Week นี้ merge จบแล้วมั้ง สำหรับการ Merge ที่ใช้ Resource แบบเยอะมาก และเวลาประมาณ 2 Week จากงานเข้าใน Blog ตอนก่อน ใน Week นี้ระหว่างเก็บงาน Merge ฟังที่เรียนไปด้วยครับ โดยจะมีหัวข้อ ดังนี้
Table of Contents
Observability
Observability = Observe(การสังเกต) + ability (ความสามารถ)
Observability = ความสามารถในการสังเกต ต่อยอดมาจากแนวคิด Control Theory ที่ติดตามสิ่งที่สนใจให้อยู่ในสภาพที่พร้อมใช้ (Desire State) จาก Output ทื่มันบอกมา อาทิ เช่น พวก Metric ยกตัวอย่างรถยนต์ มี Speed Meter / Engine Temperature เป็นต้น เพื่อให้รู้พฤติกรรมของระบบ (behavior of the system)
มุมของ IT ตัว Observability เอามาใช้ autoscaling แต่การทำเรื่องนี้ต้องรู้สถานะของระบบก่อน (keeping track) ในตอนที่ Load เยอะ หรือ ตอน Error
ถ้าอยากรู้ว่าเราต้องเอาตัว Observability มาใช้ไหม ให้ดูจากคำถามของ CNCF Guideline/Measure ตามนี้
- Is the system stable or does it change its state when manipulated ?
- ถ้ามันมีการเปลี่ยน state ระบบมันรู้ แล้วแจ้งเราไหม เช่น 404 เยอะๆ - Is the system sensitive to change, e.g. if some services have high latency ?
- high latency - ตอบสนองช้า เช่น มี request มาเยอะ หรือ pod resource เต็ม - Do certain metrics in the system exceed their limits?
- เก็บข้อมูล และต้องรู้ Limit ที่เราต้องกำหนดก่อน อาจจะมาจาก Load Test - Why does a request to the system fail?
- การวัดควรวัดก่อนระบบมันจะพังไป พวก Cloud จะเตรียมข้อมูลบางส่วนให้อยู่ เพื่อเราจะได้แก้ไขถูก เช่น Implement
➡️ Circuit Breaker พังแล้วตัดส่วนนั้นออกจะระบบ เช่น Payment ใช้ไม่ได้ ยังทำงานส่วนอื่นได้
➡️ Bounce Case (น่าจะเขียนแบบนี้) พยายามกระจาย Load ไป เหมือนกัน เรือชนภูเขาน้ำแข็ง ให้ถ่ายน้ำลงมาห้องที่กันไว้ เพื่อให้เรือ/ระบบสมดุล - Are there any bottlenecks in the system?
