
สำหรับ Blog เป็นทีมย้อนหลังครับ เคลียร์ธุระจบ ผมฟังช่วงวันเสาร์เย็น ตอนแรกแปะ Note ลงเจ้า Si Yuan แต่ไหนเขียนมายาวและ เอามาแปะลง Blog ด้วยดีกว่าครับ หัวข้อที่จดมาตามนี้เลยครับ
Observability 101 — ปูพื้นฐาน Observability
Speaker Jirayut Nimsang
สำหรับคำว่า Observability มันจะมี 2 คำที่เกี่ยวข้อง Monitoring / SRE
- Monitoring - เก็บข้อมูลเยอะที่สุด เพื่อมาดูตอนที่เกิดปัญหาแล้ว หา Log / Pattern แต่ทว่าพอระบบขยายมากขึ้น ทำเป็น Distribute / Microservice มากขึ้น ข้อมูลมันมาจากหลายแหล่ง เยอะ และจัดการยาก เรารู้แค่ว่า Dashboard มัน Spike ขึ้นมาเยอะเลย เพราะ ทีม Support แจ้งว่าเว็บมาช้ามา เจอ Code xxx แต่ไม่รู้ว่ามีผลกับ Business ไหม ? ต้องมาไล่หาว่าอะไรที่มีปัญหา เช่น ส่วนที่ต่อกับ payment เดี้ยง หรือ promotion เดี้ยง เป็นต้น
- Observability - ดูจาก Top Down เอาง่ายๆ ตั้งคำถามก่อนว่า อยากรู้อะไร เอามาตอบเรื่องไหน / Business Impact แล้ว Design การเก็บ Metrics / Logs / Traces ให้ล้อกัน
- SRE - สั้นบอก Action + Improve ลองดูจาก Blog National Coding Day 2026-SRE Deep Dive
-Observability ?
มาจากข้อมูล 3 ส่วน Metrics / Logs / Traces และอาจจะมีพวก Profiler / Events Dump มาเสริม โดยเน้น 3 ตัวหลัก
📌Metrics - ค่าของสิ่งที่สนใจ พวก CPU / Error Code ณ เวลาใดเวลานึง ถ้าภาษา Data เป็น Time Series ที่เอาข้อมูลพวกนี้มาทดไว้ ตาม Sample Rate ที่กำหนดไว้ โดยมี Open Source ของ Time Series DB (TSDB) มี
- Promethenus (Single)
- Thanos - For Scale But Require Promethenus
- Cortex - CNCF Can Scale
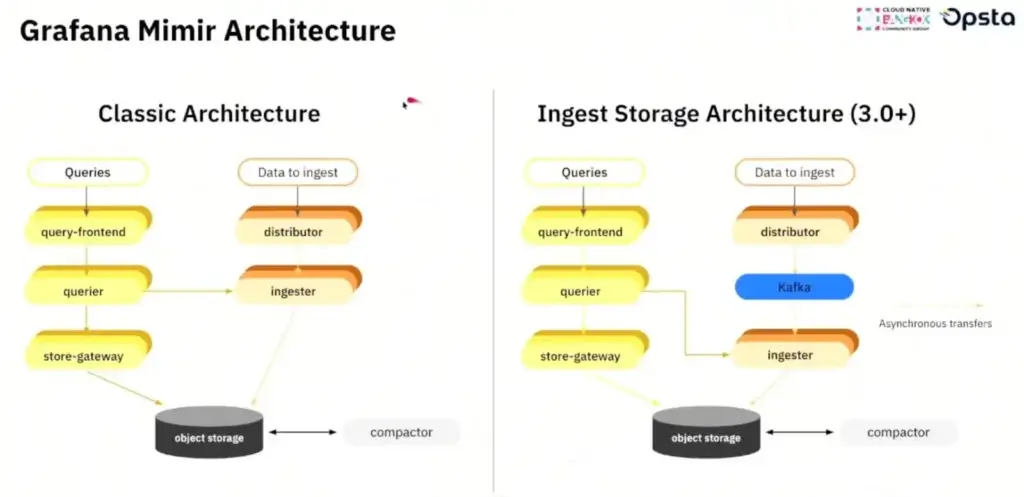
- Mimir - Grafrana fork Cortex และใน Ver 3 มีปรับ Arch ใหม่ แสดงว่าต้องมาขยับแล้วสินะ 55 มีเพิ่ม Kafka เพื่อรองรับ load เยอะ 10 Billon / Sec เดิมลง Object Storage
📌Logs - ข้อมูลที่เป็น Column อย่างเวลา - message มีระบบย่อยเยอะ แล้วเราจะมี Standard ยังไง ?
- Logs Source Console / Stream / File หลังๆ Prod เป็น Stream และมี Centralize Tools มาจัดการ Log ปรับ Standard
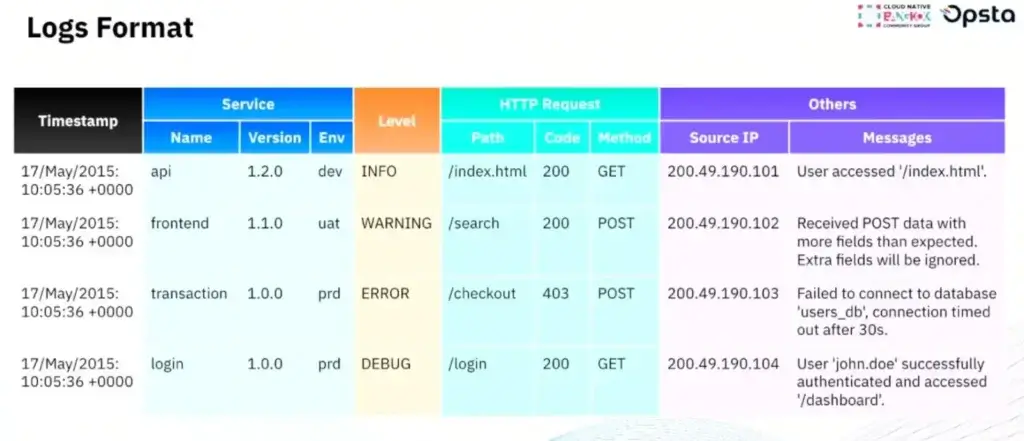
- Logs Format - ถ้าไม่ตกลง Pattern ชัดเจน มันทำตัว log parser ยาก ตอนนี้ถ้าเป็นไปได้ใช้ json หรือ logfmt (key value) ข้างในควรมีอะไรตามรูป
