สัปดาห์นี้มีเรื่องวุ่นเกี่ยวกับ Wix ToolSet กลับมาที่เรื่อง K8S ของ Week นี้ครับ จะเน้นไปในส่วนของ Power of Pod ต่ออะไรที่ทำกับ Pod ได้ หัวข้อประมาณนี้ครับ
Table of Contents
สำหรับใครที่เข้ามาจาก Google ลองดู Blog ก่อนหน้าได้ครับ
- The Cloud Camp Week#06 (K8S Part1:Overview) | naiwaen@DebuggingSoft
- The Cloud Camp Week#07 (K8S Part2:K8S Object) | naiwaen@DebuggingSoft
- The Cloud Camp Week#08 (K8S Part3: Store Data) | naiwaen@DebuggingSoft
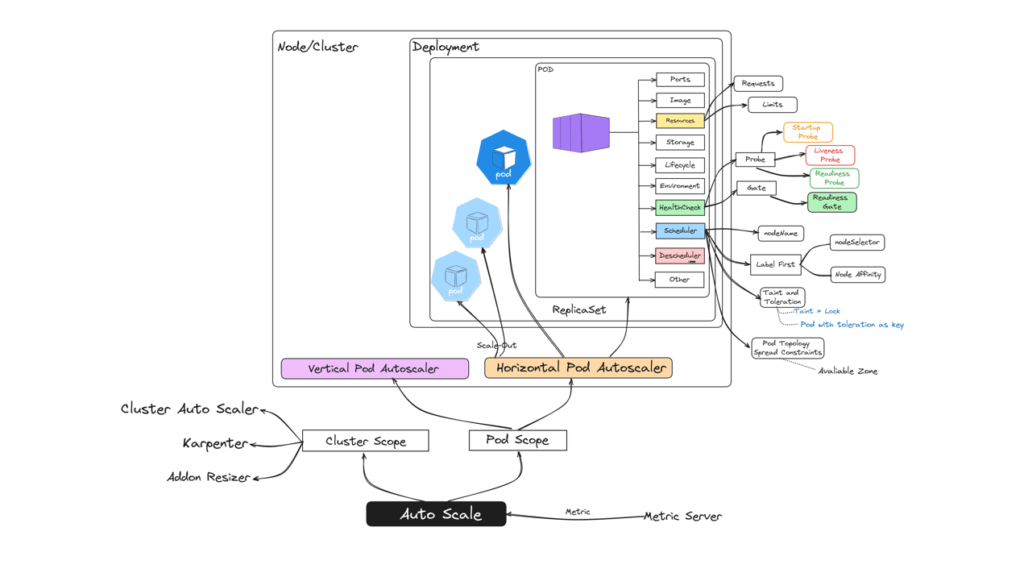
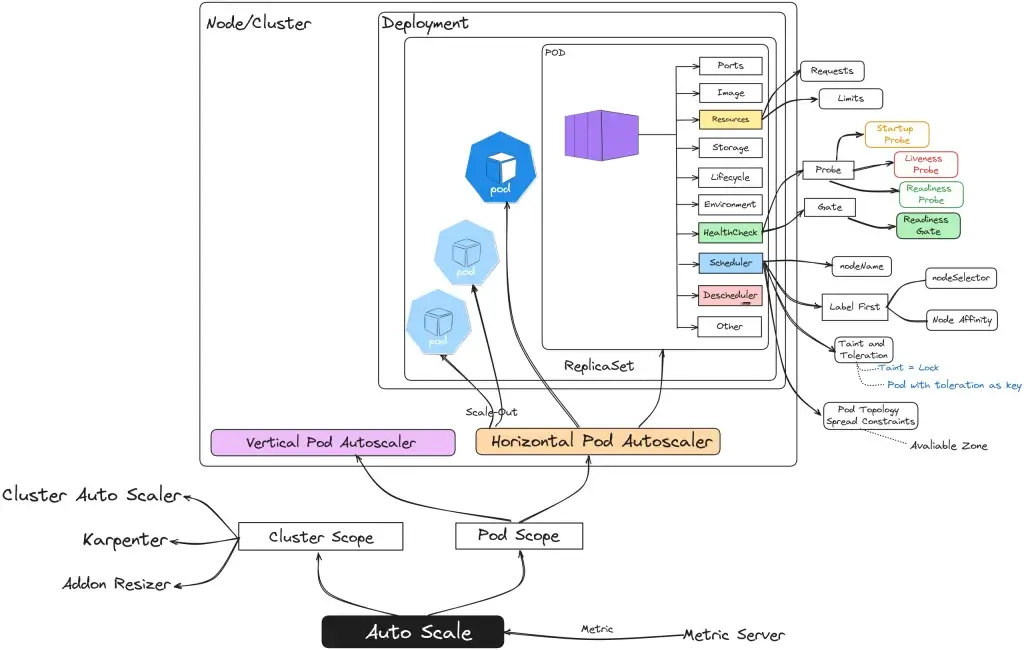
Resource Management
ในตัว Pod เราสามารถกำหนดการใช้งาน Resource พวก CPU / Memory / Local Ephemeral / GPU ได้จาก 2 ส่วน ได้แก่ requests / limits
- requests - resource ขั้นต่ำที่ container นั้นๆต้องการ ปกติแล้ว จะดูตอน Pod Initialize และ Start จนเสร็จสิ้น
NOTE: ถ้ากำหนดมากไป มันจอง Resource ไว้ ทำให้ Node ช้าๆลง - limits - resource สูงสุดที่ยอมให้ container นั้นๆ ใช้งานได้ ปกติแล้ว ต้องทำ Performance Test / Load Test กันก่อน แต่ถ้ารีบจริงๆ อาจจะเอาจำนวน Request และใช้ Magic Number เช่น 1.5 / 2 มาคูณทดเข้าไป
การกำหนดข้อมูล requests / limits จะให้ตัว kube-scheduler เอาไปเป็นเงื่อนไขในการเลือก Node ด้วย
โดย resource ที่กำหนดได้มีหลายตัว แต่ที่เรียนกันมี CPU / Memory //ตาม SI Model
- CPU - กำหนดเป็น absolute number มี 2 แบบ
- ตัวเลข - 1 (1 vCpu) / 0.5 (0.5 vCpu)
- millicores แบบนี้นิยมทำ เพราะ K8S จะมีข้อจำกัดใส่ 0.005
> ถ้าใช้ 1 vCpu จะเป็น 1000m
> ถ้าใช้ 1/4 vCpu จะเป็น 250m
> ถ้าใช้ 1/10 vCpu จะเป็น 100m - Memory - กำหนด absolute number จะเป็น
- Bytes เช่น 128974848
- Exponent เช่น 129e6
- หน่วย E, P, T, G, M, K.
