สัปดาห์นี้ทาง Jumpbox มีเชิญ Speaker เข้ามาเล่า+แบ่งปันประสบการณ์ให้คนที่เรียน Cloud Camp รอบนี้ โดยมีหัวข้อ ดังนี้
Table of Contents
Introduction to NET Aspire
- Old-Way
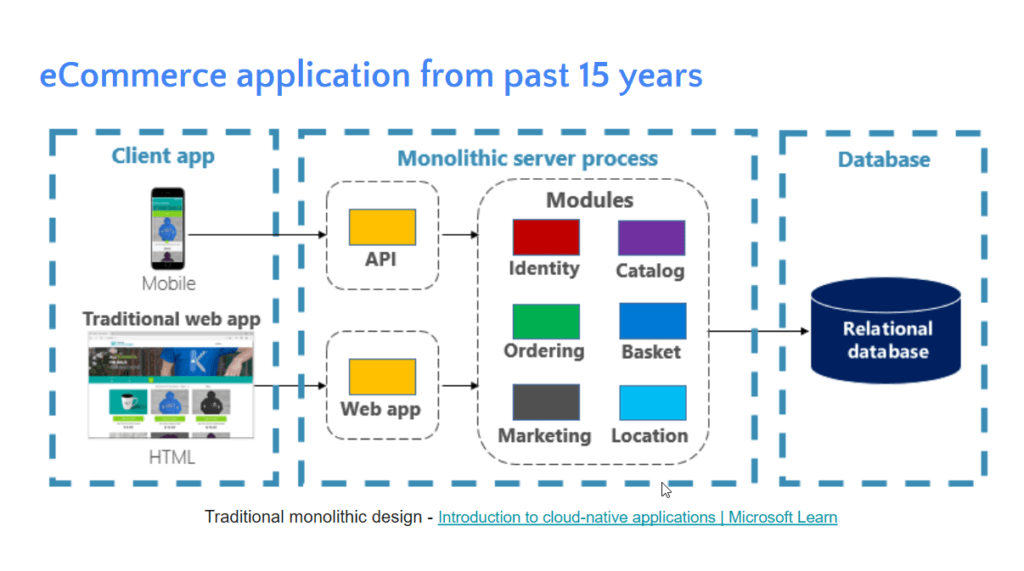
- ข้อดี มันเร็ว และ Call ได้ไวสะดวก
- ข้อเสีย
- Monolith Hell - ระบบมันโตขึ้นจน Code ของแต่ละ Service พันไปทั่วไม่มี Bounnadryชัดเจน / ใช้เวลาเรียนรู้เยอะ
- Cognitive Load
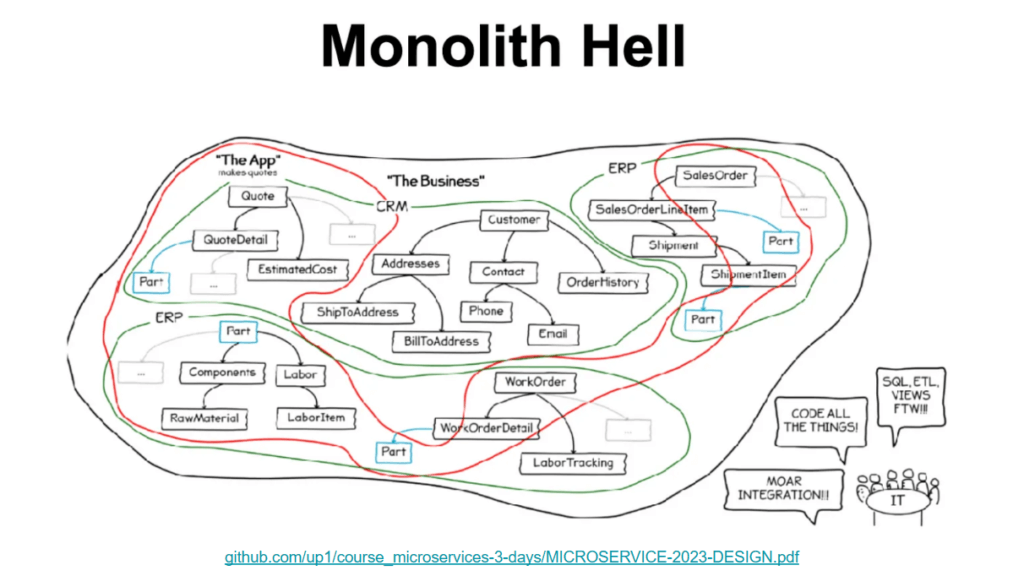
- New-Way - ปรับยังไง
- High Cohesion (อะไรกลุ่มเดียวกัน จับกลุ่มไว้) แล้ว Loose Coupling (ให้ Service คุยกันผ่าน เส้นทางเดียว)
Coupling & Cohesion สามารถดูได้จาก Blog ผมครับ Cohesion VS Coupling | naiwaen@DebuggingSoft ใช้ได้ตั้งแต่ Class > Microservice เลย
- Cloud Native - Design App for Cloud / Fast Requirement Change / Scaling ถ้าทำ High Cohesion / Loose Coupling มันจะยึดหยุ่นงานเปลี่ยนแปลง เอาตัวไหนก่อน ใช้คนละ Stack โดย Key Container / Automation / Backing Service / Resliance / 12 Factor
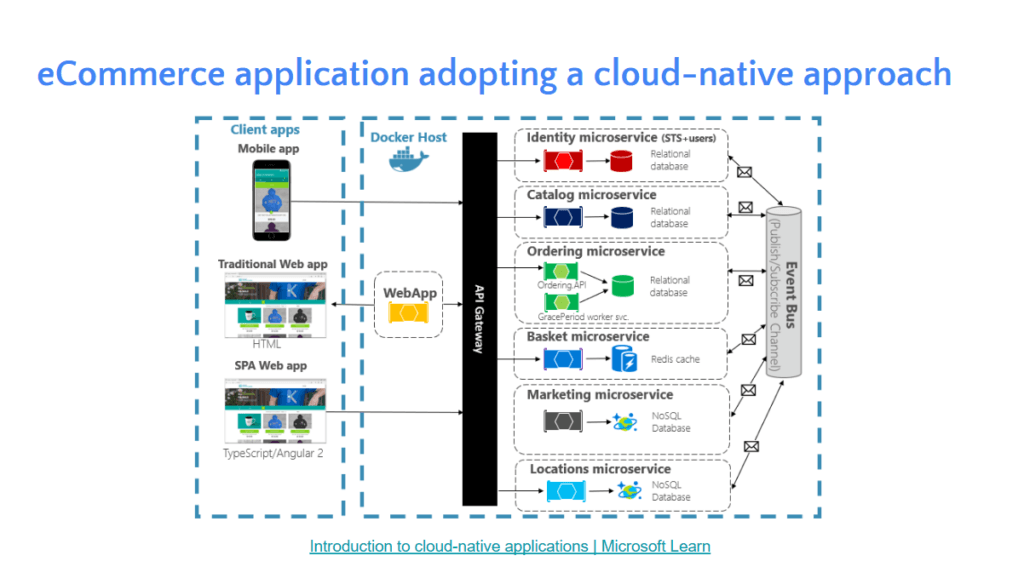
- ตอนนี้ระบบจะเป็นตัว Distribute Application แล้วนะ
- แยกย่อย จากเดิมที่แต่ละ Service มาคุยกันตรงๆ เอา Event Bus มาช่วยลด Coupling โดยเป็นการสื่อสารแบบ Async