- สำหรับในส่วน Log มี Open Source อย่าง Loki

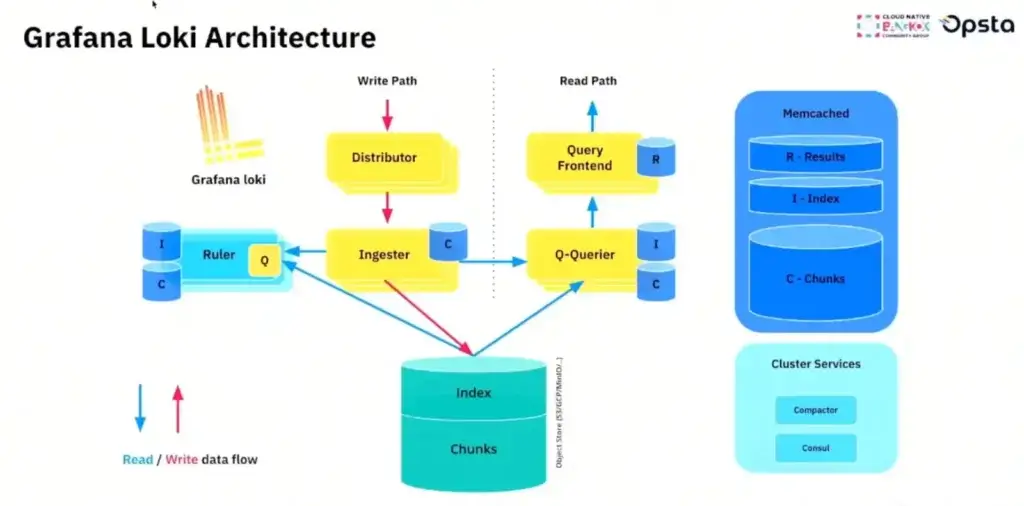
ข้างใน loki เก็บแบบ Time Series โดยการเราดึงข้อมูล ตามเวลา มาจาก Label ที่กำหนดไว้ แต่ต้องเลือก Index ให้ดี พวก Log Level / Service Name อย่างเราพวกที่ข้อมูลมันหลากหลายไป เช่น พวก IP เพราะมันหลากหลายไป index แตกไปก่อน มันเก็บ index ใน ram แล้ว ถ้าเราอยากดู Detail มันจะไปดึงจาก Object Storage
📌Traces - บอก Timeline Req ว่ามันไปแวะที่จุดไหน ใช้เวลานานเท่าไหร่ ข้อมูลของ Trace จะมี 2 อันที่ต้องรู้
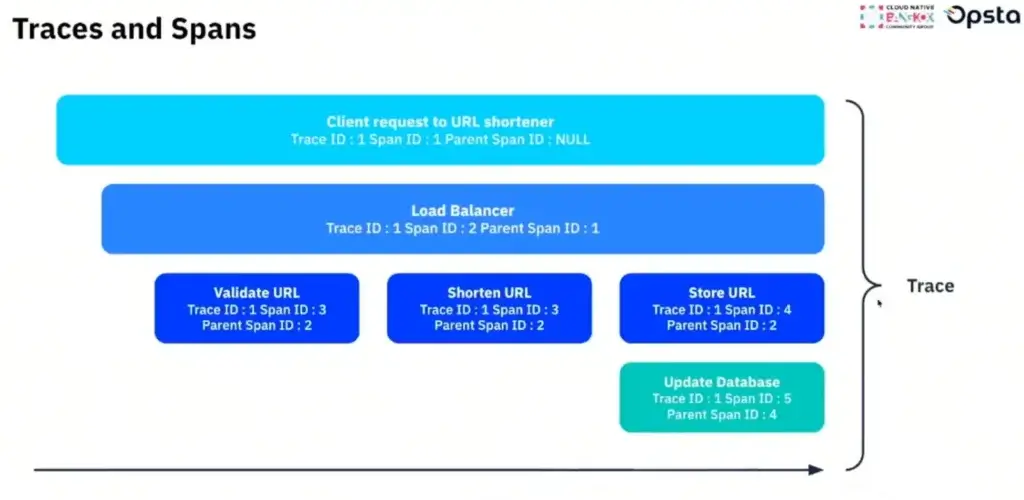
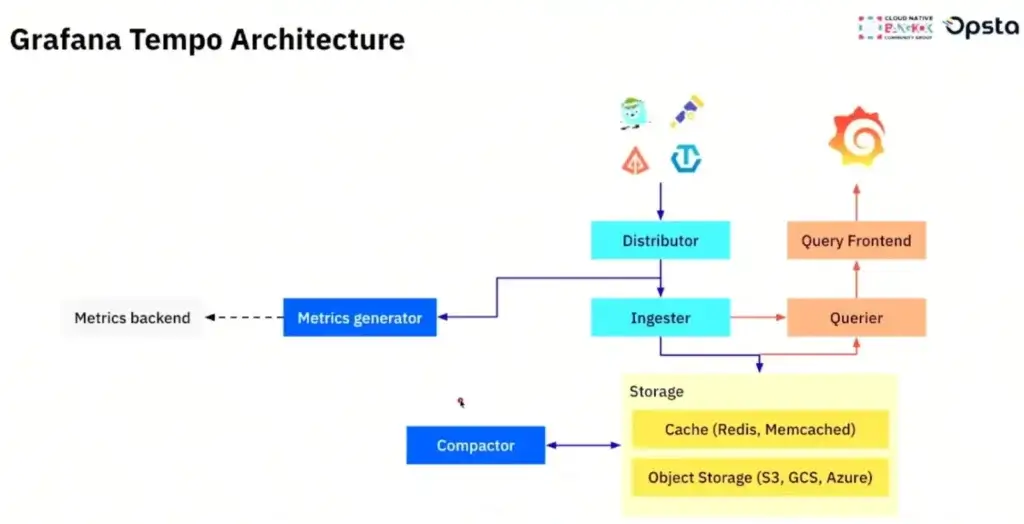
- Traces - เส้่นทางที่ Req มันไป
- Spans - จุดที่ Req มันแวะ เช่น Load Balance / Service A / Service B / DB เป็นต้น
- Open Source จะเป็นตัว Tempo มันเก็บเส้นทาง ลง Object Storage
-Observability Correlation
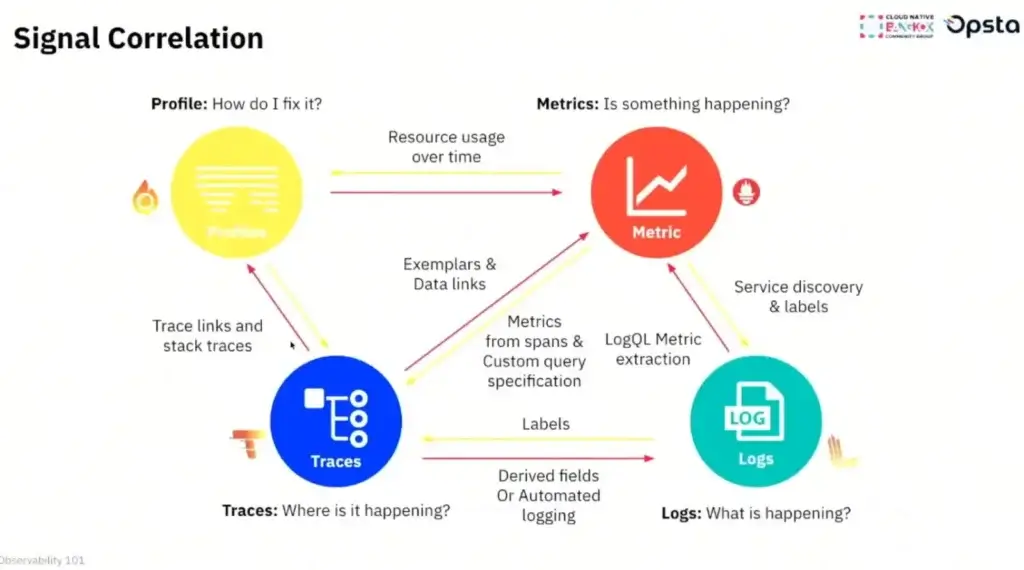
การเอา 3 signal มาเชื่อมความสัมพันธ์กัน Metrics / Logs / Traces หรือ ถ้ามีข้อมูลขาใดขานึง เราสามารถสร้างอีกมุมออกมาได้ อย่าง เช่น
- เอา Traces > Metrics เช่น เอามานับว่าจุดที่แวะ (Spans) แวะกี่รอบ / Latency เท่าไหร่ / มี Error Rate ไหม เป็นต้น
- Service Graph - เอา Trace ที่สนใจมาแสดงผล Graph เห็นว่าแวะที่ไหนบ้าง
- Traces <=> Log บอกของในเวลานั้นที่เกี่ยวกัน ใน Grafana Exemplars
-Observability Volume
- Metric - Aggregate มาแล้วเก็บได้นาน
- Logs - เก็บตาม Regulation พรบ คอม 90 วัน หรือ ตาม Biz Sector นั้นๆที่กำหนด
- Traces - ใช้พื้นที่เยอะ ช้วงนี้ Disk แพงด้วย โดยจะเก็บเป็น Sample เช้น อาจจะเอาเคส Error อย่างเดียว เป็นต้น
-Collector
ตัวที่ส่ง Observability Data ออกมาให้ มี Open Source CNCF หลายตัว
- Elastic Logstash / beats
- fluentd / fluentbit
- OpenTelemetry
- Grafrane Alloy
-OpenTelemetry
📌Standard การส่ง Observability Data เป็น Framework ช่วย Gen Collect Export ข้อมูลไปยัง DB โดยจะใช้ Tools กับค่ายไหนก็ได้นะ โดยขา App มี 2 แบบ
- Auto Instrumental - Add Lib ปุ๊บมันจะ Gen มาให้ แต่ต้องไปดูว่า แต่ละ ภาษา Framework ทำได้ขนาดไหน
- Manual Instrumental - เขียน Code ยัดเอง