- หน่วย Ei, Pi, Ti, Gi, Mi, Ki ได้เต็มเม็ดเต็มหน่วยตามฐาน 2
เช่น 512Mi = 512*1024 เป็นต้น
ปล. ตัวเต็ม Exabyte / Petabyte / Terabyte / Gigabyte / Megabyte / Kilobyte
- Sample YAML
apiVersion: v1
kind: Pod
metadata:
name: eureka-managing-resource
spec:
containers:
- name: eureka-managing-resource
image: netflixoss/eureka:1.3.1
resources:
requests:
memory: "250Mi"
cpu: "250m"
limits:
memory: "300Mi"
cpu: "500m"
หลังจากกำหนด requests / limits แล้ว จะเป็นหน้าที่ของตัว kubelet ที่จะติดต่อ Container Runtime เพื่อคุม Resource ตาม requests / limits ที่กำหนดไว้
- Best Practice
- ควรกำหนด requests / limits ให้กับแต่ละ pod จะได้สะท้อนภาพรวมของระบบได้ ปกติควรจะอยู่ประมาณ 70-80% ของ Node
Note: อย่าลืมนอกจาก Node แล้ว มันยังมีพวก OS / Kernel ด้วยนะ ที่ใช้งาน Resource ด้วย - การกำหนด Limit ให้ดู Nature ของ App ด้วย ว่าเป็นแบบใช้ CPU เยอะ / ใช้ Memory เยอะ เวลาใช้งานบน Cloud จะได้เลือก Instance ที่ออกแบบมาตรงกับ APP เช่น ใช้ CPU เยอะ Compute Optimize
- ปกติแล้ว จะ limits ที่ตัว memory ถ้าเลือกได้อย่างใดอย่างนึง เพราะ ตัว App ส่วนใหญ่มีโอกาสจะ memory leak ได้สูง แล้วถ้าเกิน Limit HW นานระดับนึงจะโดน Kill Pod ทิ้ง Pod Status จะเป็น OOMKilled (Out of Memory Killed)
Note ถ้ามีเยอะๆ ตัว Node ตายได้นะ - ถ้า Pod Restart บ่อย ต้องเข้ามา Investigate หาสาเหตุ อาจจะเกิด Memoryleak แล้วทำให้ App ตาย ซึ่งถ้าเกิดบ่อยๆ ส่งผลกับรายได้ (Tech > Biz)
- เราจะรู้ได้ไงว่าควรตั้ง resources.requests เท่าไหร่ถึงพอ ?