- API Gateway ทำให้ Front รู้จัก End Point เดียว
- Sync / Async
- แยกแล้ว
- เราจะรู้ได้ยังไวว่าทั้งระบบทำงานได้ตามปกติ
- Roll-Back ถ้าเกิดปัญหา เช่น A -> B ยังไง SAGA-Pattern มาแก้อันนี้ แต่ต้องคุย Flow ให้ดีเคส Happy Flow / Alternative Flow - จากปัญหาข้างต้น จะแก้ยังไง
- Resiliency Strategy
-> Timeout / Circuit Breaker / Retry Attempts
-> dotnet Lib polly ช่วยเรื่องนี้
- Observability - Metric / Tracing / Log Aggregation / Service Discovery (ดูว่าบริการไหนพร้อมใช้)
-> LGTM Stack + Open Telemetry
-> dotnet Aspire
- dotnet aspire
- NET Aspire = Set Template ที่เตรียมไว้สำหรับ Cloud Native App
- Require NET8.0 / NET Aspire Workload / Container (Code + Backing Service) / IDE (VS2022 / VSCode)

- Sample Project + Role
- ApiService - ตัว We
- AppHost - ทำให้ Backing Service แต่ละตัวมาคุยกันได้ ApiService / Web
- ServiceDefault - พวก Common resilience / service discovery / telemetry
- Web - Blazer UI
ความเห็นส่วนตัว
- ไม่ต้องทำ Obserability + Infra แล้ว + มี Dashboard ให้เลย แต่หุ้มแบบน่ากลัวเหมือนกัน Code สร้าง Container ถ้าพัง แล้ว Fundamental ไม่แม่น น่าจะงงได้