📌Grafana Beyla - เป็นอีกเทคนิคนึง ไม่อยากไปแก้ Code แต่เอาส่องข้อมูลใน Kernel ออกเป็น Observability Data
- ข้อจำกัด มันจะลงลึก Function / Method ได้ ต้องใช้ Manual Instrumental
- ตอนนี้ยังใช้ Linux Kernel 5.8+ BTF Enable และ Agent ใช้สิทธิสูงขอส่อง Kernel
โดยใน OpenTelemetry มีตัวนี้นะ eBPF Instrumentation (OBI) มี Version Alpha มาแล้ว รอมาตรฐานทางการ
-Visuallization
ตอนนี้มี 2 Idea
📌USE Method - Monitoring เดิม เน้น Utilization / Saturation (งานที่ค้าง - Queue Length Connection Limits) / Error
📌RED Method - ตัวควรทำ Waroom วัด Business Impact / Use Experience
- R - Request
- E - Error
- D - Latency เข้า แล้วช้าไหม ช้าแล้วคนเยอะ หรือน้อย
มุม SRE - ลองดูจาก Blog National Coding Day 2026-SRE Deep Dive
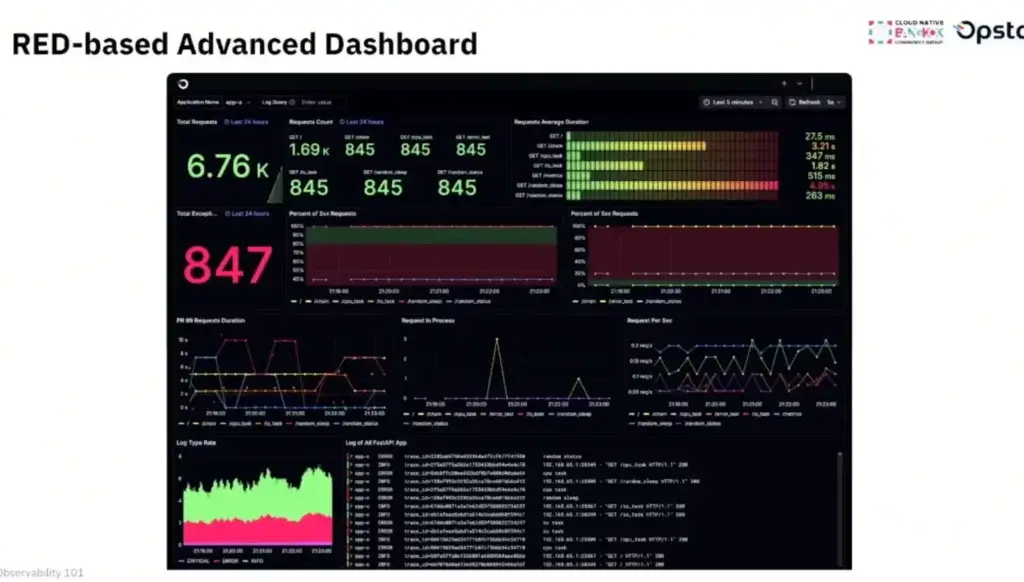
RED Simple / RED Advance เอา RED มาปรับตามคำถามทาง Business Impact ที่เราอยากรู้ เช่น API ที่สำคัญ และ Log ที่เกี่ยวข้อง
Agentic Observability & Incident Response on K8S
Speaker Thanachai Pramewitayapoori / Fukiat Julnual / Wanich Keatkajonjumroen
การทำ Observability ต้องมาเข้า Nature ของ App ก่อน
- ว่ามี Profile แบบไหร CPU / Mem / Network ถ้าเราไม่รู้ Profile ว่า App แบบไหน มันจะหา มันจะได้ Solution ที่ไหมเหมาะ อาทิ เช่น เรื่อง Auto Scale ถ้าเราไม่เข้าใจ มีผลกับ Cost
- Trace ช่วยแก้ปัญหา ที่เกิดบ้างไม่เกิดบ้างได้
-Observability Stack ที่ AWS
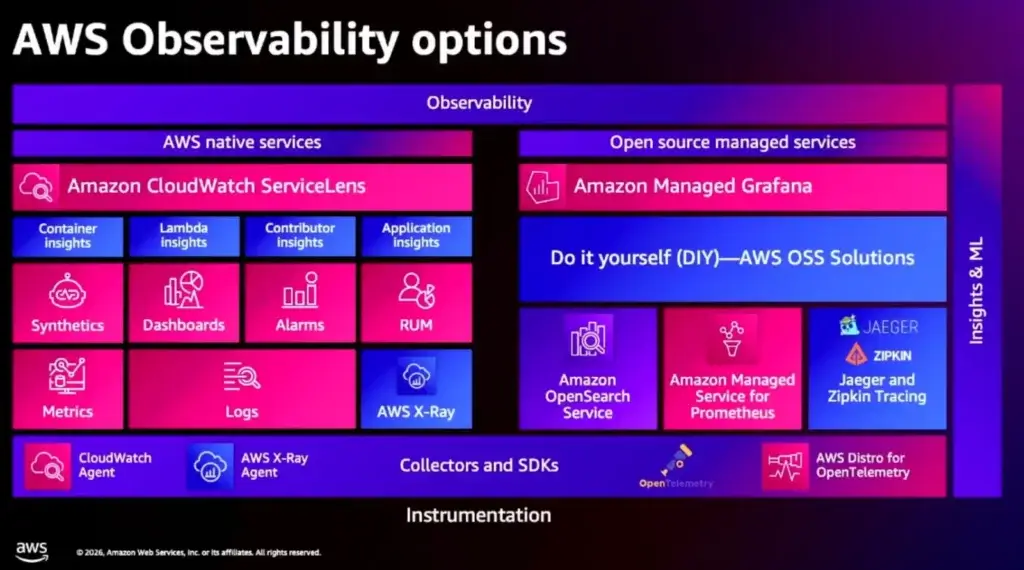
🗃️Observability Stack ที่ AWS ตัว Open Source มีแบบ Manage Service ให้ใช้ลงง่าย
🗃️AWS - Frontier Agent เอา Agent ที่เอา Observability Data มาช่วยจัดการงาน Operation + Incident Response โดยจะเอา Metrics / Logs / Traces + Correlation มาใช้
📌Logging on K8S
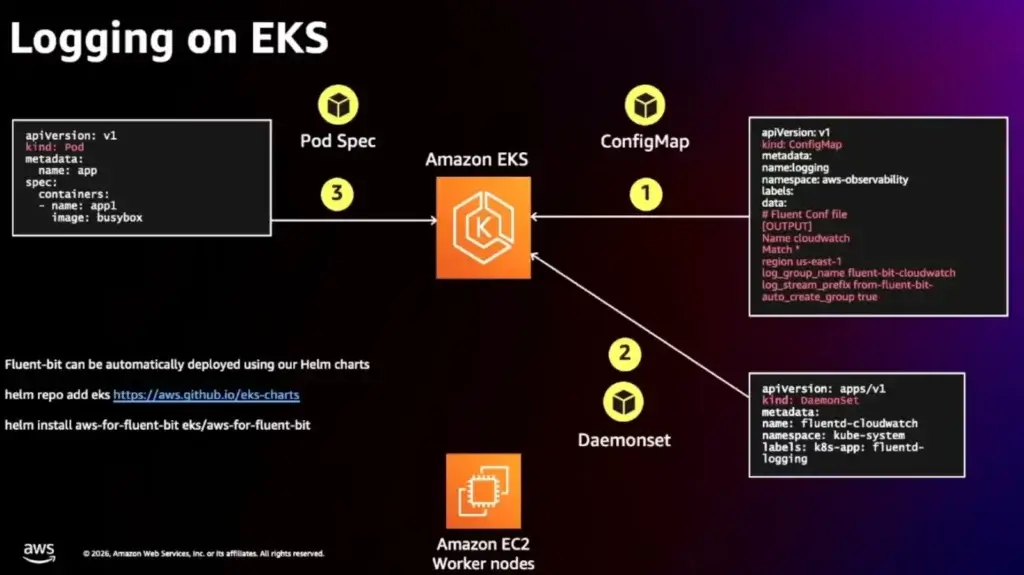
- ControlPane มีกลุ่ม log ตามนี้ api (API Server Component Log) / audit / authenticator / controllerManager / scheduler
* ปกติ ต้อง scrap เอง แต่ใน AWS มี CloudWatch มันมาดัก Log จาก Control Pane ได้เลย - Application - ปกติให้ CloudWatch ดูได้ แต่เอาตัว fluentbit (helm) / xxbeats เอามาเข้าพวก elasticsearch เป็นอีกทางเลือกนึง