อันนี้เขียนเพิ่มจากวันเสาร์ที่ได้ไปทำ Lab นะ
- Step แรก ถ้ามีกำหนดไว้ให้ลอง Comment ออกก่อน แล้วลอง Deploy จากนั้นใช้ Tools อย่าง K9S มาดู memory / cpu หรือ ใช้ kubectl top pod / node
PS D:\2023TCC\Week9\Lab\2> kubectl top pod -n group-1 NAME CPU(cores) MEMORY(bytes) eurakaping-7fc5b9d7cd-llhf6 1000m 500Mi pinga-5f58b8967c-b7xw9 0m 7Mi pingb-6d55d7f555-t2jpx 8m 7Mi pingc-6b6854df5-4sl84 0m 7Mi
- พอได้ Resource ที่มันใช้สำหรับ Start Container แล้ว ค่อยไปกำหนด resources.requests และเพิ่ม limit จาก load test หรือจะคูณ magic number (1.5 / 2.0 / 2.5)
Resource:
- Resource Management for Pods and Containers | Kubernetes
- Kubernetes size definitions: What's the difference of "Gi" and "G"? - Stack Overflow
- Kubectl Top Pod/Node | How to get & read resource utilization metrics of K8s? | SigNoz
Auto Scale
- Recap Scale
เงื่อนไขว่าจะอะไรมา Scale ตาม Load หรือ Reqest ที่เข้ามาหนักหน่วง (Intensive)
- จับจาก Resource เช่น CPU / Memory / GPU / Connection (Pool / Response ที่ตอบช้าลง)
- ช่วงเวลา Custom เช่น Business ช่วงต้องปิดงบไตรมาส
ภาพ App Service Plan ลอยมาเลย สำหรับรูปแบบการ scale มี 2 แบบ
- Vertical Scaling (Scale UP/ Down) เป็นการขยาย/ลดขนาดของ Instance ให้มี Resource มากขึ้น เช่น CPU / RAM
- Prod จัดการได้ง่าย เพราะตัว App เดิมๆ ที่อาจจะเป็น Stateful (เช่น พวก DB) ไม่ต้องมาปรับตัวอะไรมาก
- Con single point of failure และมื่อถึงจุดที่ต้องการ Spec สูงๆ จะเริ่มแพงขึ้น เพราะหาเครื่องในท้องตลาดยาก - Horizontal Scaling (Scale Out / In) เป็นการเพิ่ม / ลดจำนวน Instance
- Prod เพิ่ม Availability + fault-tolerance
- Con Complexity เพิ่มต้องมาจัดการ Instance / Communication และเรียนรู้ Tools เข้ามาช่วย อย่าง K8S
รวมถึงต้องคิดตั้งแต่ Design App ควรต้องเป็น Stateless ไม่ถืออะไร เดวจากลาไม่ต้องมาตามล่า รวมถึง Cost ที่เพิ่มขึ้น
- Pod Autoscale
สำหรับใน K8S จะมี 2 แบบ
- Horizontal Pod Autoscaler (HPA) - เดี๋ยวมีอธิบายต่อไป
- Vertical Pod Autoscaler (VPA) - อันนี้จะไป Workload เข้ามาปรับ requests / limits เหมาะกับงานพวก Stateful เช่น DB ที่ต้องการเพิ่ม CPU / RAM ทำ Scale Up/Down
->> Horizontal Pod Autoscaler (HPA)
HPA ใช้ Autoscale สำหรับ Deployment / StatefulSet โดยดูจาก metric CPU Utilization / Memory ซึ่งข้อมูล metrics พวกนี้ มาจาก 2 แหล่ง
- K8S Metric-Servier
- Custom metrics support เช่น Prometheus Adapter
เมื่อ metrics ถึง Threshold ที่กำหนดสิ่งที่ HPA ทำ มันจะทำการเพิ่ม Pod ขึ้นมา ถ้า Metric ลดลงแล้วตัว HPA จะรอสักพัก แล้วลดจำนวน POD ลงให้เหมาะสม
DeamonSet ใชัตัว Horizontal Pod Autoscaler ไม่ได้นะ
