
หลังจากมี Blog เกี่ยวกับ Execution Plan ไป 2 ตอนแล้ว
- [DB2] ลองใช้ Execution Plan เพื่อดูว่า Query ที่เขียนนั้นแย่ หรือไม่
- [DB2] แค่เปลี่ยน Query ชีวิตก็ดีขึ้นแล้ว JOIN vs Sub Query
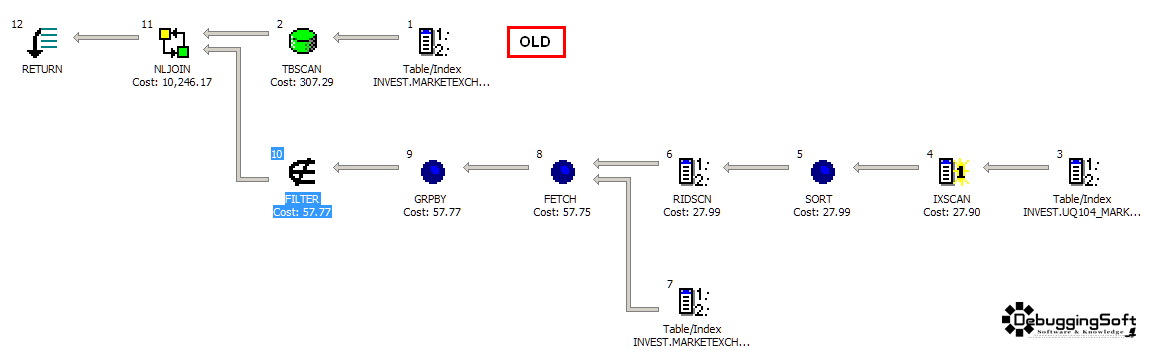
ถ้าลองสังเกตุดีๆ ตอนที่มันสร้าง Flow ขึ้นมา มันมีกล่องแทนการกระทำต่างๆ เช่น FETCH, TBSCAN เป็นต้น ซึ่งถ้าลองย้อนกลับไปในตอนเรียนวิชา Database มันมีหัวข้อนึง ชื่อ Query Optimization ทำอย่างไรให้ Relational Algebra (Low Level จาก SQL ครับ จริงๆตัว SQL ที่ใช้เบื้องหลังมันก็ไปแปลงกลับเป็น Relational Algebra) หรือพูดง่ายๆ คือ Query ดึงข้อมูลได้มีประสิทธิภาพครับ โดยคราวนี้เราสนใจเฉพาะกลุ่ม Join ครับ
นอกจาก INNER JOIN, RIGHT JOIN และ LEFT JOIN มันมีอะไรที่ลึกล้ำกว่านี้อีกเหรอ คำตอบ คือ มีครับ มองว่าเป็น Algorithm ที่เอามาจัดการกับข้อมูลที่ต้องการครับ โดยผมขอ Focus ที่ตัว DB2 ก่อนนะว่า มีอะไรบ้าง เอาเฉพาะที่โผล่มาใน Execution Plan บ่อยๆนะครับ
NLJOIN (Nest Loop Join)
- Nest Loop Join
- เอาข้อมูล 2 แหล่งมาไล่จับคู่กันตรงๆ จับไปเรื่อยๆจนกว่าจะครบทั้ง 2 ฝั่ง นึกถึงภาพของ Buble Sort ยังไงไม่รู้
- เหมาะกับการจัดการกับข้อมูลน้อยๆ
- ต้องศึกษาลึกๆ ว่าในตัว DBMS ทำ Nest Loop Join โดยเริ่มจากอะไร เช่น
- เอา Table ในฝั่งไหนเป็นหลัก ฝั้งซ้ายไปไล่จับคู่กับฝั่งขาว
- เอา Table ที่ Row น้อยกว่าตั้ง แล้วไปไล่จับคู่กับอีก Table
- จาก Blog ตอนที่แล้ว ที่ Query แรก มันนานก็เพราะแบบนี้แหละ ตัว DBMS มันเลือกใช้ NLJOIN กับข้อมูลเยอะๆ ทั้งสองฝั่งครับ
SELECT MEX.CREATEBY
, MEX.CREATETIME
, MEX.PROVEBY
, MEX.COMMODITYID
, MEX.QUOTEDID
, MEX.PROVETIME
FROM MARKETEXCHANGE MEX
WHERE MEX.ACTIVEFLAG = 'A'
AND MEX.CREATETIME = (
SELECT MAX(ME2.CREATETIME) AS CREATETIME
FROM MARKETEXCHANGE ME2
WHERE ME2.ACTIVEFLAG = 'A'
AND MEX.COMMODITYID = ME2.COMMODITYID
AND MEX.QUOTEDID = ME2.QUOTEDID
)
MSJOIN (Merge Scan Join)
- Merger Scan Join หรือ Sort Merge Join
- เหมาะสำหรับข้อมูลที่มีขนาดไม่ใหญ่มาก และตัว Query มีการใช้ Operation ประเภท (Inequality Condition) เช่น <, <=, >, >= เป็นต้น จากนั้นมาจับคู่ข้อมูล
HSJOIN (Hash Join)
- เหมาะกับข้อมูลที่มีขนาดใหญ่ และตัว Query มีการใช้ Operation ประเภท (Equijoin) คือ =
- แบ่งข้อมูล เป็นชุดย่อยๆในหน่วยความจำ จากนั้นมาจับคู่ไปเรื่อยๆจนครบ
- ปกติ ส่วนใหญ่จะเจออันนี้นะ ถ้าอยากให้ HSJOIN แล้วเร็ว ก็ต้องเพิ่ม Memory ครับ (Money Power 555)
- ถ้ามีแบบนี้เยอะ - แสดงว่า Index กับ Statistics ไม่ดี ควรทำเพิ่มนะ
จบไปกับ Blog อีกตอนที่อาจจะเขียนแล้วดูงงๆนะครับ
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.