- ใน NET8 ที่พวก Obserability มันใช้ Dependency Injection เข้ามาได้เลย ไม่ต้องมาใส่ IDisposable เอง //เหตุผลนี้เลยขยับ NET6 > 7 > 8 ตอน Project 555
ข้อดี มันมีของให้พร้อม UI / Backend / Resiliency + Observability เลย อยากได้ Stack ไหนเขียน Code เอา เช่น อยากได้ RabbitMQ ก็ Add มาเดียวตอนรันมันไปทำ Infra ให้
- คำถาม
- ถ้ามีหลาย API Service เช่น order api / identity api / compliance api มันต้องเอามา Ref ที่ AspireSample.AppHost หรือป่าว เข้าใจว่าเป็น Startup Project จับความสัมพันธ์ของแต่ละ ms
Ans ใช่ - ถ้าสั่งบิ้ว จาก CI/CD มันจะได้ Container 1 ตัว หรือ n ตัว หรือ ตามประเภท Root Project
กลุ่ม API / กลุ่ม Web / กลุ่ม Dashboard / ประมาณนี้
Ans รอ Release ตัวเต็ม - จากข้อ 2 เห็นมีสร้าง Container มาด้วย ตรงนี้มันจะสร้างพวก docker compose / deployment ด้วยเลยไหมครับ
Ans รอ Release ตัวเต็ม - Project เดิม NET5/6 Upgrade NET8 มา Aspire Ref Nuget แล้วใช้ได้เลย หรือป่าว หรือ ต้อง Refactor Code
Ans ได้ - ถ้าใช้ LGTM Stack ปิด Dashboard ได้ไหม ใช้เฉพาะตอน Dev
Ans ทดแทนได้เหมือนกัน - พวก SeriLog ยัง Config เหมือนเดิม ใช้ json /code หรือป่าว ?
Ans ใช้ได้เหมือนเดิม
ปิดท้ายและ
เรามีการออกแบบวิธีเทคนิคเพื่อมาแก้ไขปัญหา แต่การแก้ไขปัญหานั้น ก็จะมีปัญหาใหม่ตามมาเช่นกัน ดังนั้นให้เราเลือก สิ่งที่เหมาะสมให้กับ architecture ของเรา