ใน K8S จะมี Object อีกตัว HorizontalPodAutoscaler เข้ามาช่วยจัดการเรื่องนี้ ตัว Yaml Pattern ประมาณนี้
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: null
name: php-apache
spec:
maxReplicas: 10 #จำนวน Pod สูงสุดที่ยอมให้ Scale
minReplicas: 1 #จำนวน Pod ต่ำสุดที่ต้องมี
#หา Deployment โดยจับจาก apiVersion / kind และ metadata.name
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
targetCPUUtilizationPercentage: 50 #จับจากภาพรวม เลยแนะนำให้ใช้อันนี้
status:
currentReplicas: 0
desiredReplicas: 0S
apiVersion: apps/v1
kind: Deployment
metadata:
name: php-apache
labels:
run: php-apache
spec:
selector:
matchLabels:
run: php-apache
template:
metadata:
labels:
run: php-apache
spec:
containers:
- name: php-apache
image: registry.k8s.io/hpa-example
ports:
- containerPort: 80
resources:
limits:
cpu: 500m
requests:
cpu: 200m
---
apiVersion: v1
kind: Service
metadata:
name: php-apache
labels:
run: php-apache
spec:
ports:
- port: 80
selector:
run: php-apache
ซึ่งตัว HorizontalPodAutoscaler จะเข้าไปคุมตัว ReplicaSet อีกที โดยการ Scale Out / In ใน K8S มีสูตรพื้นฐานมาให้
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )]
desiredReplicas = ceil[currentReplicas * ( currentMetricValue / desiredMetricValue )] โดยที่ currentMetricValue = load ปัจจุบัน desiredMetricValue = ค่าที่ต้องการให้ตัว HorizontalPodAutoscaler รักษาไว้ currentReplicas = จำนวน pod ตอนนี้ ตัวอย่าง เช่น currentMetricValue = 249 desiredMetricValue = 50 currentReplicas = 1 ดังนั้นจำนวน Pod ที่ HPA ต้อง Scale 1*(305/50) = 4.98 >> Celi(4.98) >> 5 ดู Config maxReplicas = 10 สรุปได้ HPA ต้อง Scale Pod จาก 1 > 5 (Scale Out) ========================================== กลับกันถ้า currentReplicas = 0 desiredMetricValue = 50 currentReplicas = 5 ดังนั้นจำนวน Pod ที่ HPA ต้อง Scale 5*(0/50) = 0 >> Celi(0) >> 0 แต่ต้องไปดู Config minReplicas สรุปได้ HPA ต้อง Scale Pod จาก 5 > 1 (Scale In)
แต่ถ้ามีสูตรที่ดีกว่าก็ Custom ได้ และเพื่อป้องกัน Scale มันเหวี่ยง ตัว K8S จะมี tolerance เอาหน่วงรอสักพัก (Default 0.1)
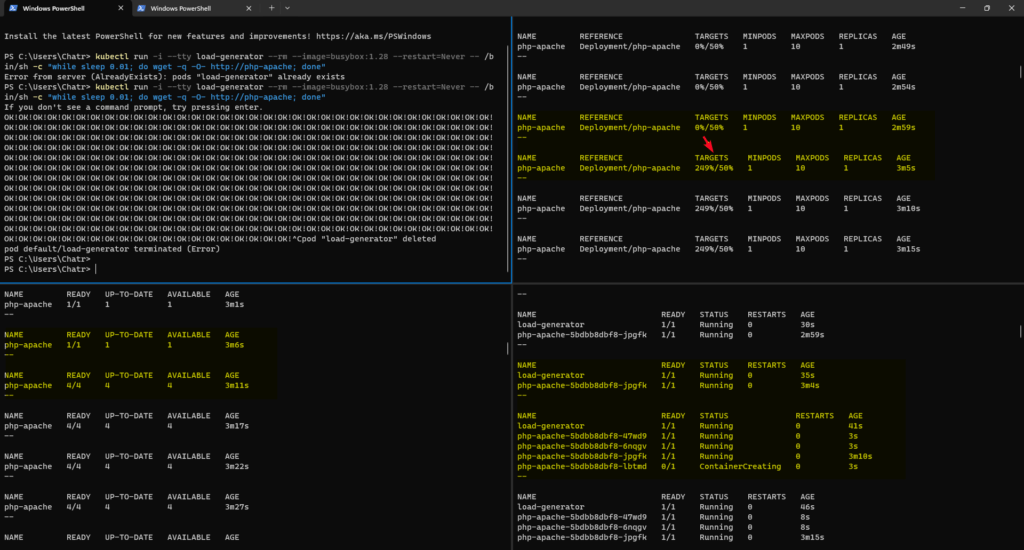
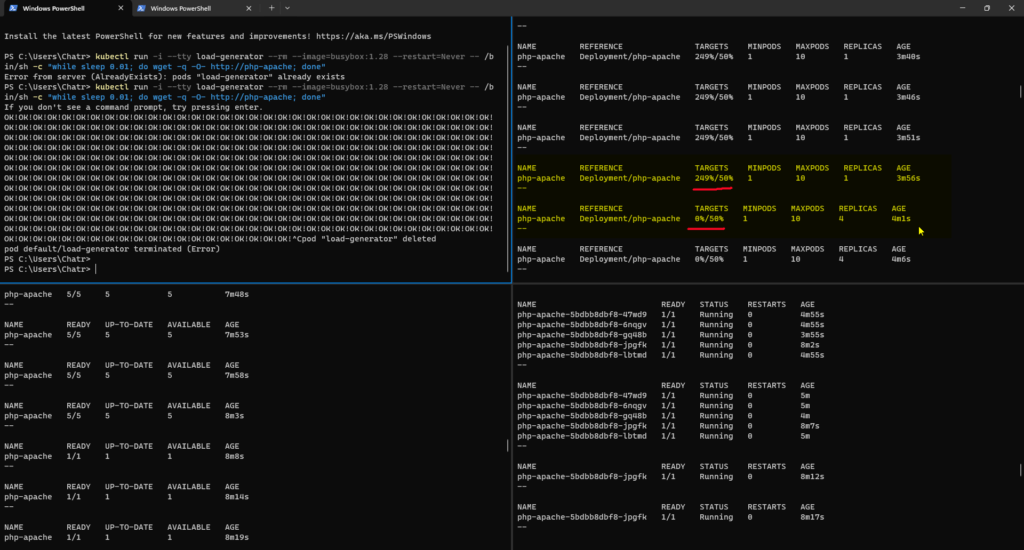
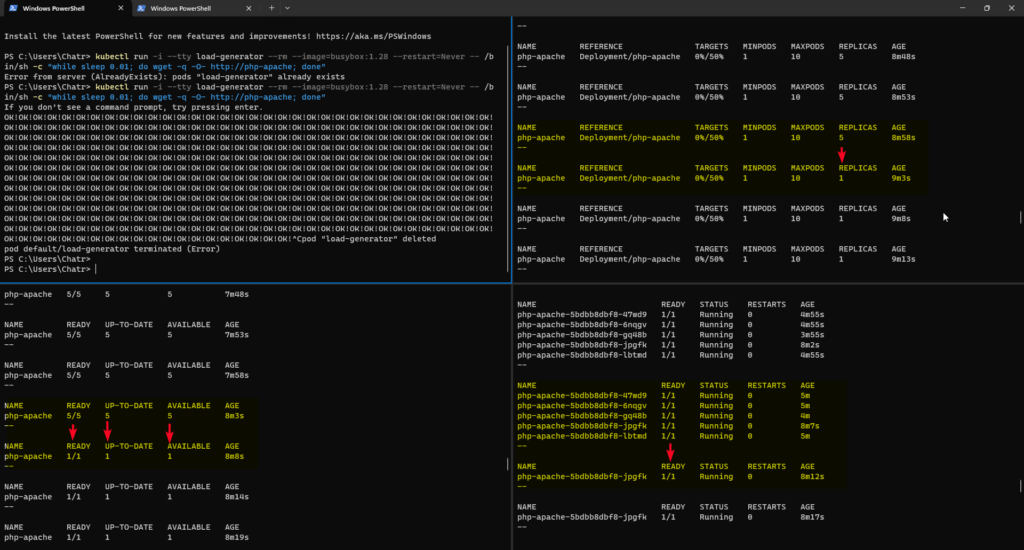
->> Command
#Create HPA kubectl autoscale deployment <<YOUR_DEPLOYMENT_NAME>> --cpu-percent=50 --min=1 --max=3 -n group-1 --dry-run=client -oyaml > pinga-hpa.yaml #General Command kubectl get hpa
ตัวอย่าง การใช้
# Linux
watch kubectl get hpa;
#Power Shell
while (1) {kubectl get hpa; write-host "--`n"; sleep 5}
#Power Shell Full Command.