- bottlenecks = คอขวด ดังนั้น ถ้ามีส่วนในส่วนหนึ่งของระบบ ที่เกิดคอขวดขึ้น แสดงว่าส่วนนั้นเป็นจุดที่ Single Point of Failure (SPOF) ถ้าพังก็ตาย
Goal: เอา Data ที่ได้มาวิเคราะห์ เพื่อตอบคำถามที่อยากรู้ด้าน Observability และทำให้เกิด feedback loops มาปรับระบบให้สอดคล้อง
CNCF Landscape V2
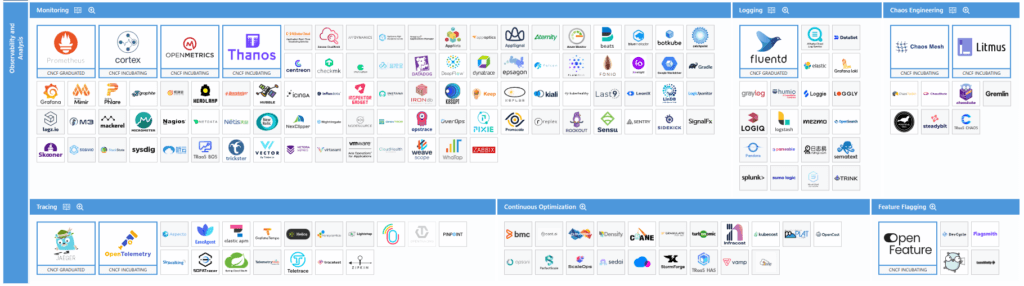
สำหรับ CNCF Landscape V2 ที่ออกออกมาแล้ว มีการจัดกลุ่มเครื่องมือสำหรับงานด้าน Observability ดังนี้
- Monitoring
- Logging
- Tracing
- Chaos Engineering - ทำให้มันพัง เราจะได้เตรียมตัวรับมือได้
- Continuous Optimization - ทำให้ Cost ที่เราใช้งานบน Cloud คุ้มค่าที่สุด มาแนวๆเดียวกับแนวคิด FinOps
- Feature Flagging - จัดการเปิดปิด Feature ผมเพิ่งรู้เหมือนกันว่ามี Tools แนวนี้ ตอนแรกเขียนเอง / ดูใน Azure ก็มี ลองไปดูมามันมี Spec กลาง (Open Standard ด้วย)
Ref: CNCF Landscape (landscape2.io)
LGTM Stack
- Loki-for logs
- Grafana - for dashboards and visualization
- Tempo - for traces
- Mimir - for metrics
Telemetry & Application Output
Application Output - สิ่งที่ระบบบอกเรา จะมี 3 ส่วน ได้แก่ Logs / Traces /Metrics
Telemetry มาจากคำว่า Tele (ไกล) + Metron (การวัด) ถ้าสรุปรวมจะเป็นการนำ Application Output มาวิเคราะห์ เพื่อให้ตอบคำถามของ Observability ได้นั้นเอง เอามาตอบ
- Logs - What is happening?
- มีอะไรเกิดขึ้นจาก อะไรบ้าง - Traces - Where is it happening?
- เกิดที่ไหน จุดไหน และมี Flow อย่างไร - Metrics - Size/Measure of Something ?
- ทำกี่รอบ มี user ในระบบกี่คน
ซึ่งเจ้าตัว Telemetry ตอนนี้ไม่ต้องมา Implement มี Standard กลาง OpenTelemetry โดยจะมองว่า Logs / Traces / Metrics และ Baggage เป็น Signal
- Baggage = contextual information that’s passed between spans.
- span = unit of work