📌Metrics on K8S
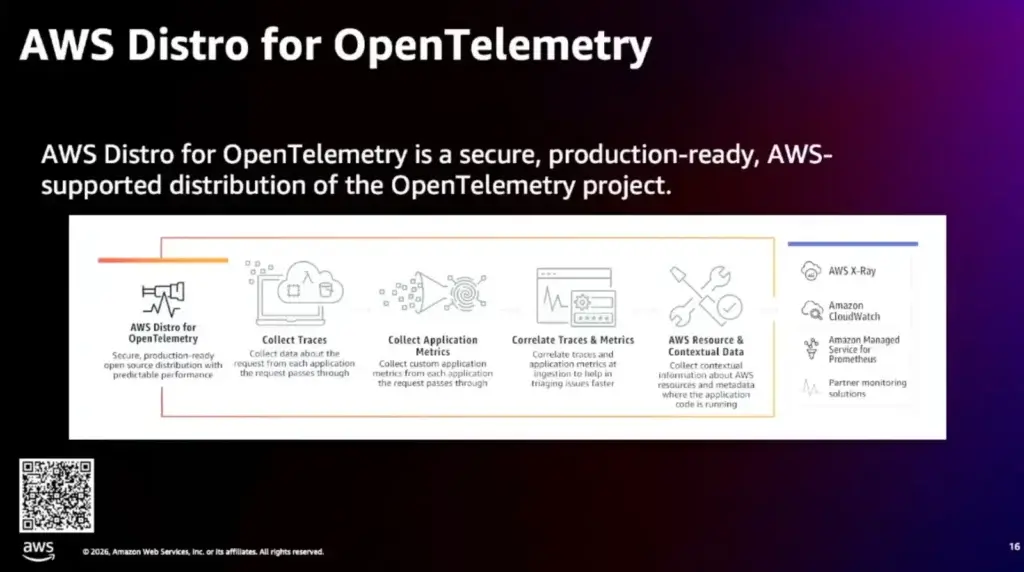
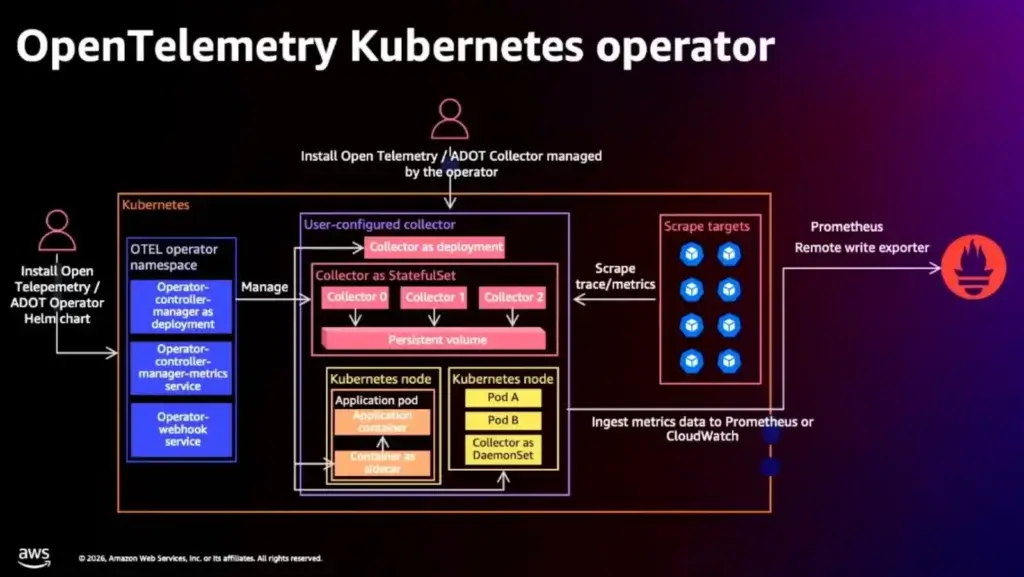
- Open Telemetry ก็ดึงได้นะ
- แต่ถ้าเน้นไว้ง่าย ใช้ AWS Distro For Open Telemetry (ADOT Collector) เตรียม Template ให้แล้ว และส่งที่ไหนมีระบบจัดการให้ ลงเป็น DaemonSet และเลือกส่งออก Observability ค่ายไหน Open Source / Commercial
- เก็บ Metrics ลง Manage Prometheus ไม่ต้องมา Setup จัดการเอง แต่เสียเงิน
📌Trace on K8S
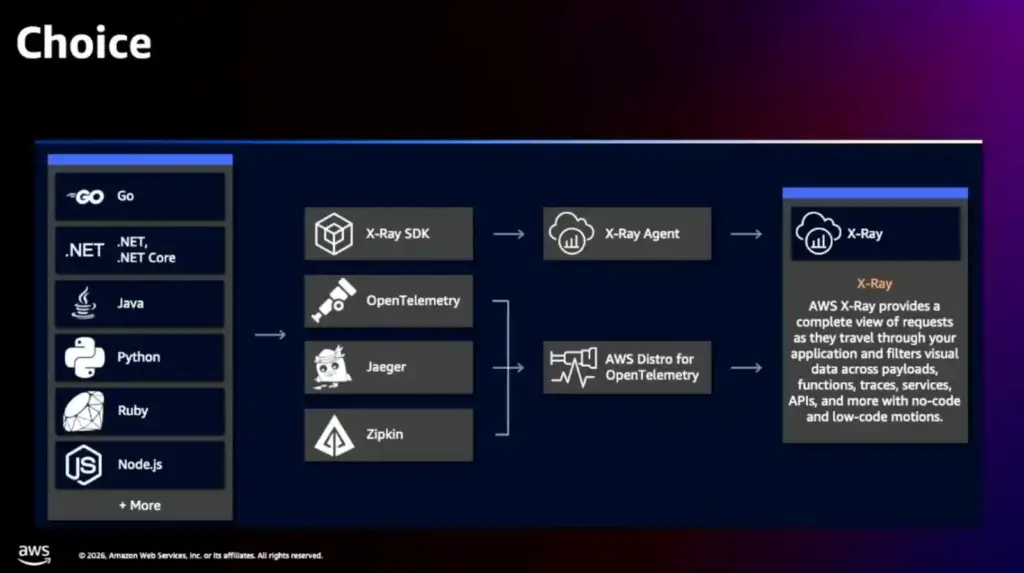
- Choice มีหลายท่า ตามรูปเลย ถ้าบน AWS X-Ray หรือ Open Source อย่าง Open Telemetry / Jaeger / Zipkin
- พวก OTLP Collector ส่งเข้า CloudWatch ได้เหมือนกัน
- ถ้ามี Trace เรามี Graph View บอก Component ได้นะ
📌Visuallization ส่วนการแสดงผล AWS มี
- Manage Grafanaให้ติดตั้ง และเชื่อมต่อกับ Service ต่างอย่างพวก Logs Trace Metrics
- หรือ ตั้ง Grafana เองในกรณีที่อยากคุม Cost
-AI For Observability (AWS DevOps Agent)
📌คำถามที่เจอประจำ
- Why is the catalog service slow?
- Check the health of my EKS pods
- What's causing high CPU on the catalog service?
- Show me recent errors in the orders service logs
- Why is the website not loading?
- Are there any pod restarts or OOMKills?
📌แล้วความยากของการหาคำตอบ เราไม่รู้ภาพรวม/ปจจุบัน เวลามีเคสหลักประชุม / WarRoom เพราะ
- Application Complexity - ไม่มีใครรู้หมด App Infra ต้องมาสุมหัว
- Telemetry Data ต้องใช้จุดไหน Tools ไปดู Dashboard ไหน
- firefighting vs systematic improvement ดับไฟ กับ improve มันยากเหมือนกัน ว่าปะติดให้มี Tech Dedt อยู่ต่อไป หรือ ทำให้มันดีขึ้น
📌AI มาช่วยยังไง
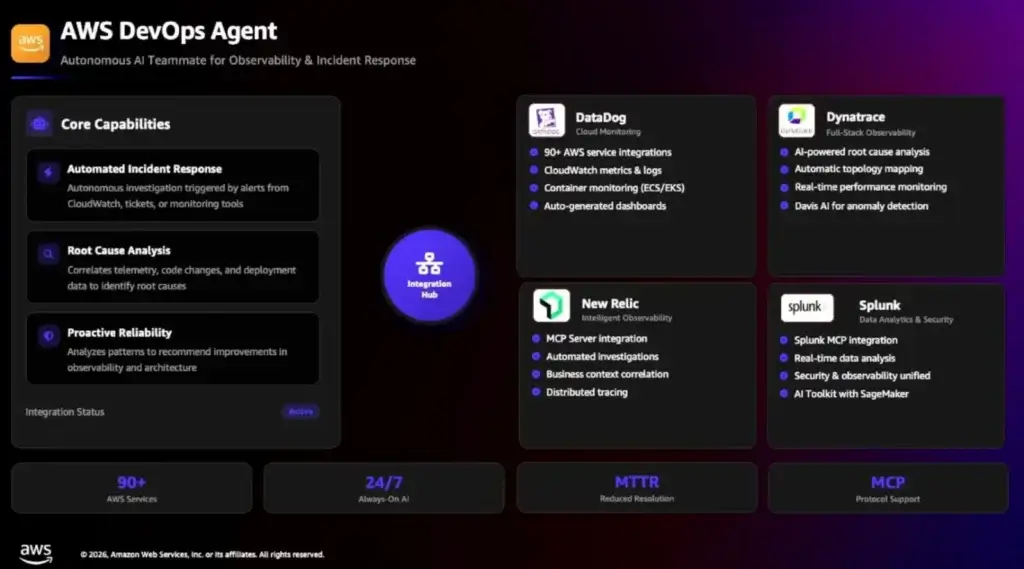
AWS DevOps Agent (Preview ตอนนี้ฟรี) เข้ามาทำงาน Always-on, autonomous / Identify Root Cause, Recommend Improvement / Find Insights (Arch ของจิงตอนนี้ยังไง จะได้ Apply Solution) หนือ ต่อกับ MCP เพื่อไมให้ AI หลอน
- Prompt เพื่อเวลามีเคส
- เอา Observability มาสรุปให้เราให้เป็นคำพูดที่ทุกคนเข้าใจได้ยังไง
- หรือทำในเคส Proactive ก็ได้ ถ้าเจอแนะนำ Play Book ที่ทำเคยทำไว้
