หลังๆมาตอน Implement ระบบที่ Site ใหม่ๆ ต้องเจอคำถามว่า ควรมี Solution Backup อย่างไร / ถ้ามีปัญหาที่ DC เราจะเตรียมความพร้อมกันอย่างไร / ทำ Business Continuity Plan / ออกแบบ Disaster Recovery Plan กันอย่างไร เป็นต้นครับ มันเลยเป็นที่มาของ Blog นี้ด้วยครับ ที่มาสรุป Keyword ต่างๆ ที่สำคัญกันครับ
Disaster คือ อะไร ?
- เหตุการณ์ที่ผิดแปลกไปจากสถานการณ์ปกติ เช่น เครื่อง Server พัง, Network ขาด, ไฟไหม้ หรือ ตึก DC โดนตัดไฟ เป็นต้น
- แม้ว่ามันจะเป็นเหตุการณ์ที่ไม่เจอประจำ แต่เราต้องเตรียมแผนรับมือ โดยจะได้ยินคำว่า
- BCP (Business Continuity Plan) แผนที่ทำให้ธุรกิจดำเนินต่อเนื่องได้แบบไม่สะดุด อันนี้จะมุมของ Business
- DRP (Disaster Recovery Plan) แผนที่ช่วยกอบกู้สิ่งที่สนใจ จากสภาวะที่แย่ที่สุด กลับมาพร้อมทำงานได้รวดเร็ว โดยสิ่งที่สนใจ ถ้าในงาน IT ระบบ IT แต่ถ้าเป็นธุรกิจอื่นๆ อาจจะเป็น Business Unit ต่างๆ ครับ สำหรับผมตัว DRP เหมือนเป็นแผนที่ช่วย Support BCP ในเคสที่แย่ที่สุดครับ
จากที่เล่าเรื่อง Disaster ไปและมาถึง Disaster Recovery จริงๆ อาจจะไม่ต้องอธิบายความหมายแล้วก็ได้นะครับ มัน คือ การกอบกู้สิ่งที่สนใจ จากสภาวะที่แย่ที่สุด ให้กลับไปสู่สภาวะปกติ ตอนนี้ผมขอ Focus ไปที่ระบบ IT แล้วนะครับ มันจะเป็น
การกอบกู้ระบบ IT จากสภาวะที่แย่ที่สุด
IT Disaster Recovery
ตอนนี้มาถึงจุดที่ต้องดูแล้วครับ Disaster Recovery ทำแบบไหนดี งบอาจจะไม่มี เราเลยต้องมีตัวเลข 2 ตัวมาช่วยในการตัดสินใจครับ RPO และ RTO (แถม RTA)
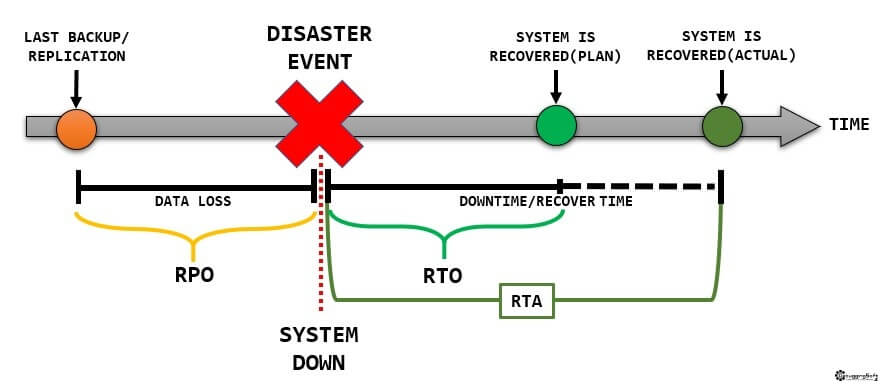
RPO : Recovery Point Objective
- ระยะเวลาสูงสุดที่ยอมให้ข้อมูลเสียหายได้ ตัวเลขนี้มาจาก Business เป็นคนกำหนดนะครับ
- ปกติจะกำหนดเป็นตัวเลขที่ชัดเจน เช่น 4 ชั่วโมง หรือ ยอมหายได้ 50,000 Transaction ส่วนใหญ่นับเวลาเป็นหลักครับ
- ตัวอย่าง : ข้อมูลใน Database เสียหายตอน 12:00 แต่ข้อมูลที่กู้มาให้ได้ คือ ข้อมูลที่ Backup ไว้ตอน 06:00 แสดงว่า RPO 6 ชั่วโมง
- ตัวเลขที่กำหนดมันผลกับ Policy การสำรองข้อมูล
