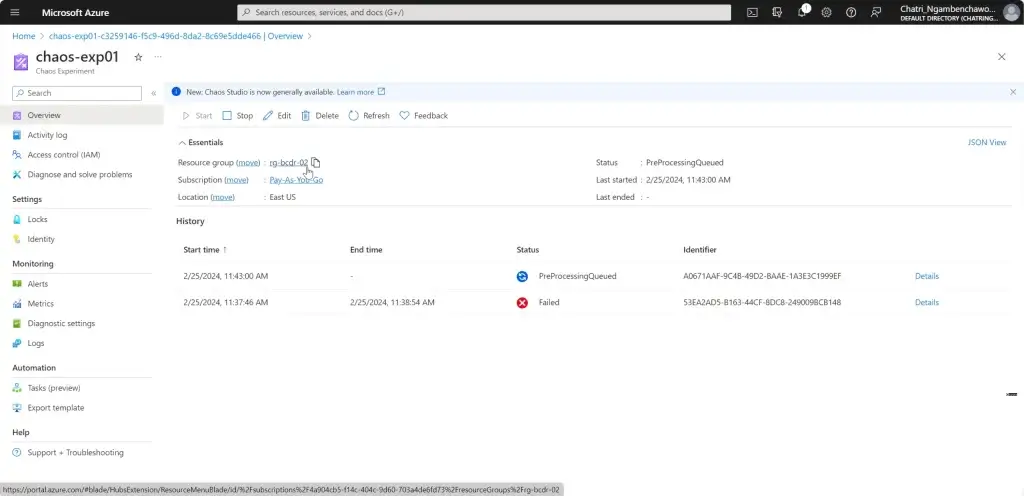
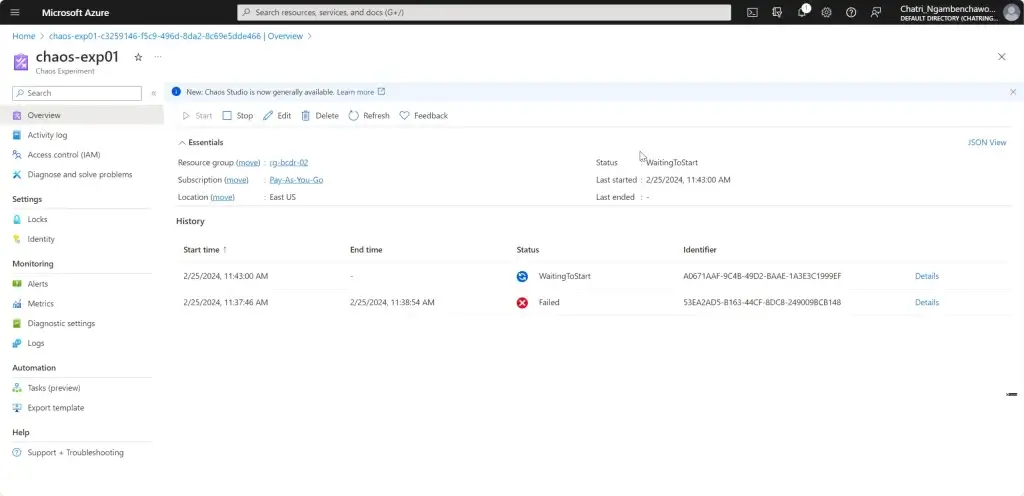
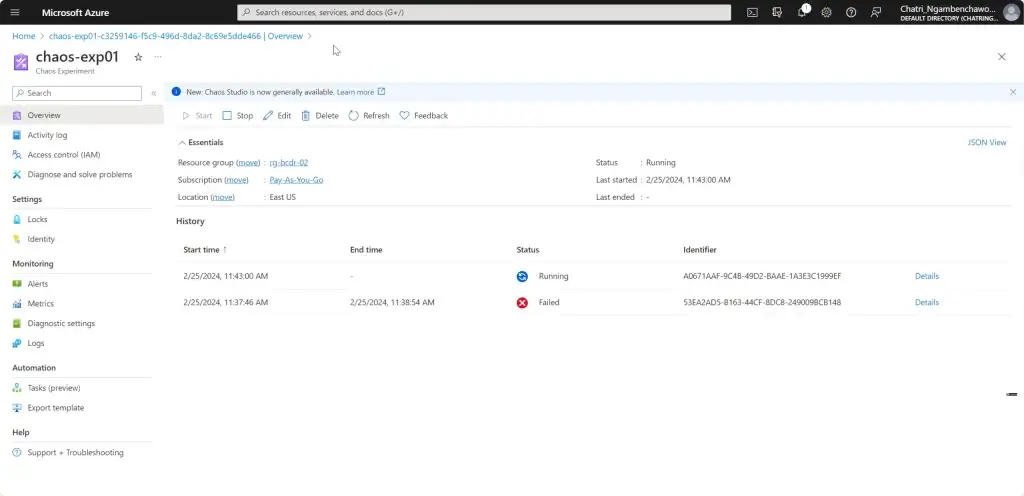
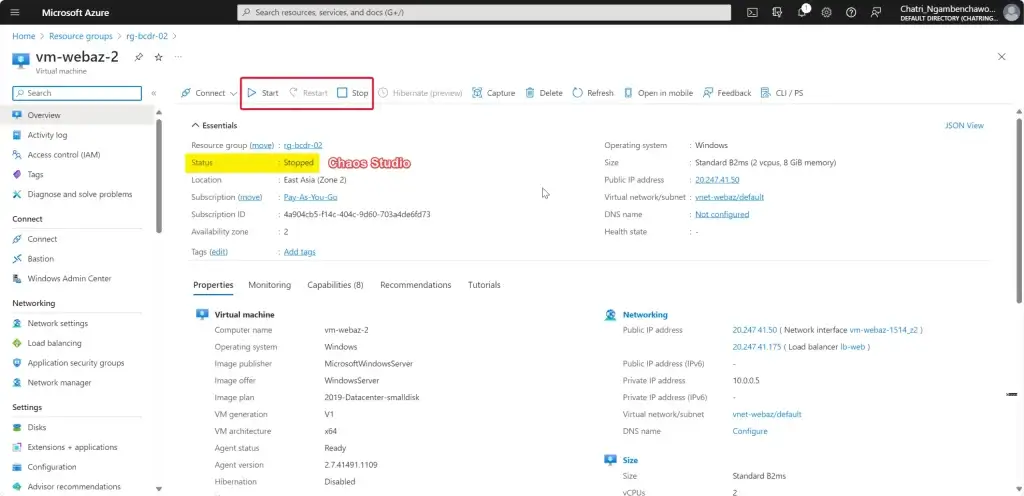
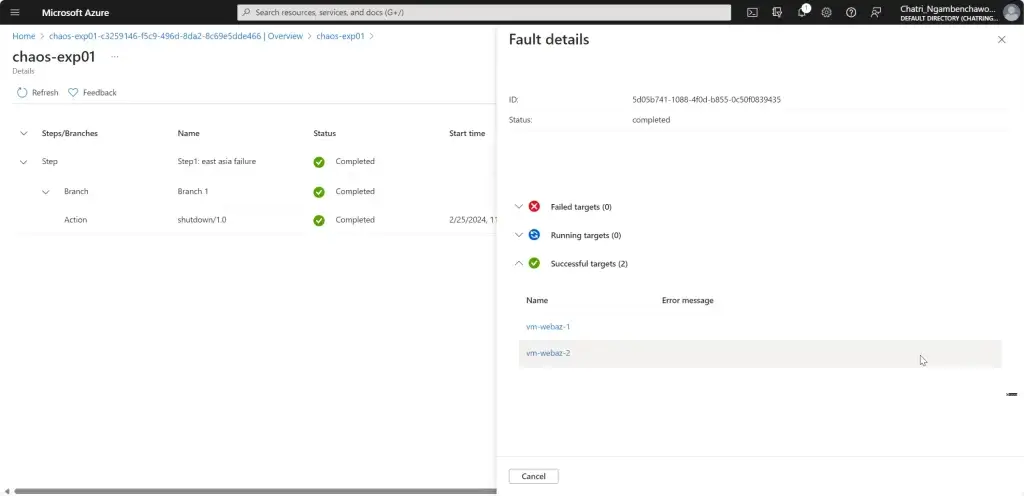
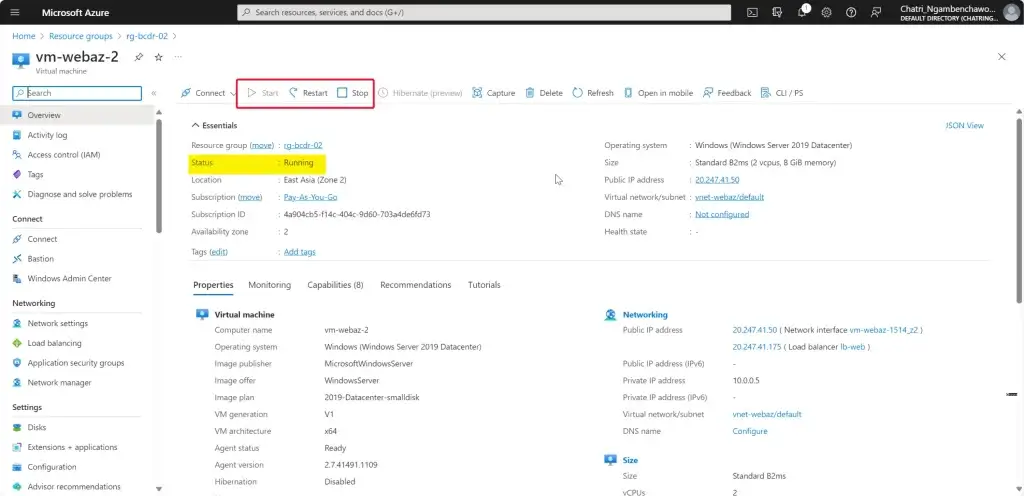
การทดสอบ สามารถลองปิด VM Main Region หรือ จะลองตัว Azure Chaos Studio