สำหรับ Demo จำลองว่า ให้ Container (Throttling) บีบ mem limit น้อยๆ แล้วเอา Sidecar ที่ใช้ CPU สูงยัดเข้าไป โดยมี Arch ตามนี้
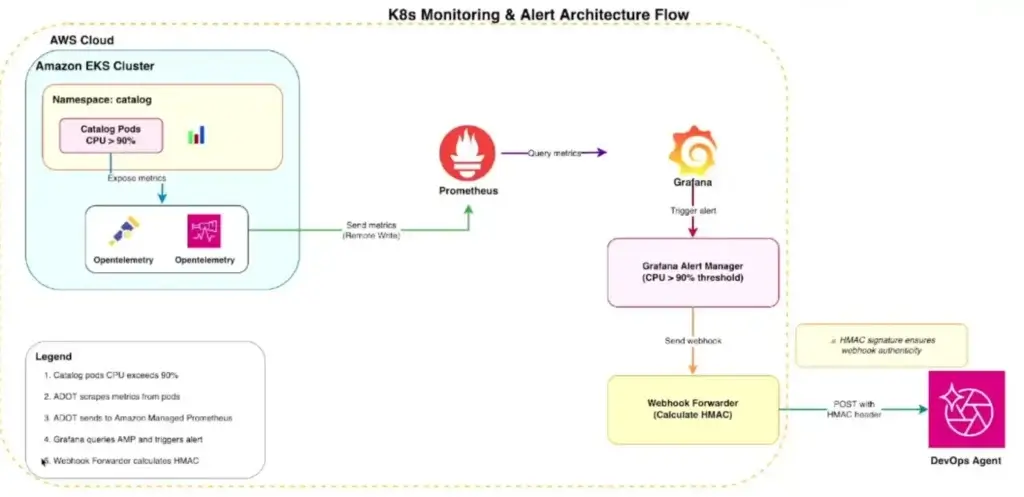
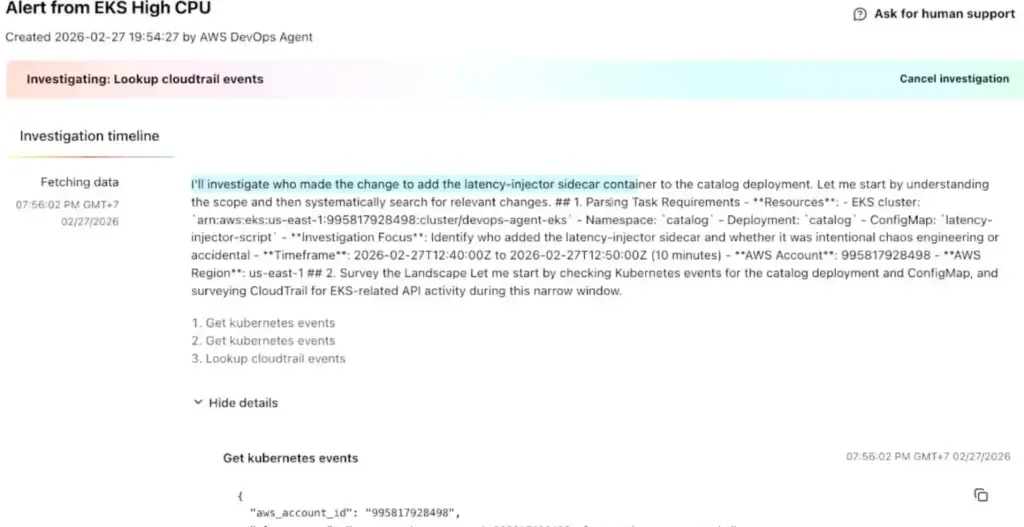
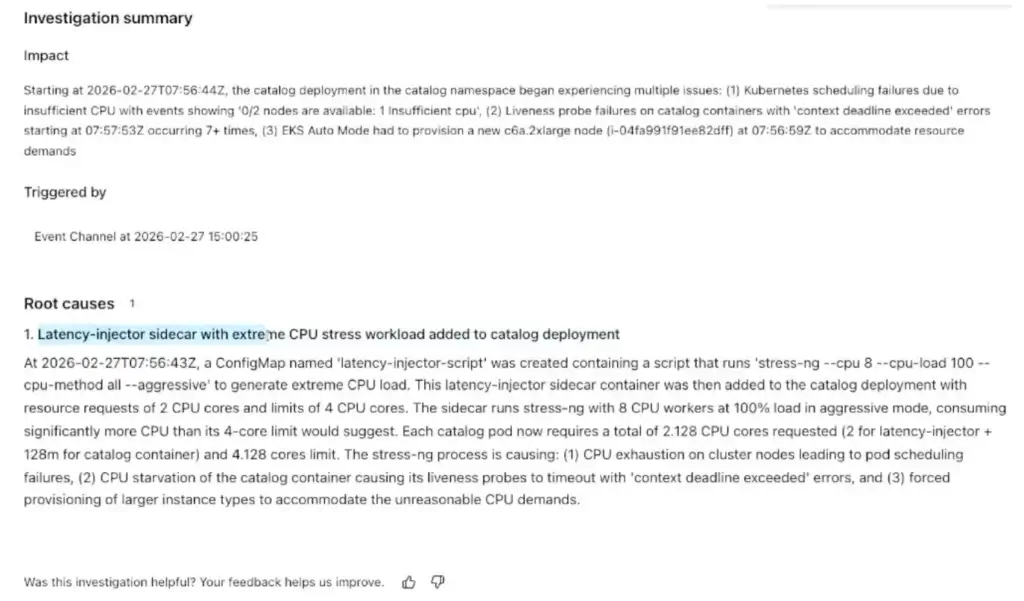
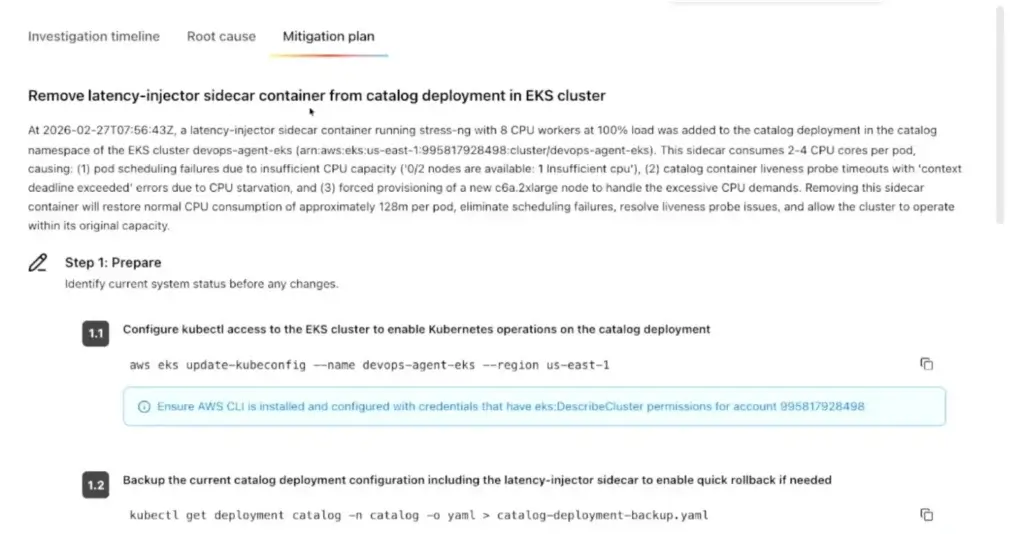
- AWS DevOps Agent มี web hook กับทาง Gafrana ถ้า High CPU Alert มา มันจะเข้ามาจัดการ โดยดู Deployment / Log / Metric มาหา
- Root cause
- Mitigation Plan
- Prevention Plan หรือ post mortem (Schedule มาตรวจเป็นรอบๆ) - นอกจากนี้ยังเชื่อมกับ Tools แต่ละเจ้า Splunk / Dynatrace / Data Dog / New Relic ได้ด้วย จะได้ดูภาพรวมทีเดียว
แต่ลองฟังแล้ว เพราะเวลามีเคสจริง ทีมที่ดูใหญ่มาก มันจะมีปัญหาของ SILO กว่าคุยกับเสร็จ (ตอนเป็น Vendor ไปดูเคสลูกค้าเจอแบบนี้เหมือนกัน ขออะไรมายากเลย) อันนี้เอา AWS DevOps Agent มาเตรียม Draft ให่ก่อน แล้ว Human in The Loop ตอน Approve / Action ได้่
Load Test หรือ จำลองสถานการณ์ที่ย้ายไป DR ใช้ AWS Fault Injection Service
DeepFlow — การทำ Observability แบบ Zero Code (eBPF)
Speaker Saritrat Jirakulphondchai
CNCF Landscape ในส่วน Observability โตขึ้นเยอะเลยแฮะ โดยวันนี้คุณโจโจ้มานำเสนอตัว DeepFlow เป็น Tools Visualize Flow การไหลของ Data ที่ Zero Code จากพี่จีน มาดู Tech จากอีกมุม
-ทำไมถึงต้องมา Track
📌จากเดิม App Monolithic พอต้องรับ Load มากขึ้นจะมี Idea ของ Microservice
ถ้าไม่พร้อมมี Idea Design App แบบ Modular Monolithic ทำให้ App พร้อมแยกส่วน ถ้า Load เยอะถอด Module นั้นไป Scale
📌 พอของมันแยกชิ้นเยอะๆ
- ปัญหาการจัดการพวก Infra Kube ช่วยได้แล้วระดับนึง
- แต่ถ้าเราอยากรู้ว่าแต่ service มันยังอยู่ดีไหม
- ยุคแรก APM (Application Performance Monitoring) เอาไปวางข้าง App ลงเป็น Agent
- จากนั้นขยับมาเป็น Observability แต่มันมีประเด็นอยู่ของเราอยากติดตาม มันต้องส่งข้อมูลออกมาด้วย ถ้าเป็น App Dev ต้องมาแก้ Code ให้ หรือ เอา Agent มาห้อย มันมี Overhead + เสียเวลาปรับ เลยมี Idea ของ Agentless เบิ้องหลัง eBPF
-อะไร คือ eBPF
📌ก่อนจะเข้าไป eBPF ปกติ ตัว Kernel มันมีกระดาษทด 2 ส่วน
- UserSpace - ให้ App ทั้วไปมา Run พวก ls curl dotnet python java ...