- Backup: ถ้ากำหนด RPO 4 ชั่วโมง ต้องทำ Job Backup สำรองข้อมูลไว้ทุก 4 ชั่วโมง หรือน้อยกว่านั้น
- Backup + Snapshot: ทำ Full Backup มันกิน Disk เลยมีทำ Snapshot มาช่วย เพื่อลดพื้นที่ที่ใช้
- Replication + High Availability: ตรงนี้ช่วยลดปัญหาว่าต้องมา Backup บ่อยๆ อาจจะมีปัญหาเรื่อง Disk/Tape ได้ โดยการเพิ่มเครื่องขึ้นมาอีกเครื่องที่อยู่อีก Site (DR Site) แล้วส่ง Transaction Log ไป ซึ่งตรงนี้จะช่วยลดค่า RPO ได้มากเลยครับ เกือบ Realtime แต่ขึ้นกับปัจจัย Network / เทคโนโลยีที่ทำ Replication
RTO : Recovery Time Objective
- ระยะเวลาสูงสุดที่ยอมรับได้ให้ระบบหยุดทำงาน เพื่อที่จะกอบกู้ระบบขึ้นมาครับ
- ถ้า RPOทำให้เกิดการ Backup / Replication ตัว RTO เป็นส่วนของการกอบกู้ระบบ ตรงนี้มองได้หลายมุม อาทิ เช่น
- Restore ระบบขึ้นมาจาก Backup
- Switch ระบบจากเครื่อง Server อีกเครื่องที่มีการทำ Replication VM หรือ Database มาแล้วครับ
RTA : Recovery Time Actual
- ค่า RTO + ระยะที่ระบบสำรองข้อมูลพร้อมใช้งานครับ ปกติแล้ว ถ้ามีการลงทุนกับระบบไป เช่น มีการทำ Failover ค่า RTA จะพอๆกับค่า RTO ครับ
- หรือ บางองค์กรจะมองว่า RTO (ค่าที่ได้จากการวางแผน) และ RTA (ค่าที่ได้จากการซ้อม หรือการแก้ไขปัญหาจริงครับ)
ค่า RTO / RPO ถ้าต้องการกดให้ค่าน้อยๆ มันหลายปัจจัย
- เข้าใจสถานการณ์ของธุรกิจตัวเอง
- ถ้าขาดระบบไป ยอมแก้ปัญหาตามแผนแบบ Manual ไปก่อนสัก 3-4 ชั่วโมงได้ไหม
- การวางสถาปัตยกรรมของระบบ
- มีกี่ Site
- แยก Logical/ Physical Server ไว้ไหม
- Bandwidth Network กำหนดไว้เท่าไร้
- เทคนิคที่เลือกใช้
- Backup/Restore
- Replication
- Failover Cluster หรือ Active/Standby
- NOTE: ศัพท์ตรงนี้หลายๆ Vendor อาจจะใช้คำที่แตกต่างกันได้ครับ
- Policy ขององค์กร
- บางที่ต้องทำเรื่องอนุมัติก่อน หรือ ทำได้ในเวลาราชการเท่านั้น !!!
- งบประมาณ
- RTO / RPO น้อยๆ ยิ่งใช้งบประมาณสูงขึ้น
- ลูกค้าบางที่อยากได้ระบบที่ Zero Downtime แต่งบได้ Physical Server 1 เครื่อง มันก็ทำไม่ได้นะครับ
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.