สรุป ข้อมูลที่บอกตัวมันเองไม่ได้ใช้หรอก แต่ Service อื่นๆ ใช้เลยต้องแบกส่งไปเรื่อยๆ นึกถึง Code เรียก A(1) > B(1) > C(1) คนที่ต้องการจริงๆ C แต่ทว่ามันต้องฝากผ่านมากับ A และ B
Note: Baggage | OpenTelemetry
Telemetry-Logs
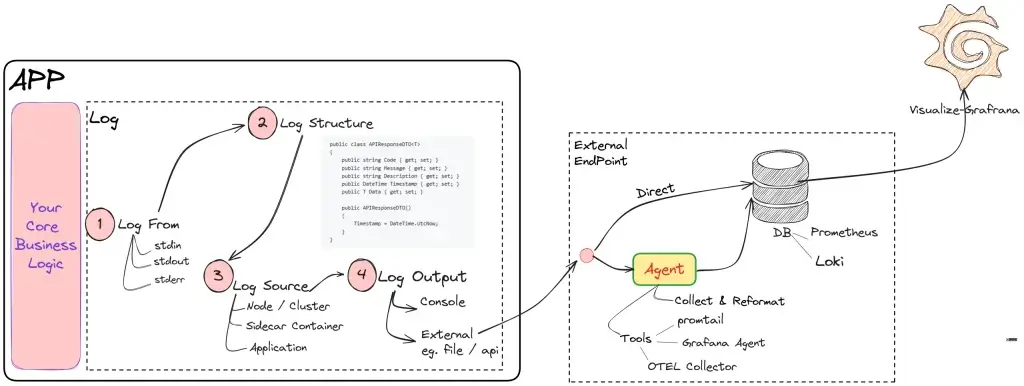
Logs = message บอกสถานะของระบบ ว่าอยู่ในกลุ่ม info / warning / debug / error เป็นต้น นึกถึง log4net เลย โดยควรบอกสถานะของชิ้นงาน Start / End
รูปแบบ
- เมื่อก่อนจะเป็น Text File ไม่มีโครงสร้างที่ชัดเจน
- ตอนนี้จะเป็น JSON (อะไรก็ได้มีโครงสร้างชัดเจน) และส่งผ่าน API ได้
Key Structure ของ Log ที่ควรมี
- Timestamp: เวลาที่เกิด
- Severability/ Severity: ประเภท พวก Log Level
- Log Line: บรรทัดที่เกิด
- Message: ข้อความ
ถัดมา JSON มี โครงสร้างชัดเจน จะมีพวก
- Metadata: คำอธิบายข้อมูล พวกไฟล์ จะเป็นขนาดไฟล์ ชนิดของไฟล์
- Data: เนื้อหาข้างในไฟล์
และสุดท้าย พอมีหลายตัว
- trace_id
- key เช่น service name
นอกจากการกำหนด Structure ที่ดีแล้ว เลือก Database ที่เหมาะสมกับ Log ด้วย จะได้เลือกใช้ถูก ว่าจะลง NoSQL / DB / Textfile / Neo4j / Redis (มันเหมาะฝากชั่วคราว หรือถาวร)
ใน OS จะมีนะ standard input / standard output / standard error ปกติแล้ว Log มาจาก standard output / standard error ออกผ่าน Console / TextFile (dev/stdout กับ dev/stderr)
Note: standard input ดักได้เขียน Code ให้มันเก็บเอา
ซึ่งตัว docker / podman / kube pattern คำสั่งดึงเหมือนกัน
docker logs <-containerid-> podman logs <-containerid-> podman pod logs <-podname-> kubectl logs <-podname->
ใน Cloud Native มี Log 3 แบบ
- Node-level logging - Infra / SysAdmin Log เข้ามาดู
- Logging via sidecar container - อ่าน Log จาก path ของ pod แล้วส่ง Centralize Logs
- Application-level logging - ของ Dev ตัว App
โดยขั้นตอนการส่ง Log