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
while (1) {kubectl get hpa; write-host "--`n"; sleep 5}
while (1) {kubectl get pod; write-host "--`n"; sleep 5}
while (1) {kubectl get deployment php-apache; write-host "--`n"; sleep 5}
->> เปิด metric-server
- K8S จาก docker-desktop - deploy จาก metric-server for K8S via docker-desktop 4.24.2 (github.com)
- minikube เปิดจาก
minikube addons enable metrics-server
- ตรวจสอบ pod metrics-server มีสถานะ running ไหมจากคำสั่ง
kubectl get pod,svc,ep -n kube-system
->> Best Practice
- ตัว HPA ถ้าทำให้ Smooth อาจจะต้องมาปรับ Tune Property ที่มันมีมาให้ก่อน เพื่อให้ได้ behavior ที่ต้องการ
- ใน Deployment ค่า replicas ให้เอาออก แล้วให้ตัว HPA มันคุมเอง
- ที่ HPA targetCPUUtilizationPercentage ปกติจำกำหนดที่ 70% เหลือ 30% ให้ Node แต่ถ้า App ที่ขึ้นมัน Critical มากกว่านั้นค่าจาก 70% ลง
- App monolithic (lift & ship) จะใช้ VPA + Deployment เสริม Availability
- ถ้าต้องการ Scale เป็นช่วงเวลาที่แน่นอนใช้ tkestack/cron-hpa: Cron Horizontal Pod Autoscaler(CronHPA) (github.com)
Resource: Horizontal Pod Autoscaling | Kubernetes
- Cluster Auto Scaler
เอามาแก้ปัญหากรณีที่ Scale Pod จนเต็มแล้ว ถ้ามี Request ที่ต้องการ Scale เพิ่ม ตอนนี้จะเหลือเพิ่ม เครื่อง หรือ เพิ่ม Resource ให้เครื่องแล้ว สำหรับ Tools ทำ Horizontal Scale มีตัว
- Cluster Autoscaler - ของ K8S เอง
- Karpenter - Third Party Tools อีกตัว
Cluster คือ กลุ่มของ K8S Machine (Node) ไม่ว่าจะเป็น VM / Bare Metal Server เป็นต้น ที่เอา Resource ใช้สร้าง Pod ต่างๆ โดยมีสิ่งที่ Cluster Auto Scaler จัดการ ดังนี้
- ดู metric ภาพรวมของ Node ว่าถึงจุดอันตราย หรือย้ง เพื่อตัดสินใจ Scale (เพิ่ม/ลด Node) โดยที่จุดอันตราย ดูจาก Load
- แบบ HPA จับจาก currentMetric > มากกว่า ratio ที่กำหนด
- event ว่ามี pod pending เยอะๆ - เมื่อถึงจุดที่ต้อง Scale Out [ต้องเพิ่ม Machine/Node]
- กรณี Cloud จะให้ตัว Cloud Controller ส่ง Request ไปขอเพิ่ม Instance
- กรณี On-Premises เช่น vSphere เพิ่ม Instance / VM ขึ้นมา
Note: ในกรณีที่ Request ลดลง จะ Scale in [ลด Machine /Node ลง] - แล้วอะไรที่ต้องระวังตอน scale ?
- การออกแบบ IP / Subnet ต้องเผื่อให้เพียงพอกับการ Scale Node ด้วย - Cloud Cost Optimization Guide - การเพิ่ม Node นั้นเสียเงิน เราสามารถแบ่งกลุ่ม Node ได้
- Subnet Scale แบบ On-Demand สร้าง Dedicate Node ใหม่
- Subnet Scale จาก Spot Instance ใช้สำหรับ Load ที่มาในรูปแบบ Spike สั้นๆ เวลาน้อย เพราะ Note: Spot Instance เป็น Node ที่ราคาถูกมาก เอา Resource เหลือจาก Cloud มาใช้งาน แต่มีโอกาศยึดคืนได้จากตัว Cloud Provider ได้เหมือนกัน
- Addon Resizer
Addon Resizer - เป็น Tools ที่เอามาทำ vertically scales เพิ่ม Resource ให้ Container ตามจำนวน Node ถ้า Node เพิ่ม Container จะได้ Resource เพิ่ม
The Addon scale up/down the container resource configuration of specific singleton Kubernetes addons based on the size of the Kubernetes cluster
ปิดท้ายเรื่อง Scale ทั้ง HPA / VPA / Cluster Auto Scaler / Addon Resizer เป็นการแก้ปัญหาฝั่ง Infra Structure ถ้าต้องการคุม Cost + Performance ต้องมา Optimized Application ด้วย
Resource: kubernetes/autoscaler: Autoscaling components for Kubernetes (github.com)
Health Check
- YAML Pattern
....
spec:
containers:
- name: testcontainer
image: nginx
<<ProbeType>>: # readinessProbe/livenessProbe/startupProbe
<<ProbeProtocal>>: # httpGet / tcpSocket / exec
<<Config for Each Probe Protocal>>: #
<<Common Probe Config>> # initialDelaySeconds / periodSeconds ...