- KernelSpace - ส่วนที่ OS จะมาจัดการเอง ถ้าใครจากใช้ของส่วนนี้ส่ง System Call มาขอ
📌อันนี้ถ้าใครอยากติดดู System Call
- strace
strace <executable / PID> - opensnoop-bpfcc - เป็น Tools อีกตัว
1. เรา Run Process App ไว้
2. แล้วเปิด opensnoop-bpfcc คู่กัน อีก Terminal มันจะบอก System Call ให้เลย ว่าทำอะไร อ่าน Disk ยิง Request เป็นต้น ภาพในหัวตอนฟังน่าจะแบบเดียวกัน Fuslog ของ dotnet เอาไว้ไล่ dll เอ๋อๆ
-จาก WebAPI มา eBPF
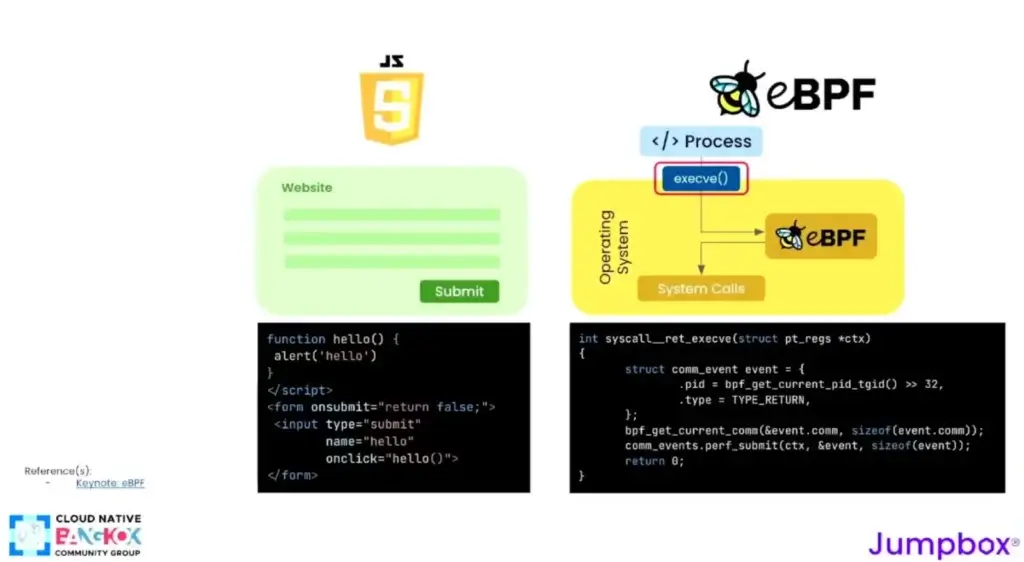
📌ถ้ามองถอยมาว่าจาก Web มา eBPF ยังไงต้อง ต้องมาเข้าใจ execve() // execve(appName, param[], env[])
- เพราะ execve มันทำหน้าที่สั่งใหั app ทำงาน
- ถ้าเราป้อน curl <your_dns> เข้าไปเจ้าตัว execve มันจะไปสั่งให้ curl ไปทำงานอีกที ทุก app บน Linux Base ผ่าน execve() อยู่แล้ว เลยเป็น Idea มาทำ Auto Instrumental โดยมาดักจับตรงนี้
📌เบื่องหลังของ eBPF Idea มาจากคุณ Brenden Gregg / Thomus Graf (Isovalent) มี 2 ส่วน 1. Runtime / 2. Language - ถ้าอยากคุม eBPF ใช้ ภาษา BPF
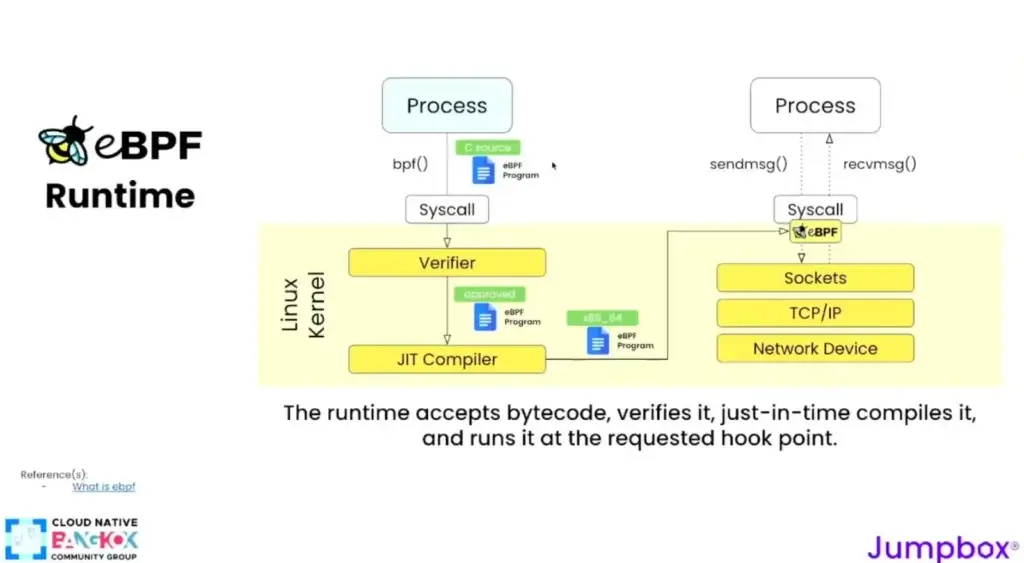
📌จาก App ที่เราเขียนกับพวก dotnet / java / python ... เวลามันอยากยุ่งกับส่วน kernel มีช่องทางที่เป็น Call มาเป็นภาษา C ข้างบนมันจะแปลงให้ บราๆ แล้วแต่มัน และมีขั้นตอนตามนี้
- Source Code - เขียนด้วย restricted C เราเขียนเอง หรือ ภาษาที่เป็น High Level แปลงมาให้
- compile bytecode - ภาษา BPF
- eBPF Verified - ตรวจสอบด้วย ว่าไม่ทำให้ HW ตาย เช่น Loop Hell / Pointer
- eBPF VM - เป็น JIT เอา bytecode มา Run
- eBPF map - ส่งผลกลับไป userspace
บางเคส eBPF ช่วยจริง แบบอยู่ๆ Tx Spike แบบงงๆ - bpfTrace จะเจอว่า Issue ขา HW
- DeepFlow มันจับพวก Observability ยังไง ?
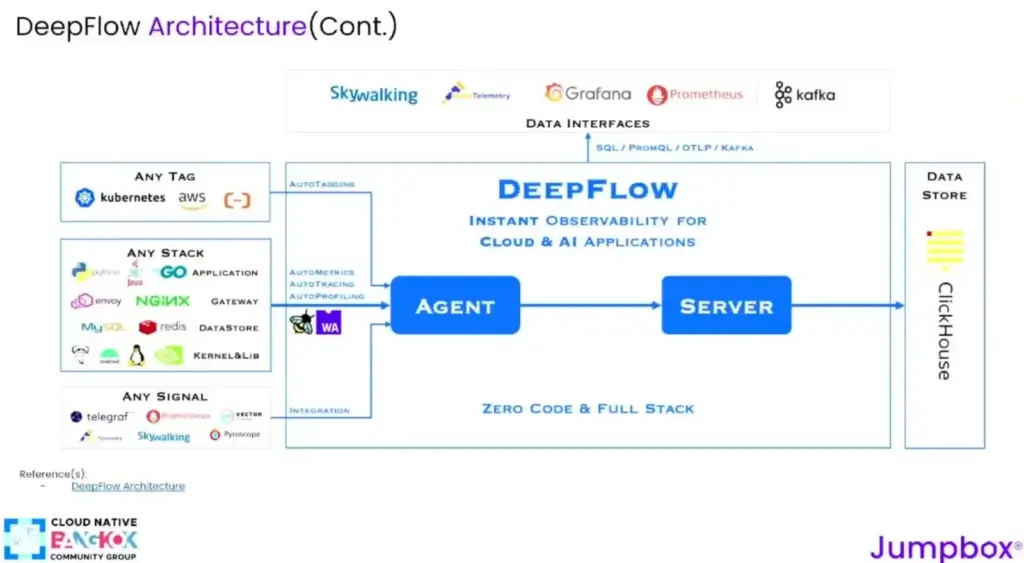
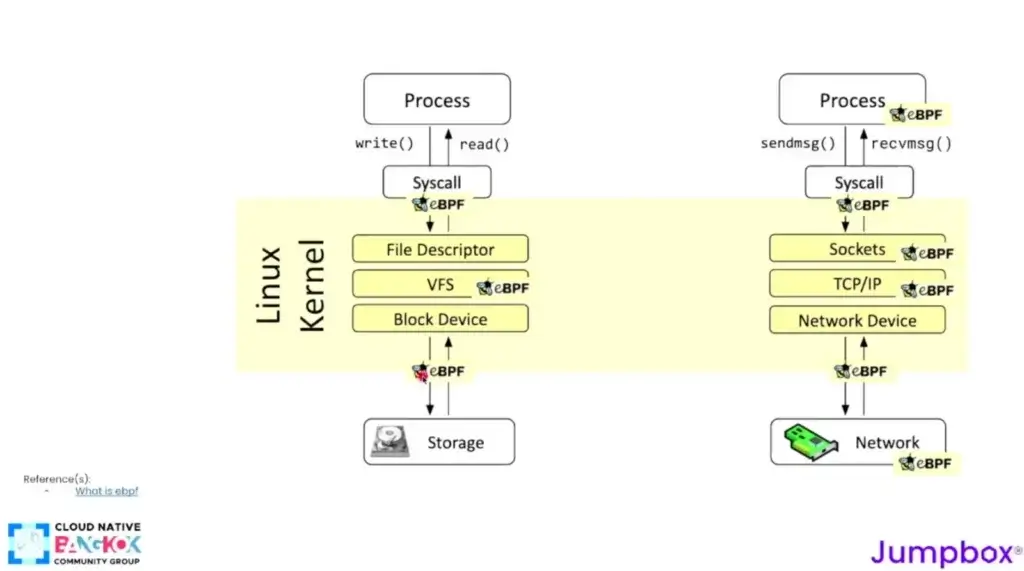
จากภาพ Process ข้างบนจะพบว่าเจ้า eBPF Process ที่จัดการพวก sockets > TCP > Device มันแอบมาเขียนดักช่วง system call ของ sendmsg() / receivemsg() เพื่อเอาผลที่ได้มาสรุป Observability พวก Req Rate / Error Rate / Latenct / Saturation
📌Key ก่อนใช้ ต้องดูก่อนว่า App ที่เรา Run มันมี Protocal ที่ DeepFlow ขอส่องได้ไหม ลองดู Feature Gemini สรุปมาตามนี้
- Language Java, Go, Python, C/C++, Rust
- Lib & Integration เชื่อมต่อ OpenTelemetry (ภาษาที่ยังไม่รองรับ ส่งมาทาง OpenTelemetry ได้) , Prometheus, SkyWalking, Telegraf