- Ship fluentd / filebeat.
- Store opensearch / Grafana Loki
- Note: Structure ของ Log ควรทำด้วย จะได้ parse ได้ง่าย หรือไปเชื่อมต่อกับระบบอื่นๆได้ เช่น Azure / GCP
Telemetry-Metric
Metrics - Size/Measure of Something ?
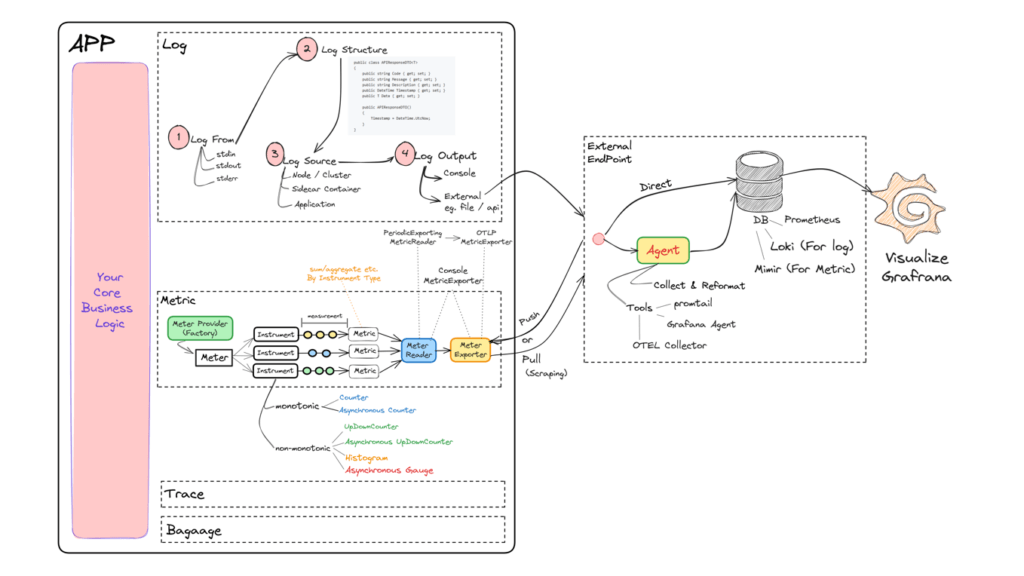
- Metric Pipeline อิงจาก OpenTelemetry
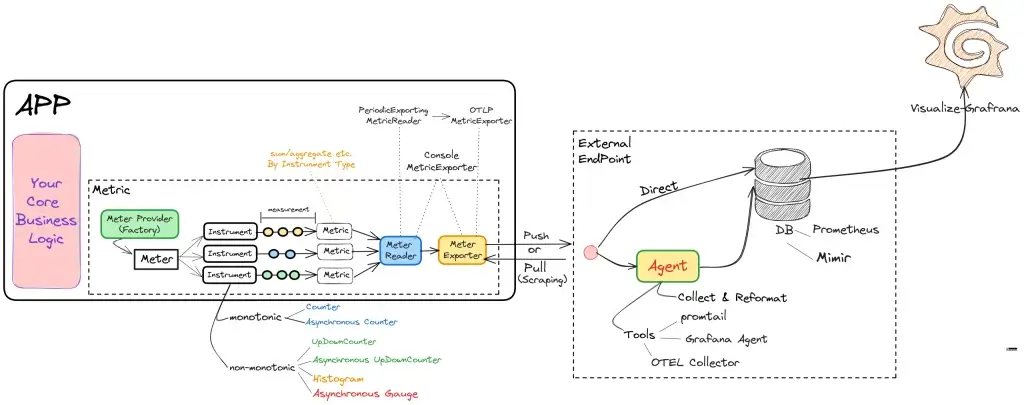
- MeterProvider ตัวสร้าง meter
- meter สร้าง instruments( วิธีการวัด) > measurements (ข้อมูลที่วัดตาม instruments)
- Metric Reader อ่าน measurements ที่ได้ในแต่ละจุด รวมกันได้เป็น Metrics
- Metric Exporter อ่าน Metrics ส่งไป External Endpoint
- External Endpoint ปลายทางที่เอา metrics ไปเก็บ โดย
- ยิงเข้า metric db ตรงๆ อย่าง Prometheus / Mimir (Scalable Prometheus)
- ยิงไป Agent อย่างตัว promtail / Grafana Agent หรือ ตัว OTEL Collector เพื่อแปลง หรือพักก่อนส่งไปยัง DB
ปกติแล้วพวก Metric Pipe Line เราไม่ต้องมาสร้างเองนะ มีพวก SDK เตรียมไว้ให้แล้ว
แล้วจะเลือก Instrument อย่างไร ?
- เลือก type of measurement >> จะได้เลือกตัว instruments ได้ตรงกับการวัด
- ข้อมูลที่เก็บเป็น monotonic หรือไม่ ?
monotonic=ค่าที่สะสมขึ้นไปเรื่อยๆ และเป็นจำนวนเต็ม เช่น กลุ่ม Counter ตัวอย่างพวก Request ในแต่ละชั่วโมง
- รูปแบบการส่งข้อมูล Sync / Async (ตาม Event)
- การดึง Push / Pull
- Pull ให้ Metric DB เข้ามา Scrapped ดึงไป ทาง Path ที่ตกลง
- Push ให้ App ส่งไปให้ Metric DB แต่ต้องระวังตัวถ้าต้อง Keep Connection จะให้ใช้ Resource ด้วย
Console ดูที่จอเรา Peroidic ใช้จริง
- Instrument Type
- Counter
- Asynchronous Counter เช่น
- Total Network Bytes Transfer > เอามาใช้ใน Cloud พวก Data Transfer มันคิดเงิน - UpDownCounter
- Asynchronous UpDownCounter - รวมข้อมูลที่กระจายหลาย node / microservice เช่น