- Probe Type
Readiness Probe - ตรวจว่า Pod พร้อมไหม ที่จะรับ Traffic ในกรณีที่รับ Load เยอะไป สามารถให้ Pod Return false ตอน Check ได้
Update เพราะหลังจากลลองโจทย์ มันได้ 0/1 รอตาม Readiness Probe ได้ 1/1 และค้างยาวเลย 555
สรุปตัว App ต้องแก้ด้วย เช่น ถ้าเรามี WebAPI รับ Load ได้ 40 Job ถ้ามีตัว 40 เข้ามา return false กลับไป บอก K8S กระจายไปตัวอื่นๆ
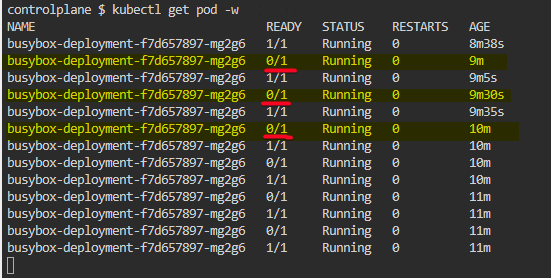
Liveness Probe - เมื่อไหร่ Pod ของ Restart หรือ Start สิ่งใหม่ //น่าจะเกี่ยวกับพวก ReplicaSet
- เคสแรก ตรวจสถานะ Pod ถ้า False ติดกัน 3 รอบ ให้ K8S Restart Pod ที่ทำหลายรอบ เพราะว่า อาจจะเรื่อง Network หลุด เลยตรวจหลายๆรอบให้แน่ใจก่อน
- เคสสอง จะสัมพันธ์กับ Readiness Probe จากตัวอย่าง WebAPI Job 41 มาจะเข้าไม่ได้และ แต่ใน Pod นั้น 40 Job เดิมยังคงทำงานจนจบ แล้ว ถึง Restart ได้ เพื่อ Start สิ่งใหม่ อาจจะขึ้น Ver ใหม่
Startup Probe - สำหรับ Application ที่มีตัว Warm Start >> App เวลาที่เริ่มจนมันพร้อมใช้งาน Ready นานพอสมควร เช่น ต้องรอมากกว่า 30 วินาทีขึ้นไป
Note ไม่ควรใช้ Liveness ที่เพิ่ม Interval ในการรอ (long liveness interval) เพื่อตรวจสอบ กรณีที่ App Start ช้า สูตรเผื่อเวลา
สูตร initialDelaySeconds + (failureThreshold × periodSeconds)
- กำหนด End Point เดียวกัน Liveness
ปล. NET ระวังเคส Cold Start
#startupProbe # สูตร initialDelaySeconds + (failureThreshold × periodSeconds) # จะได้ 0 + (30 x 10) = 300 Sec ประมาณ 5 นาที startupProbe: httpGet: path: /healthcheck port: 80 failureThreshold: 30 periodSeconds: 10 livenessProbe: httpGet: path: /healthcheck port: 80 failureThreshold: 1 periodSeconds: 1
- Probe Order
ลำดับ Probe
Start ->-------------------------------------------------->--- Ready
Startup Probe => Readiness Probe
=> Liveness Probe
Readiness / Liveness พอๆกัน
- ตรวจ Startup Probe ก่อนแต่ต้อง Tune Config Readiness Probe / Liveness Probe ไม่งั้นจะมีเคส App Restart แบบแปลกๆ หรือ Traffic ไม่เข้า
Keyword อื่นๆ
- Readiness Gate รอให้ deployment ที่เกี่ยวข้องกัน พร้อมใช้งานก่อน พวก microservice
Ref: Pod readiness
เวลาขยับ Ver ของ K8S ตรวจพวกนี้ด้วย
- Define Probe
มี 3 แบบ
- httpGet - curl ตาม path + port
- tcpSocket - check port
ทำมา Support พวก Queue / Socket ที่ httpGet ทำไม่ได้
หรือ App ไม่มี HealthCheck Path - exec - Run Command แล้วตรวจ Exit Code หรือ จาก Cat ต้องดูคำ ต้องไปดู Spec เพิ่ม
- Configure Probes
- initialDelaySeconds - รอกี่วินาที ถึงเริ่ม Check (Default = 0 / Min = 0)
- periodSeconds - รอบถัดไปในการ Check อีกรอบ ถ้าน้อยจะเป็น ddos (Default = 10 / Min = 1)
- timeoutSeconds - Trigger Check ไปแล้วให้รอผลลัพธ์เป็นเวลาเท่าไหร่ (Default = 1 / Min = 1)
ถ้าหลุด มันจะเกิด
- Readiness Fail งดรับ Traffic
- liveness จะ Count - successThreshold - Check สำเร็จติดกัน กี่รอบถึงบอกว่าสำเร็จได้ (Default = 1 / Min = 1)
- Readiness กำหนดเป็น 1
- Liveness กำหนดเป็น 1
- startup
** ระวังกำหนดตรงนี้ ถ้าพลาดจะเป็น CrashLoopBackOff - failureThreshold - Check Fail ติดกัน กี่รอบ ถึงบอก Fail (Default = 3 / Min = 1) ควรใช้ใน
- Liveness - กี่รอบ Restart Container
- Readiness - กี่รอบบอก Pod UnReady
- Sample YAML
apiVersion: apps/v1
kind: Deployment
metadata:
name: inv-api-deployment
spec:
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
type: RollingUpdate
template:
metadata:
labels:
app: inv-api
spec:
containers:
- name: inv-api
image: pingkung/inv-api:8.8.8
# กรณีดูจาก Command
# startupProbe:
# exec:
# command:
# - cat
# - /tmp/healthy
startupProbe:
httpGet:
path: /healthcheck
port: 80
failureThreshold: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 10456
successThreshold: 2
livenessProbe:
httpGet:
path: /healthcheck
port: 10456
initialDelaySeconds: 0
periodSeconds: 10
timeoutSeconds: 1
failureThreshold: 3
Scheduler
- nodeName
nodeName (ใส่ชื่อ node ลงไปตรงๆ) ตัวอย่าง เช่น ต้องการให้ลง node ชื่อ "kube-01"
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