Resource: T-T-Software-Solution/dotnetaspire (github.com) / Slide / .NET Aspire overview
How to Build an Observability System for Microservice
- microserice = แยก Logic / DB ออกมาย่อยๆ เพื่อจัดการได้สะดวก ดูแลง่ายตอนเกิดปัญหา คุยกันโดยตกลงผ่าน API
- observability - ให้เรารู้ตอนนี้เป็นอย่างไร โดยมี 3 Pillar : Log - ทำอะไร / Metric - ข้อมูลสรุป / Trace - บอกการไหลของ Request ระหว่าง microservice
- ตอน Design App สิ่งที่ต้องทำ
- Infra - รองรับ Load / Security / Maintenace / Network /
- Platform - รองรับการ Deploy App รองรับการ Scale ไหม ในชั้นนี้พวก K8S / ค่ายอื่นๆ อย่าง Docker Swarm เป็นต้น
- Application - เลือกภาษา Framework ให้ตรงกันงาน
- Service Operation - เอาไว้จัดการให้ยั่งยืน ตัว observability มาตอบตรงนี้ จะได้รู้ว่าตาย แล้วจะกลับมายังไง
- observability stack
Key - Service ที่ดี อาจจะไม่ได้วัด Feature ที่ว้าวๆ เสมอไป มันมีอีก Factor ถ้าพังแล้ว จะแก้อย่างไร และป้องกันได้ (Prevention) โอ้ยนึกถึง MyAIS
- 6 Observability Pattern for Microservice
- Provide Health Check API
- Log Aggregation - Log มันมาเยอะ เราต้องจัดการให้ง่าย ทำ Centralized Logging ดูที่เดียว และจัดกลุ่มให้ชัดเจน