- Net revenue for an organization across business units ดูไม่ค่อยเกี่ยวกับ IT เลย แต่เป็นการ Sum Data ช่วยทด ถ้าไปไล่ Sum จากใน DB จะใช้เวลานาน ทำให้นี้แสดงว่า Non-IT ใช้งานได้นะ แสดงว่า Tools อย่าง Grafana ไม่ได้ใช้ในมุมของ IT อย่างเดียวนะ - Histogram - เทียบความถี่ การกระจายของข้อมูล / Group & Count / ดู Oulier (อะไรที่โดดไปจากเดิม) ตัวอย่าง
- Response times for requests to a service วัด Latency ถ้าอันไหนมันโดดขึ้นมาต้องไปดูข้อมูลอื่นๆ เช่น Log / Resource ประกอบแล้ว อาจจะเป็นสัญญาณก่อน Service ตุยได้ - Asynchronous Gauge - ค่าที่มีการเปลี่ยนบ่อยๆ เหมือนพวกมาตรวัด ใน DevExpress ที่เคยทำมี Chart แบบนี้นะ เช่น นับ task ที่ค้างในระบบ
OTLPMetricExporter (push-based) - เอาไว้ส่ง Metric เข้าไปส่วนกลาง (centralized metric)
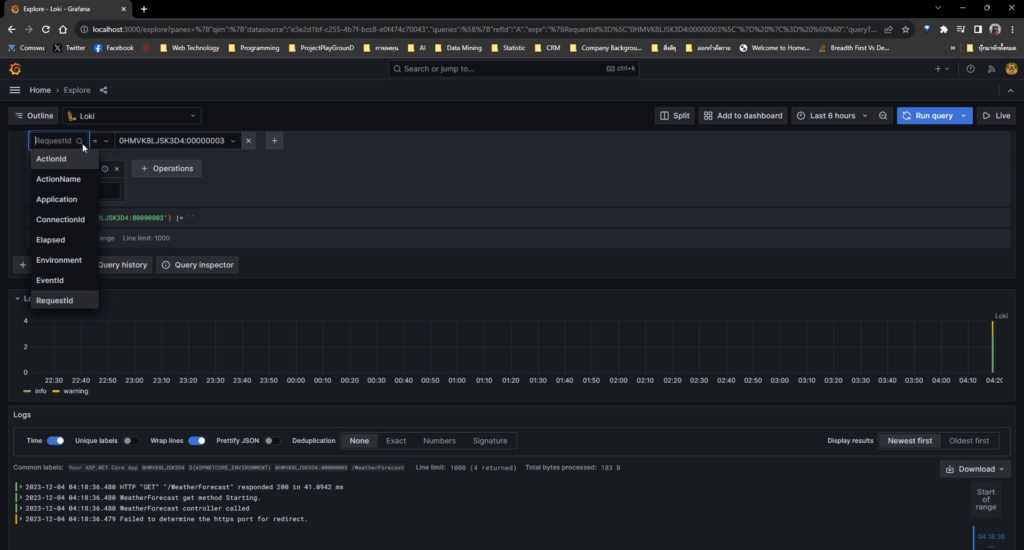
วันเสาร์มี่มาลอง LAB ครับ Run ได้สักทีหลังจากที่วันอังคาร / พฤหัสมีให้ลองไป แต่ Run ไม่ขึ้น ติด Dependency ของเครื่องตัวเอง ได้เห็นภาพขึ้นเยอะ ตอนแรกคิดว่า Observability มันไม่ได้เอามาดูในฝั่ง IT อย่างเดียวนะ ทาง Business ได้เอาไปใช้ด้วยนะ ตามในตัวอย่างของ Asynchronous UpDownCounter
หลังเขียน Blog จบ น้ำหนักขึ้น 2 KG !!! สงสัย Code ที่ Merge เข้าตัว 555
สำหรับของ dotnet หลังเรียนผมมีทำไว้นะ pingkunga/dotnet23observability (github.com) เดี๋ยวถ้าจัดอะไรครบจะ push ขึ้นไป
Reference
- Instrumentation | OpenTelemetry
- Metrics | OpenTelemetry
- opentelemetry-python/exporter/opentelemetry-exporter-otlp-proto-grpc/src/opentelemetry/exporter/otlp/proto/grpc at main · open-telemetry/opentelemetry-python (github.com) - ติดนานสรุป
//https://pypi.org/project/opentelemetry-exporter-otlp/ pip install opentelemetry-exporter-otlp
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.