
อันนี้เป็น Class เสริมต่อจาก Essential Statistics: Descriptive Statistics - สำหรับวันนี้ Confident Interval (ช่วงความเชื่อมั่น)
ทำไมต้องมี Confident Interval (ช่วงความเชื่อมั่น)
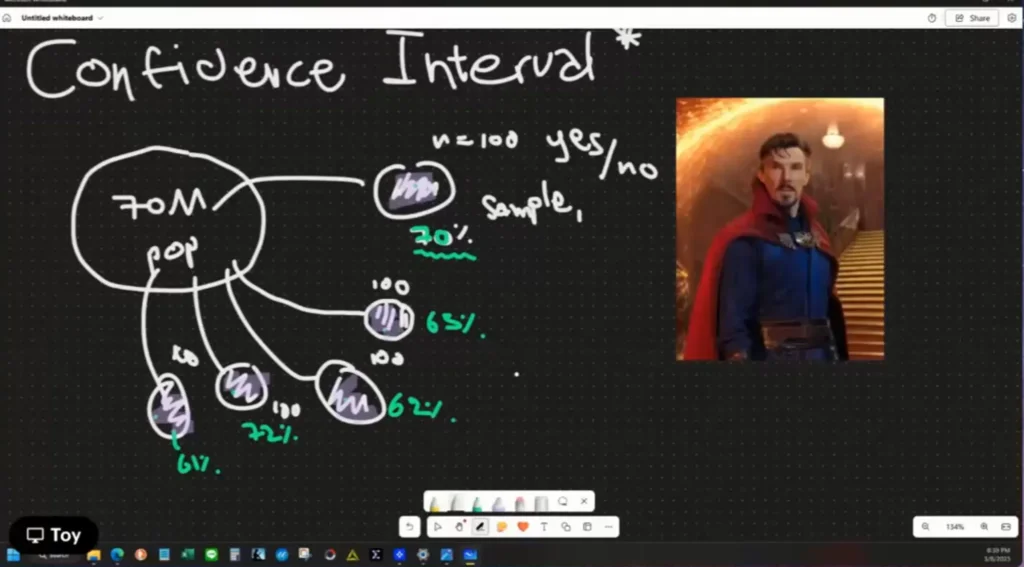
❓แอดทอยได้ยกตัวอย่างลอง ถ้าเราได้ลองทำแบบสำรวจ รอบแรกได้ผลเฉลี่ย 70 แล้วลองทำซ้ำ 4-5 รอบ คำถามผลที่ได้ไม่มีทาง 70 เสมอ หรือ ป่าว ?
คำตอบ ไม่ แต่มีโอกาศไปทางเดียวกัน
❓แล้วเราสุ่ม 5 รอบ ผลที่ได้จะตอบแทน population ได้ไหม ?
คำตอบ ได้ แต่ต้องสำรวจไปตามแนวทางของกฏ Central Limit Theorem
กฏ Central Limit Theorem (CLT)
- ที่ครั้งที่เราสุ่มตัวอย่าง (n) อย่างน้อย 30 คนขึ้นไป ส่วนทำไมต้อง 30 นั้นยังไม่มีที่มาแน่นอนนะ
- Random Sampling
- จากข้อ 1 n ≤ 90% ของ population //จริง ถ้า n เยอะ Cost จะเยอะตาม ปกติข้อนี้ไม่ได้เอามานับเท่าไหร่ เน้น 1 กับ 2
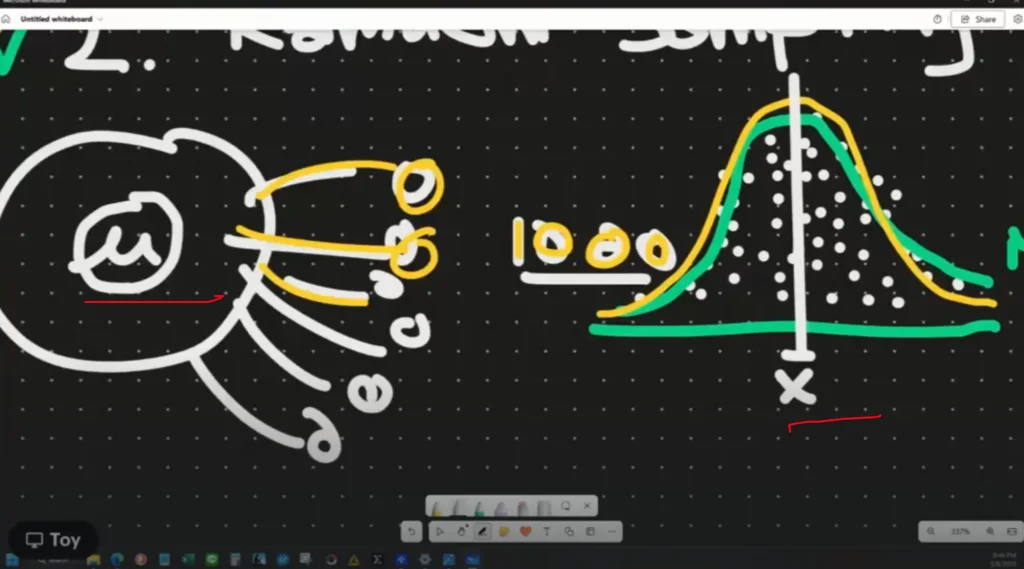
ถ้าสุ่มตามกฏ แล้วเราเอาตัวเลขมา Plot Graph ผลที่ได้จะเป็น Normal Distribution หรืออีกชื่อ Sampling Distribution ยิ่งถ้าสำรวจเยอะ Graph จะใกล้ Normal Distribution มากขึ้นด้วย
Mean จากทุกรอบ ตอบในส่วนของมิวได้ไหม ?