- Distributed Tracing - Observability Tracing
- Application Metric - บอกข้อมูลของ App เอง นอกจากพวก Infra แล้ว
- Exception Tracking - ตั้ง Alert / Threshold เตือน
- Audit Logging - System มีอะไรเปลี่ยนแปลงบ้าง
- Observability Tools เน้น Log / Trace / Metric)
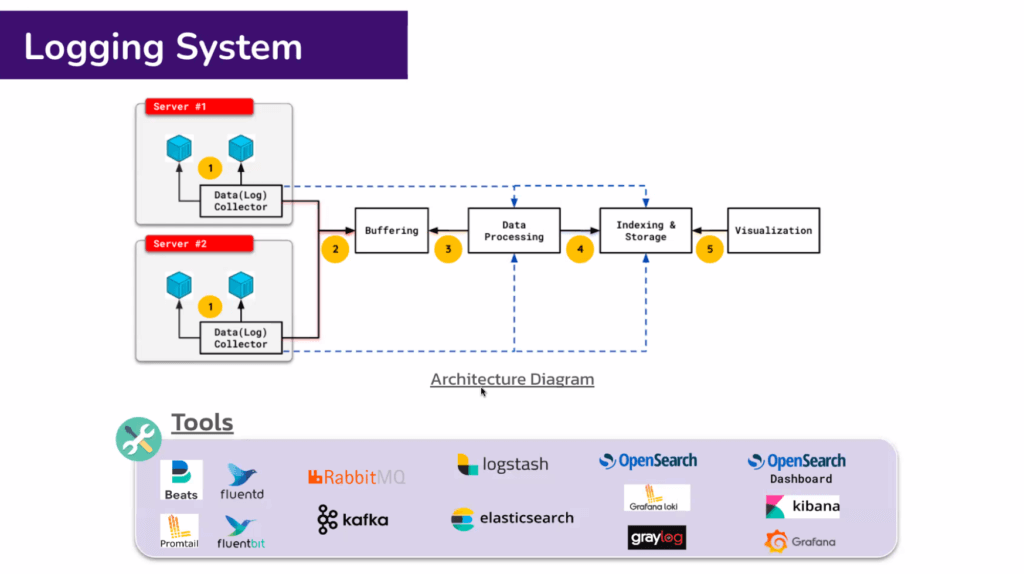
Logging System ประกอบไปด้วย
- Collector
- Buffering ระบบใหญ่ๆ พวก Queue RabbitMQ / Kafka
- Data Processing - Parse Log ตัดที่ไม่ต้องการ Data Pipe ไปฟัง
- Indexing / Storaging
- Visualization
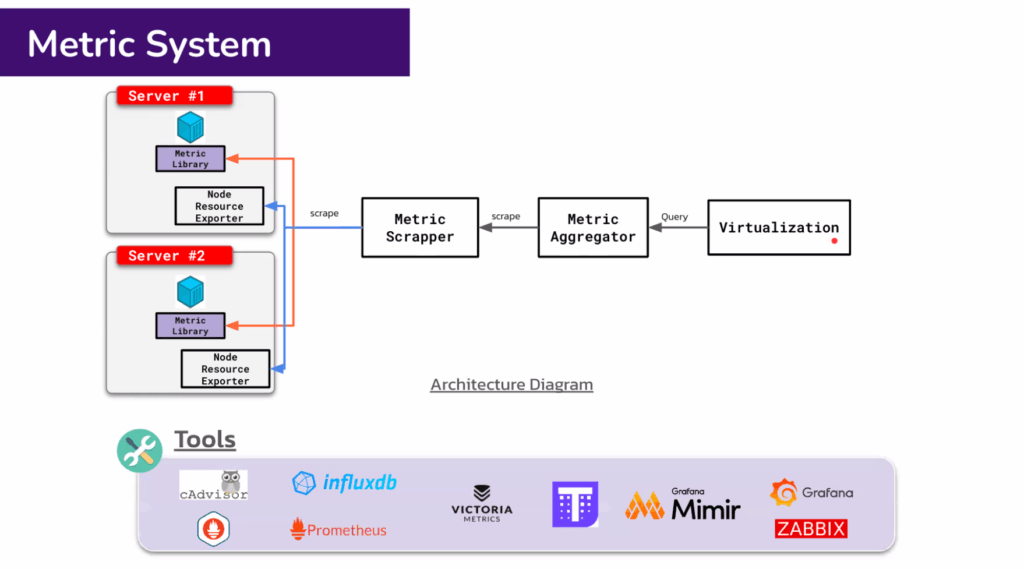
Metric system ประกอบไปด้วย
- Resource Exporter มาจาก Metric Lib ต่างๆ อย่างของ Opentelemetrt / Node Exporter ดึงข้อมูลที่เราต้องการไปให้ต่อ
- Metric Scrapper - ดีงตัว Metric
- Metric Aggregator - เอามา Preprocess
- Virtualization - นำเสนอ
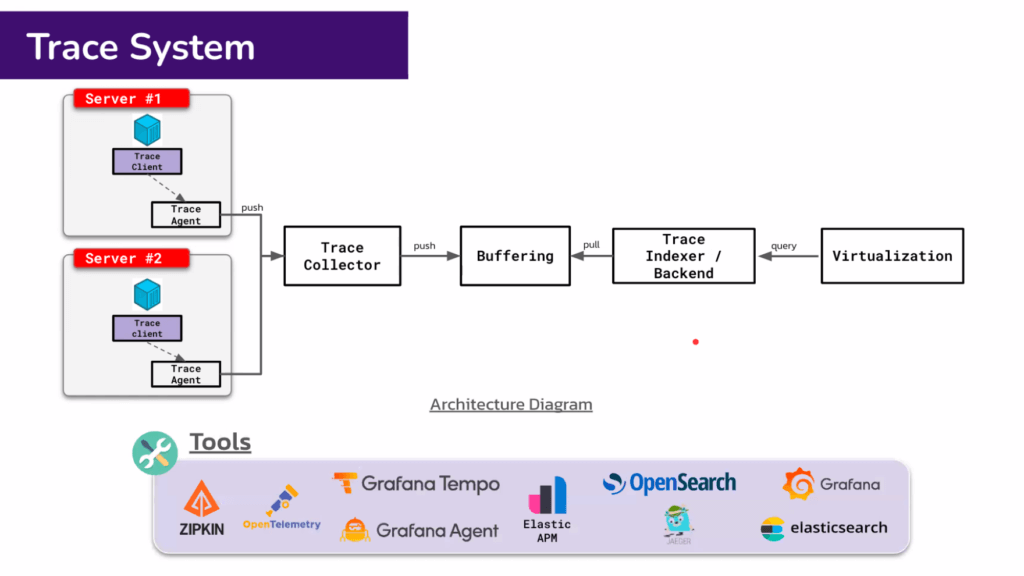
Trace System ประกอบไปด้วย
- Trace Agent
- Trace Collector - Otel Collector / Grafana Tempo
- Buffering - เหตุผลเดียวกับ Log
- Trace Indexer / Backend - DB เช่น Elastic APM / OpenSearch / Jager
- Virtualization
- Use Case & Practices
Log & Trace
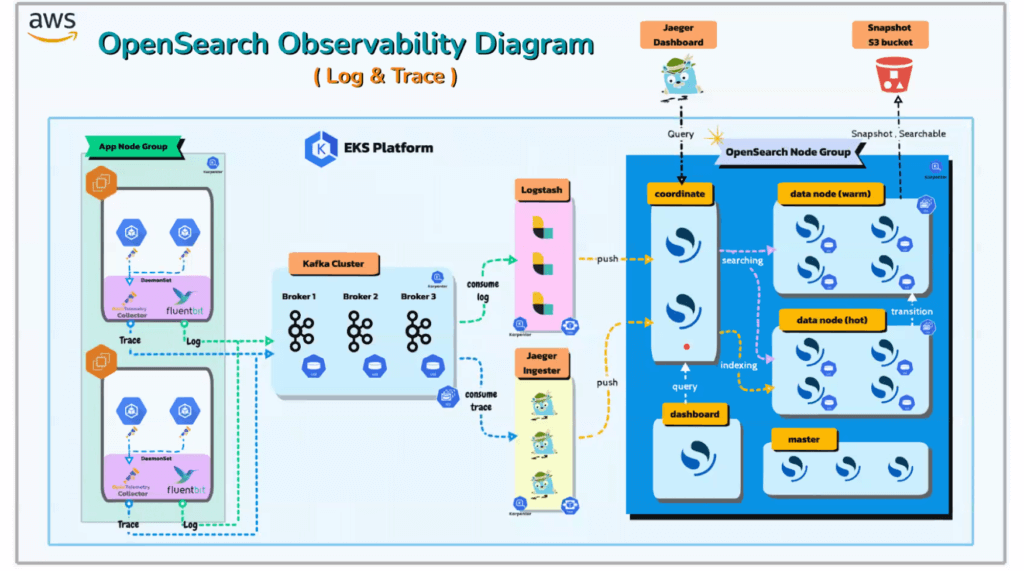
- App