- DB จับข้อมูล MySQL, PostgreSQL, Redis, MongoDB, Kafka, Memcached
- Protocol: HTTP 1/2, HTTPS, gRPC, DNS, MQTT
- รองรับการเขียน Plugin เพิ่มด้วย Wasm
- มาเชื่อมกับ LLM ได้ด้วยนะ พวก OpenAI / Claude / Qwen หรือ Local จาก OLLAMA ก็ได้
📌ถ้าได้สิ่งที่ DeepFlow ทำ
- Service Map - ทำให็ความสัมพนธ์ และ Degree การไหลเข้ามา Component ที่สนใจ แบบถ้ามันมา DB เยอะ อาจจะต้องปรับ Scale DB หรือ ปรับ Architecture
- Distributed Tracing - เห็นว่าผ่าน Service / API / Method * > Network Card
- Profiling จาก system call บางภาษาเห็นระดับ Method Call
- Auto Tagging ยัด Label ได้
📌Demo
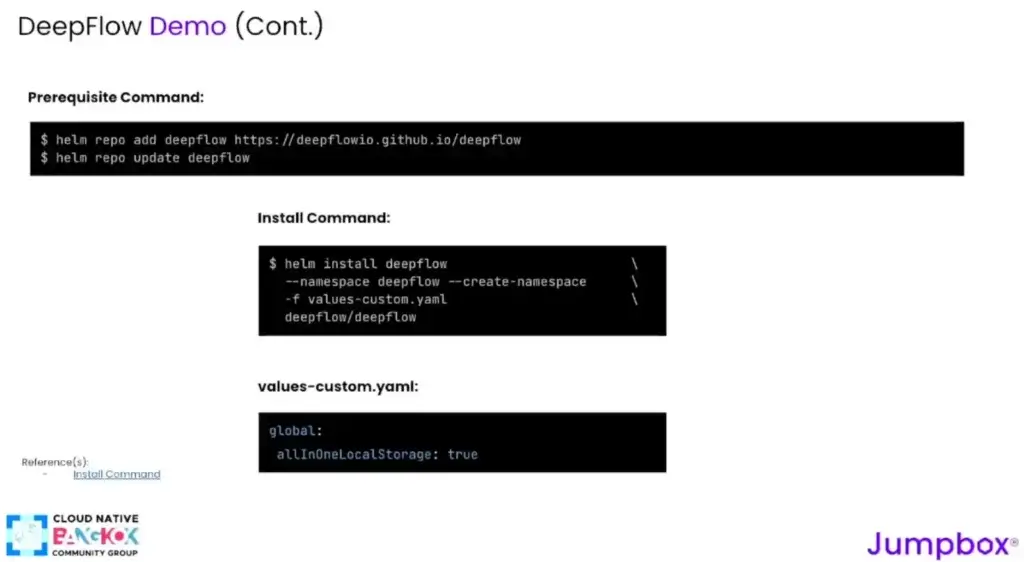
- Install from helm - allInOneLocalStorage ลอง mac windows ได้ / ถ้าจะเล่น CPU 4 Ram 8
- Edition DeepFlow Community / Enterpise / Cloud
- Template Dashboard - Default มันจะได้ RED Method / Golden signals - latency, traffic, errors, and saturation
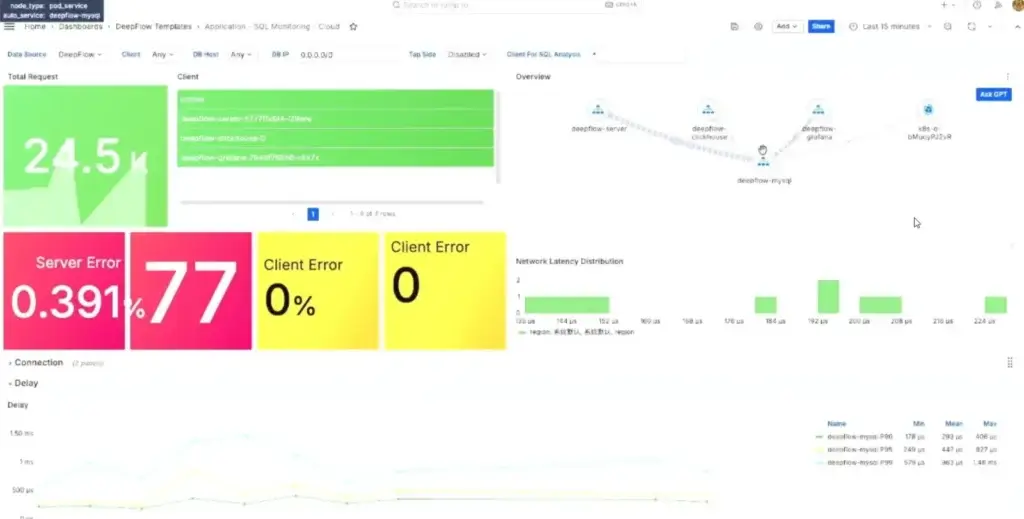
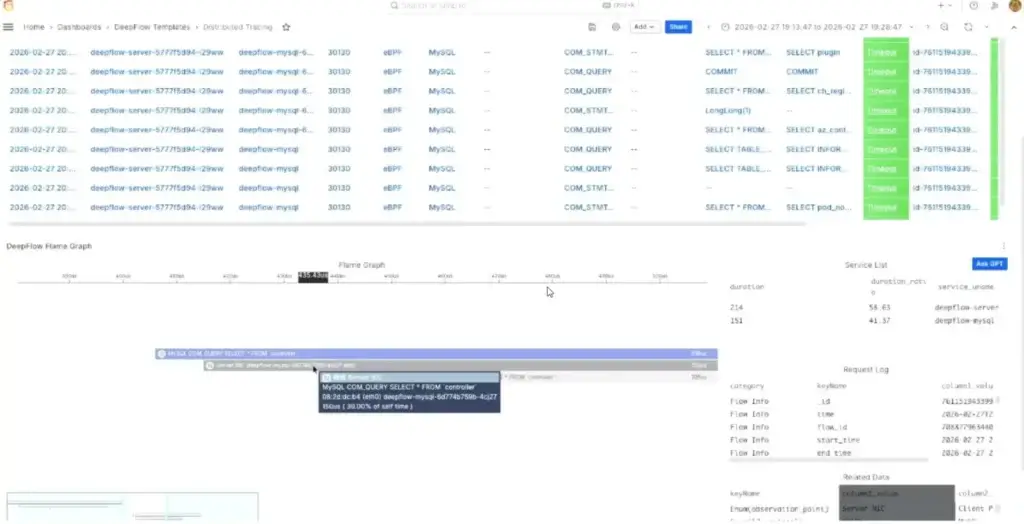
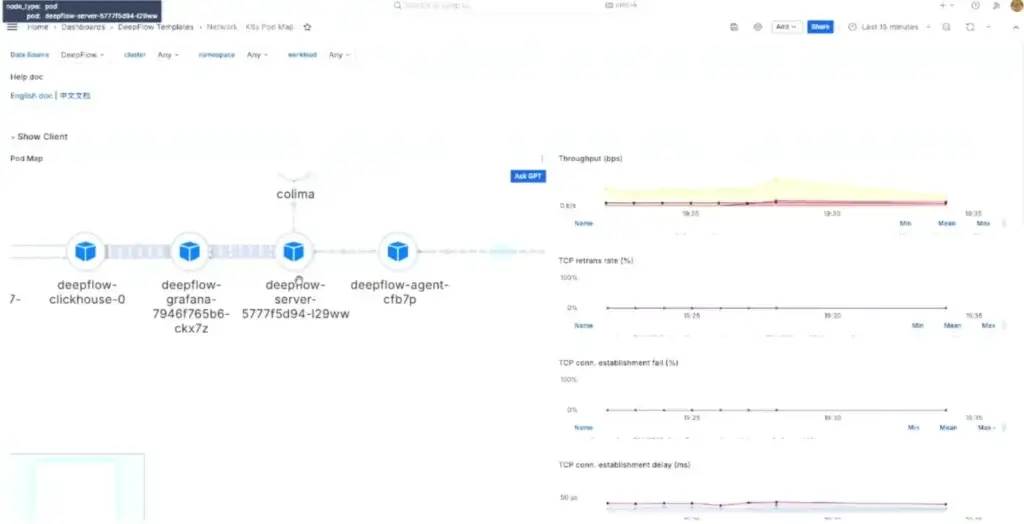
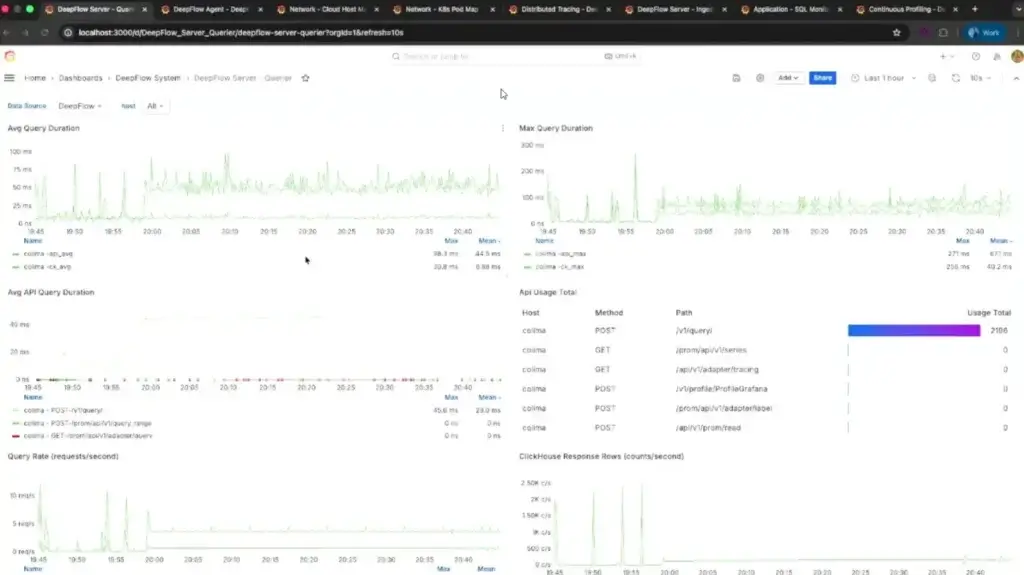
📌 นอกจากนี้ LGTM มีพวก eBPF Grafana Alloy (Bella) / Profilling - Grafana Pyroscope
สิ่งที่เราต้องเข้าใจ ก่อนจะเริ่ม Custom ของตัวเองลองดูก่อนว่ามีคนเจอ Pain แบบเดียวกันเราไหม ถ้ามีเอา Tech + Solution หยิบมาใช้ และ Improve กลับให้กับชุมชน Open Source ได้นะ
Back to Fundamental เข้าใจก่อนเลือกใช้นะ
Panel Discussion
Speaker Jirayut Nimsang / Saritrat Jirakulphondchai / Jaruwat Panturat / V-ris Jaijongrak
-AIOps — ขายฝัน หรือทำได้จริง?
📌 AIOps คือ อะไร ? - เอา AI เช้ามาช่วยงาน IT Operation อาทิ เช่น เจอ Case AI ควร Fix แล้วเตรียมข้อมูลสรูปมาให้ Human Act รอบสุดท้าย Approve ส่วน เอา Log / ภาพ Case โยนเข้า AI ถามตอบมองว่าใช้ แต่ยังไม่ AIOps 100%
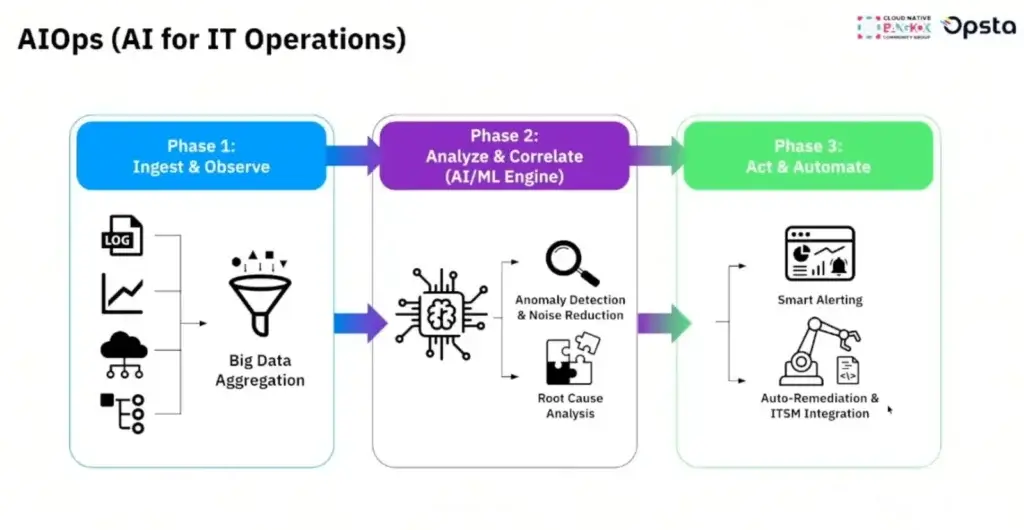
📌 Use Case ไหน ลองเอา AIOps มาใช้แล้วบ้าง - ให้ AI ทำระดับไหน ภาพยังประมาณนี้นะ
- Collect (AI / Human)
- Analyse (AI)
- Act (Human in Loop)
- เพราะ ถ้าพลาดความน่าเชื่อถือของ Brand ลดลงทันที - ตัว AI มันตอบแต่ละรอบไม่เหมือนกัน