- Azure Chaos Studio
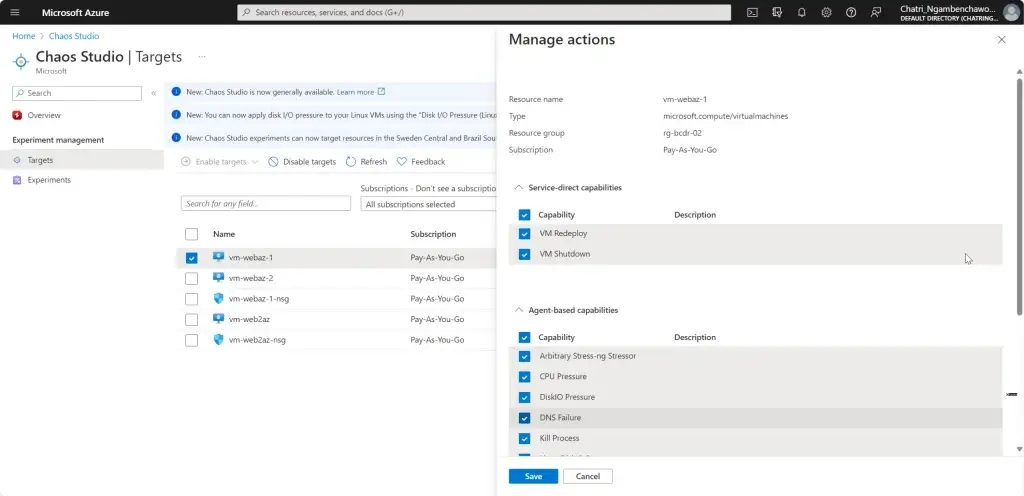
Manage Service สำหรับทำ Chaos Engineering ตอนนี้ยังใช้ได้กับาง Service VM / App Service เป็นต้น
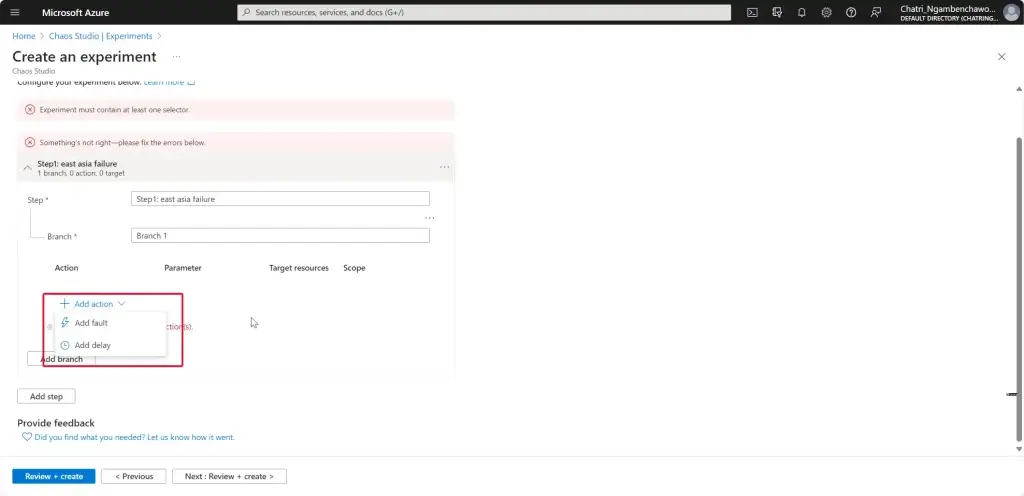
Chaos Engineering ทดสอบในระดับวิกฤติ เพื่อมาปรับ application + service resilience โดย - Reproduce an incident that affected your application - ทำให้พัง แล้วดูว่า app ตอบสนองยังไง เช่น จองบัตรคอน - Do business continuity and disaster recovery - Run high-availability drills - Develop application performance benchmark - Run stress tests or load tests.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.