- Lib ของ Open Telemetry โดยบางอย่างตัว Lib จะทำให้แล้ว Auto Instrumentation
- Fluent Bit - DaemonSet stream log แต่ละ Container
- OTEl Collector เก็บ Log - Buffering - Kafka -เอามาคั่นเพราะตัว Backend รับไม่ไหว Scale แล้ว ไม่คุ้มเลยเอา Queue มาคั่นไว้
- Data Processing (Pull Mode ดึงไปทำ) Logstash / Jaeger Ingester
- Backing + Indexing ใช้ Open Search แยก endpoint ตาม
- coordinate (มี Cache) / node data warm / node data hot เพื่อความรวมเร็ว
- snapshot + searchable - ลด node data warm / node data hot เพราะเก็บนานยิ่งแพง ดูจาก snapshot ย้อนหลัง ตัว searchable เดิมต้อง restore แยก เพื่อดู ตอนนี้ไม่ต้องและ
ทั้งหมดอยู่บน K8S มี hpa + health recover model ให้ในตัว
Metric
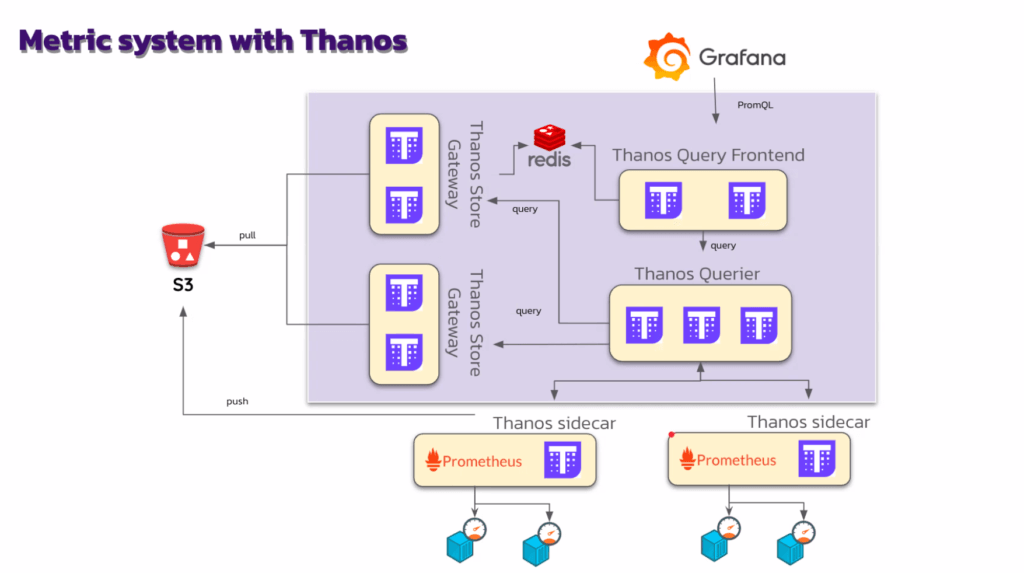
- Prometheous Scale ยาก เลยปรับ Stack ตามนี้ ตอนแรกมีตัวเลือกไว้หลายตัว Thanos, Mimir, Victoria เลือก Thanos จาก Know how คนในองค์กร โดยที่
- Data Source Promethoue ยังอยู่ + Thaous Sidecar
- Thaous Fronted บอกว่า Log ควรดูที่ไหน S3 / Redis / SideCar
- นอกจากนี้ตัว Querier ยังต่อกับ Open Telemetry อื่นๆ
- Next Trend
- Open Telemetry ทำให้ App Improve OBS ได้ไว เพราะเป็นมาตรฐานกลาง
- eBPF - ช่วยให้เราดู Metric Level Infra / Kernel