| สัญลักษณ์ | การอ่าน | นิยาม |
|---|---|---|
| μ | มิว | ค่าเฉลี่ย ของ population |
| σ | Sigma | SD ของ population |
ปกติแล้วค่าที่เราไม่รู้ จะเรียกว่า Unknown Parameter (ศัพท์ใหม่) แล้วค่ามิว ค่าเฉลี่ย ของ population เป็น Unknown Parameter เพราะเราวัดเองไม่ได้หมด
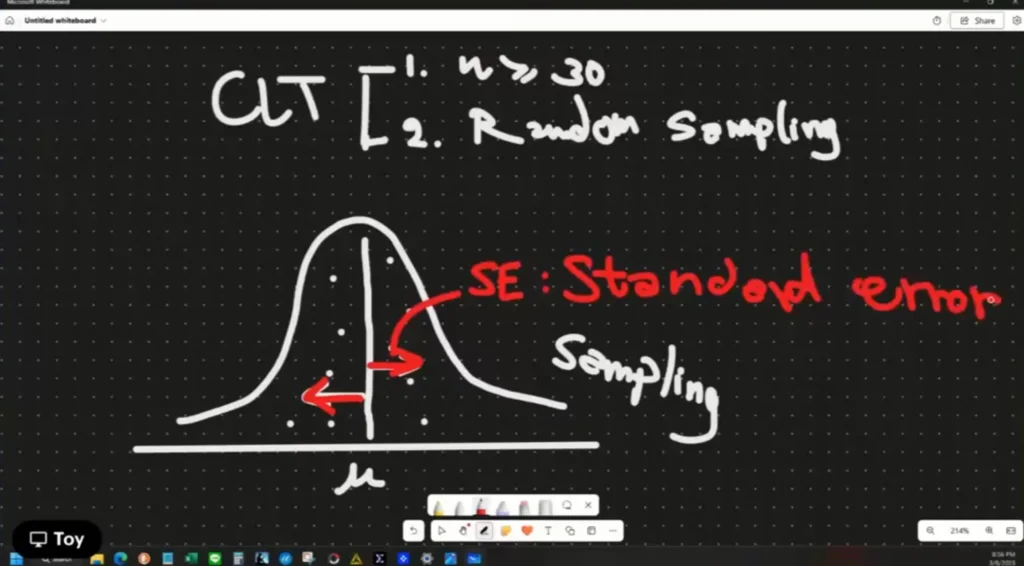
Standard Error (SE) คือ อิหยัง ?