nodeName: kube-01
- nodeSelector
nodeSelector กำหนดเงื่อนไขเลือก node อาจจะดู label ของ node เช่น
- disktype > hdd / ssd
- workload > general / compute
ถ้าใส่ไปหลายๆ label มันจะเอาตัวที่เจอก่อนเป็นตัวแรก
ตัวอย่าง เช่น
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
nodeSelector:
workloadtype: general
- Taint and Toleration
Taint - Lock Node ทำ Policy ในการ Deploy Pod
- Pattern
key=value:Effect
- Effect
- NoSchedule - ไม่ให้ขึ้น Pod ใหม่ //Pod ของเดิมยังอยู่ได้
- PreferNoSchedule - ถ้าไม่มีที่อื่นแล้วมาที่นี้ก็ได้
- NoExecute - ขอคืนพื้นที่ ถ้า Pod ที่ Run มี PriorityClass ที่ต่ำกว่า System อยู่จะโดน Kill ทันที - Sample Command
#Check Node Taints #-PowerShell kubectl describe node node01 | select-string Taints* #-Linux kubectl describe node node01 | grep Taints* #=================================== #Add Taint with No Schedule Effect kubectl taint nodes node01 disktype=ssd:NoSchedule #ตอน describe node ที่ในส่วนของ Taints จะมีตัวที่เราเพิ่งเพิ่มเข้าไป #ถ้า deploy yaml แล้วตอนนี้ ยังไม่ได้กำหนด Toleration จะไม่ได้ เพราะกำหนด Effect NoSchedule #Remove taint add - after key=value:Effect kubectl taint nodes node01 disktype=ssd:NoSchedule-
Toleration บัตรผ่านการใช้ Taint
apiVersion: v1
kind: Pod
metadata:
name: nginx-noschedule
spec:
containers:
- name: nginx-noschedule
image: nginx
#ใส่บัตรผ่าน เพื่อใช้ node01 disktype=ssd:NoSchedule
tolerations:
- key: "disktype"
operator: "Equal"
value: "ssd"
effect: "NoSchedule"
apiVersion: v1
kind: Pod
metadata:
name: nginx-noschedule
spec:
containers:
- name: nginx-noschedule
image: nginx
#ใส่บัตรผ่าน เพื่อใช้ node01 disktype=ssd:NoExecute
tolerations:
- key: "disktype"
operator: "Equal"
value: "ssd"
effect: "NoExecute"
ต้องกำหนดบัตรผ่าน (กุญแจให้ครบชุด ถึงใช้งานได้)
อ๋อ ถ้า node กำหนด taints ไว้หลายชุด ต้องใส่ให้ครบด้วยนะ
- Query ดู Taints ใน node
kubectl get nodes -o custom-columns=NAME:.metadata.name,TAINTS:.spec.taints
- Node Affinity
เอาไว้กำหนดเงื่อนไขที่ซ้ำซ้อนขึ้น เพราะตัว Node Affinity มี Expression ให้ใช้งาน
- Set Label
#List Label kubectl get nodes --show-labels #Add a label for each node format [key]=[value] kubectl label nodes node01 workloadtype=general kubectl label nodes node02 workloadtype=compute kubectl label nodes node03 workloadtype=memory
- Create Expression
- matchExpressions:
- key: workloadtype
#operator ที่เป็นไปได้ In / NotIn / Exists / DoesNotExist / Lt / Gt
operator: In
values:
- general
- compute
Deployment Type
- requiredDuringSchedulingIgnoredDuringExecution - ตรง Spec เท่านั้นถึง Deploy ได้
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: workloadtype
operator: In
values:
- compute
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
- preferredDuringSchedulingIgnoredDuringExecution - ถ้าไม่มีตรง Spec ยอมได้ ถ้ามีหลาย node มี weight (ค่า 0-100) เอามาให้ K8S คำนวณตัดสินใจเลือก Node
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
preference:
matchExpressions:
- key: workloadtype
operator: In
values:
- general
- weight: 20
preference:
matchExpressions:
- key: workloadtype
operator: In
values:
- compute
- memory
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
Note: IgnoredDuringExecution - เอาไว้ใช้เบรก มาแก้ Runtime เช่น การเปลี่ยน Label
- Pod Topology Spread Constraints
Pod Topology Spread Constraints = Policy ในการกระจาย Pod เพื่อเพิ่ม Availability กำหนดที่ Spec ของ Deployment จริงๆ ถ้าเทียบกับ Cloud มันพวก Availability Zone / Region
- Config Pattern
pod.spec:
# Configure a topology spread constraint
topologySpreadConstraints:
- maxSkew: <integer>
minDomains: <integer> # optional; beta since v1.25
topologyKey: <string>
whenUnsatisfiable: <string>
labelSelector: <object>
matchLabelKeys: <list> # optional; beta since v1.27