- Challenge
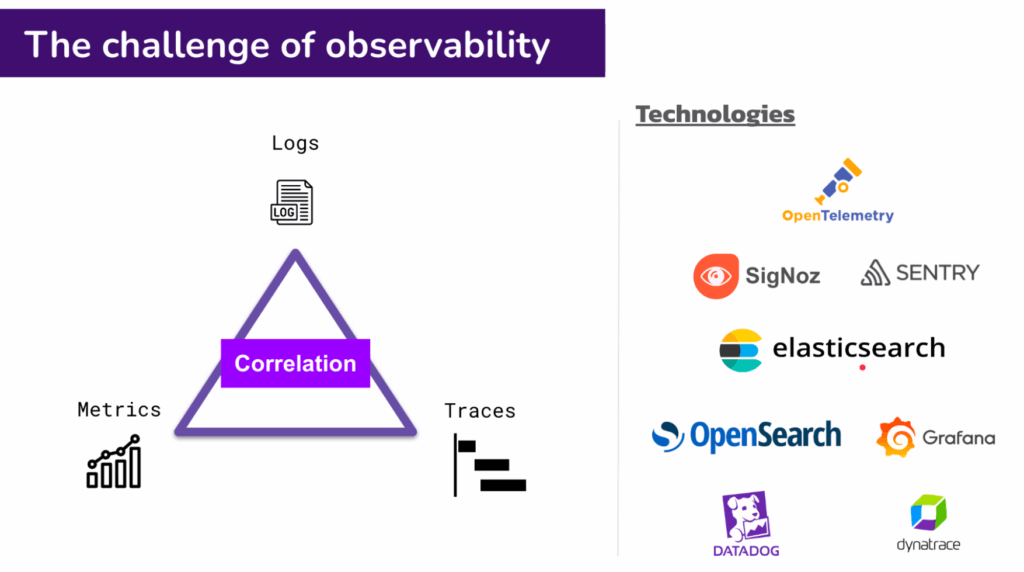
- Correlation ระหว่าง Log / Metric / Trace
- APM + Observability Tools
Open-Source:
- SigNoz ตอนทำ Project เจอ Code Sample ในนั้นเยอะเหมือนกัน อันนี้ของ DOTNET
- Sentry
- Open Search - Fork มาจาก Elastic Search
- Elastic Search โดย Stack ที่นิยมมี 2 กลุ่ม
>> Elasticsearch, Logstash, Kibana Stack
>> Elasticsearch, Fluentd, Kibana stack
- Grafrana - Loki Grafrana Tempo Mimir Stack
- Zabbix - เหมือนจะได้ยินนะ
Commercial: - Datadog / dynatrace
observability for improve customer experience > troubleshooting
- คำถาม
- ปกติ Log App ออกมาไฟล์เดียวรวมทุก Level หรือแยกไฟล์ตาม Level Info / Warn / Error ครับ
ปัจจุบันทำแยกไว้ เลยไม่แน่ใจว่า ถ้าเอามาใช้กับ observability มันแปลกไหม เมื่อเทียบกับชาวบ้านครับ
Ans ให้ Log ออกมา ที่เดียว แล้วค่อยให้ แต่กำหนด Pattern ให้ชัดเจน จะได้ Parsing / Virtualize ได้สะดวก
<timestamp> | <log status> | <traceid> , spanid | <msg>
- อยากถามว่ามันมีเส้นประมาณไหนครับว่า ถ้าใช้ monthly cost ประมาณเท่าไรถึงควรเอากลับมาเป็น on-primise
Ans Cloud First Scale ง่ายสะดวก เอา Observability มาให้เห็น Cost แล้วคุม - มี best practice สำหรับวาง infra ไหมครับ?