- ใน Talk มีอีกมุมเล็กๆ ให้ AI จัดเลย ถ้ามี Pattern ที่ชัดเจน + เสี่ยงน้อย + เราเตรียม PlayBook ให้มันแล้ว อาจจะเป็น Get Infomation หรือสร้าง Resource (แต่เราทำ Policy คุมไว้ก่อน)
** เคส Restart ระวังนะ เพราะ Dependency อื่นอาจจะล่มไปด้วยแบบงงๆ กลายเป็นว่าสร้างวิกฤตแทน
📌ส่วน Agents as A judge (เอา LLM หลายตัวมาทำ Vote) เป็นอีก Idea นึง แต่ต้องระวัง Gen AI ยังต้องรอเวลาอีกสักพัก
📌นอกจากนี้มีส่วนของ Guard Rail มุมของ Operation ที่ต้องมาใส่ AIOps ด้วย เช่น command ให้มามันใช้ได้จริงไหม หรือ ไม่แหก Policy ที่เรากำหนด / สามารถ Trace ได้ ไม่มีพวก Prompt Injection เป็นต้น ตอนนี้มุม Dev มีพวก SpecKit (Spec Driven) ที่เอามาคุม Vibe Code แล้ว Apply ต้องรออีกสักพักให้ Idea นี้ Apply ขา Ops ด้วย
📌การจะให้คน Junior หรือ AI ทำอะไร สิ่งที่เราต้องมี Step ที่ชัดเจน สำหรับไปข้างหน้า และ Roll Back Plan กรณีที่เกิดข้อผิดพลาดด้วย ทำให้ Trace ได้ และมันจะตอบอีกประเด็น Junior หรือ AI ทำแล้วหลุด Prod พัง หรือ Cost สูง มันต้องย้อนมา Process ขององค์กรไม่ได้กัน ?
-Open Source vs. Commercial Monitoring Solutions
📌เรามีเวลากับมันแค่ไหน ทั้งเวลา คน การใช้ Open Source เพราะต้องกันคนมาดู และแก้ปัญหา หรือ Biz อยากจบไว้ไปทุ่มคนกัน Product ไปทาง Commercial ลดภาระทีมไป
📌Apply กับ Standard ที่ Biz นั้นมีได้ไหม พวก Commercial มันจะคิดมาให้แล้ว ถ้าใช้ Open Source ต้องมาเตรียมตอบคำถามด้วย
📌อีกมุมที่มอง Cost ที่ใช้ของ Open Source (คน + เวลา) / Commercial (จ่าย Fixed) - และต้องมาเทียบกับรายได้ขององค์กรด้วยนะ ว่าลงทุนไปคุ้มไหมฅ
📌รักษา Branding กรณีเคสไฟไหม้ ถ้า Open Source เราอาจจะตอบไม่ได้ ต้องมีจ้าง Expert Open Source หรือ Commercial Tools มาแก้ให้จบ ดับไฟก่อน
📒OpenTelemetry มันช่วยเรื่อง Vendor Lock จริงๆไหม ?
📌OpenTelemetry ช่วยเรื่อง Data ให้มี Standard สลับ Vendor ได้สลับ Endpoint หรือลองอะไรใหม่ๆ ได้ง่ายมากขึ้น
📌แต่ยังคิด Vendor Lock มึของ Dashboard ภาษาที่ใช้ในการ Query
นอกจากนี้ OpenTelemetry ยังสามารถ Apply กับมุมของคำถาม Business ว่า User ต้องเข้าเท่าไหร่ / Leave เท่าไหร่ หรือ จะมีโจทย์ต้องคุมทุนจะไปทาง FinOps
Reference
- https://community.cncf.io/events/details/cncf-cloud-native-bangkok-presents-observability-day/
- Live: https://www.facebook.com/cloud.native.bangkok/videos/1993756295352964
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