nodeAffinityPolicy: [Honor|Ignore] # optional; beta since v1.26
nodeTaintsPolicy: [Honor|Ignore] # optional; beta since v1.26
### other Pod fields go here
- ตัวอย่าง ตอนตรวจ List ว่า 5 pod กระจายไป 5 node อย่างละ 2 pod
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: pingd
name: pingd
namespace: group-1
spec:
#Max 2 Per Node 5 Node = 10
replicas: 10
selector:
matchLabels:
app: pingd
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: pingd
spec:
topologySpreadConstraints:
#eveny node 2 pods
- maxSkew: 2
#topologyKey is the key of node labels. Nodes that have a label with this key and identical values are considered to be in the same topology
#topologyKey: topology.kubernetes.io/region=proenhn
topologyKey: node-name
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: pingd
containers:
- image: nginx
name: nginx
resources: {}
#warmup 10 seconds
#initialDelaySeconds + failureThreshold × periodSeconds
startupProbe:
httpGet:
path: /
port: 80
scheme: HTTP
initialDelaySeconds: 10
#Restart every 1 minute
livenessProbe:
httpGet:
path: /
port: 10456
initialDelaySeconds: 1
periodSeconds: 60
failureThreshold: 1
#Traffic every 16 seconds
readinessProbe:
httpGet:
path: /
port: 80
successThreshold: 1
periodSeconds: 16
failureThreshold: 4
# affinity:
# nodeAffinity:
# requiredDuringSchedulingIgnoredDuringExecution:
# nodeSelectorTerms:
# - matchExpressions:
# - key: node-name
# operator: In
# values:
# - node-01
# - node-02
# - node-03
# - node-04
# - node-05
tolerations:
- key: "node"
operator: "Equal"
value: "no1"
effect: "NoSchedule"
- key: "node"
operator: "Equal"
value: "no2"
effect: "NoSchedule"
#เอา node3 ขึ้นไม่ได้ เพราะเจอ Taint 2 ตัวของ node นั้น
#[map[effect:NoSchedule key:disktype value:ssd] map[effect:NoSchedule key:node value:no3]]
- key: "node"
operator: "Equal"
value: "no3"
effect: "NoSchedule"
- key: "node"
operator: "Equal"
value: "no4"
effect: "NoSchedule"
- key: "node"
operator: "Equal"
value: "no5"
effect: "NoSchedule"
status: {}
- ตอน describe pod มันขึ้นตัว Topology Spread Constraints ด้วยนะ
Topology Spread Constraints: node-name:DoNotSchedule when max skew 2 is exceeded for selector app=pingd
Resource: Pod Topology Spread Constraints | Kubernetes
DeScheduler
จัดการ Pod เพื่อคุม Cost/Performance ตาม Policy โดยการ
- ลบ Pod ที่ไม่จำเป็น - Scheduler มันสร้างเกิน
- หรือ อยู่ผิดที่ผิดทางออกไป - Pod กระจาย Node มากไปทั้งๆที่มันสามารถย้ายมารวม Node เดียวกันได้ เป็นต้น
Resource: kubernetes-sigs/descheduler: Descheduler for Kubernetes (github.com)
นอกจากนี้ตัว K8S มีของ Tools ตัวให้เอามาใช้งานใน Kubernetes SIGs (github.com) เช่น External DNS
ภาพรวมของ Week นี้น่าจะได้ประมาณนี้
ส่วนวันเสาร์ที่มาทำ Lab ที่ KX ได้รู้หลายเรื่องเลย
- ตอนเช้า งงว่าเราจะรู้ได้ไงว่าต้องกำหนด resource.request เท่าไหร่ กับเทสยังไง เลยไปไล่นั่งอ่านจาก Eureka REST operations · Netflix/eureka Wiki (github.com) พอรู้วิธี ที่คุณโจ้เฉลยแล้ว อ๋อเลย
- ตอนบ่าย งงเรื่อง HealthCheck ไม่รู้ว่าทำถูกไหม ฮ่าๆ
Reference
- The Cloud Camp by Jumpbox
- Assign Memory Resources to Containers and Pods | Kubernetes
- The Guide to Kubernetes Affinity by Example (densify.com)
- Autoscaling in Kubernetes: Options, Features, and Use Cases | by Sasidhar Sekar | Expedia Group Technology | Medium
- Topology Spread Constraints for High Availability and Efficiency (cast.ai)
- How to List All Pods and Its Nodes in Kubernetes | Baeldung on Ops
- Kubectl Top Pod/Node | How to get & read resource utilization metrics of K8s? | SigNoz
- kubernetes - How does weight affect pod scheduling when affinity rules are set? - Stack Overflow
- Kubernetes Horizontal Pod Autoscaling — for local development | by Daniel Trimble | Medium
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.