Ans ไม่ได้ Pattern ที่แน่นอน ต้องมีคนสวมหมวก Infra Architecture ที่เข้าใจ Context งาน ใน Use-Case นั้นบน Cloud / On-premises แล้วปรับจูนให้เหมาะกับสถานการณ์จริง - Cutting edge ตลอดไหมครับ หรือว่ามี period ว่าจะต้องอัพเกรททุกๆเท่าไร แล้วถ้าเลือกที่จะเปลี่ยน ใช้อะไรตัดสินใจว่าต้องเลือกตัวนั้นครับ + ใช้เวลา research นานไหมครับกว่าจะตัดสินใจ
Ans เมื่อถึงข้อจำกัดของ Stack นั้นๆ ในเคส Sesion นี้จะเป็นตัว Prometheous > Thanos
เพราะต้องดู Improve / Impact / Know-How ถ้า Impact น้อย อาจจะขยับเลย แต่ถ้าเยอะ อาจจะเป็น Optional แยก Cluster + Stack มาลอง - ใช้ Open sources มีความเสี่ยงเรื่อง zero day ไหมครับ
Ans มีอยู่แล้ว แต่เลือกที่ Active จะได้ Patch ไว / และเอา Tools Sec มาปิด
Project Pitch
วันเสาร์มีนำเสนอ Project ของแต่ละกลุ่ม นำเสนอ Business / Tech สรุปตาม Archtitecture ได้ ประมาณนี้
- Arch: Frontend / Backend / Database
- กล่ม Bank of JumpBox (Jam Nam) - จำนำ ใช้ DOTNET8 นะ มีทำ OBS ด้วย
- กล่ม JB Market - ตลาดแลกซื้อสินค้า - Arch: Frontend / Backend / Database / Cache (Redis)
-กลุ่ม TางประJump - แยกหลาย MS อยู่นะ มีพวก Mongo / Neo4J สำหรับ Route เส้นทาง - Arch: Event Driven + หลาย Microservice นอกจาก Frontend / Backend เรียกว่าแยกตาม Business Domain และกัน
-กล่ม Shopที่ไปอะไรสักอย่าง กลัวเขียนผิด 55 เป็น Event Organizer อย่าง Event Pop มีใช้ RabbitMQ
-กลุ่ม Paybox เป็น payment gateway
>> แต่ละ Microservice ยิง Event ตรงเข้าแต่ละ Service เลย ถ้ามัน Load เยอะ เอา Queue มาเข้า
>> CI / CD มี Reusaable Workflow ช่วยลด Pattern ซ้ำๆที่มีในหลายๆ Microservice ได้
-กลุ่ม Lotto Pub-Sub By Redis ลองเล่นแล้วแล้วโดนแดรก 555
Key เลือก Arch ให้เหมาะกับ Business และช่วงเวลาการเติบโต
Keyword อื่นๆ
- Release Process - ข้อมูล Report QA / Security Team บอกพวก CVE / Perf Test ก่อนตัดสินใจ Go / No Go
- Observability Golden Signal - Request/Sec, Request Error, Latency, Connection accept จะได้ไหวตัวทัน ก่อนจะมีเคสจริงๆ
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.