Standard Error ตัว SD บน Sampling Distribution สรุปง่ายๆ
- Standard Deviation (SD) - ภายใน DataSet ที่ Sampling มา
- Standard Error (SE) - จากหลายๆ DataSet ที่ Sampling มาหลายๆรอบ
แล้วที่นี้เรารู้แล้วว่า Normal Distribution Empirical Rule +-3 sd 97.9% / +-2 sd 95% / +-1 sd 68.2%
เราจะได้ Idea ของ Confident Interval (ช่วงความเชื่อมั่น) ถ้าเลือกที่ 95% +-2 SD
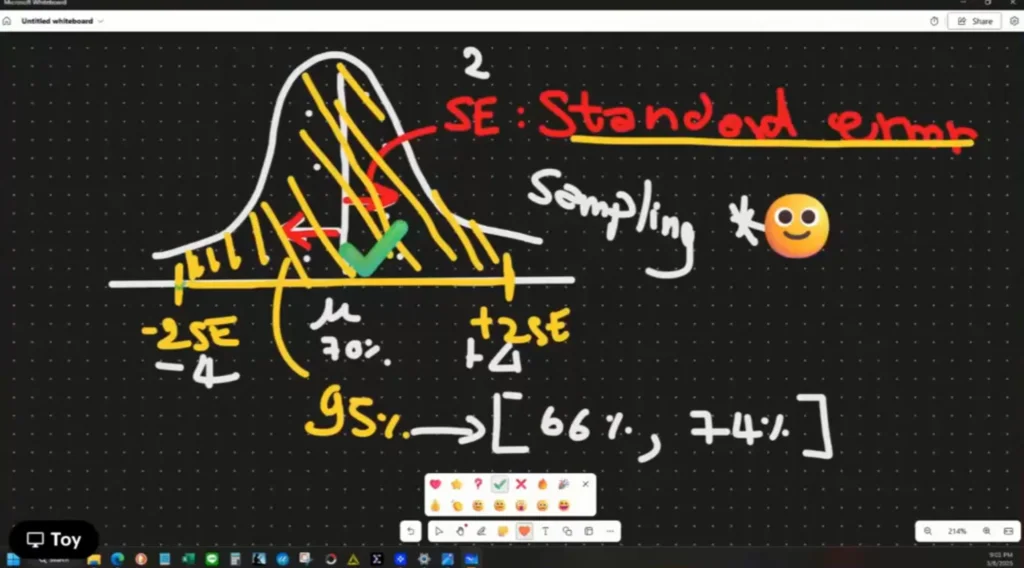
Confident Interval = mean +-2SD
เคสนี้ mean = 70 sd = 2 [66% , 74%]
ฟังอีกรอบเข้าใจ Idea และ รอบแรกที่ฟัง live สมองผม overflow และเบลอๆ เหมือนตื่นอีกทีตอนท้าย 5555

Confident Interval (ช่วงความเชื่อมั่น) มันคิดยังไง ?
💡 ในชีวิตจริง เราไม่สุ่ม 1000 ครั้งเปลือง ทำ 1 ครี่งแต่ทำตาม CLT พอทำครั้งเดียวแสดงว่า SE (พื้นที่เขียวๆ) เราต้องไปสร้างขึ้นมา ไปหาสูตรใส่มา จนได้ Confident Interval
ตรงนี้แอดทอยจะสอน 2 แบบ อาจจะมีมากกนี่ แต่หัวบวมแล้ว 55
- Confidence interval for a mean
- Confidence interval for a proportion
- Confidence interval for a mean
การคำนวณเพื่อหา Confident Interval จากการทำ Sampling รอบเดียว
ใช้เมื่อ ข้อมูล Likert Scale [พวก 0-10 ไม่เห็นด้วย …. เห็นด้วย]
Step ตามนี้
- หา Standard Error (SE) สูตร
sd/SQRT(n) - หา margin error default 95% (+-2SD) โดยมีสูตร
T * SE
T = ค่าต้องไปดูตาราง T หาค่าจาก
-> degree if freedom (df) = n-1
-> sigificate level ถ้าเราต้องการที่ 95% ให้ดูที่ 0.05 ได้ประมาณ 2.045 (แบบ 2 tail)
- เอา mean มา +- กับ margin error จะได้ Confident Interval
💡 Confident Interval ม้่นใจว่า 95% ของ P สนใจ XXX ในช่วง [mean - margin error, mean + margin error]
คำนวณมือ
Sample Mock Data with Question Do you like Mickey 17 (n=30) n = 30 mean = 7 sd = 1 se = sd/SQRT(n) = 0.182574 me = T * se *T = ค่าต้องไปดูตาราง T หาค่าจาก -> degree if freedom (df) = n-1 -> sigificate level ถ้าเราต้องการที่ 95% ให้ดูที่ 0.5 เคสนี้ df 29 / sig = 0.5 ได้ค่า me = 2.045 * 0.182574 me = 0.373 Confident Interval ที่ 95% = mean +- margin error จะได้เป็น 7+0.373 / 7-0.373 [6.627, 7.373]
แต่ใน Excel มีสูตรให้เลยนะ CONFIDENCE.T
สตร Excel หา Margin Error =CONFIDENCE.T(AlPHA,sd,N) //AlPHA ใส่ 0.05 เพราะ Confident Interval ที่ 95% =CONFIDENCE.T(0.05,1,30) จากนั้นเอาค่าที่ได้ไปหา Confident Interval ที่ 95% = mean +- margin error
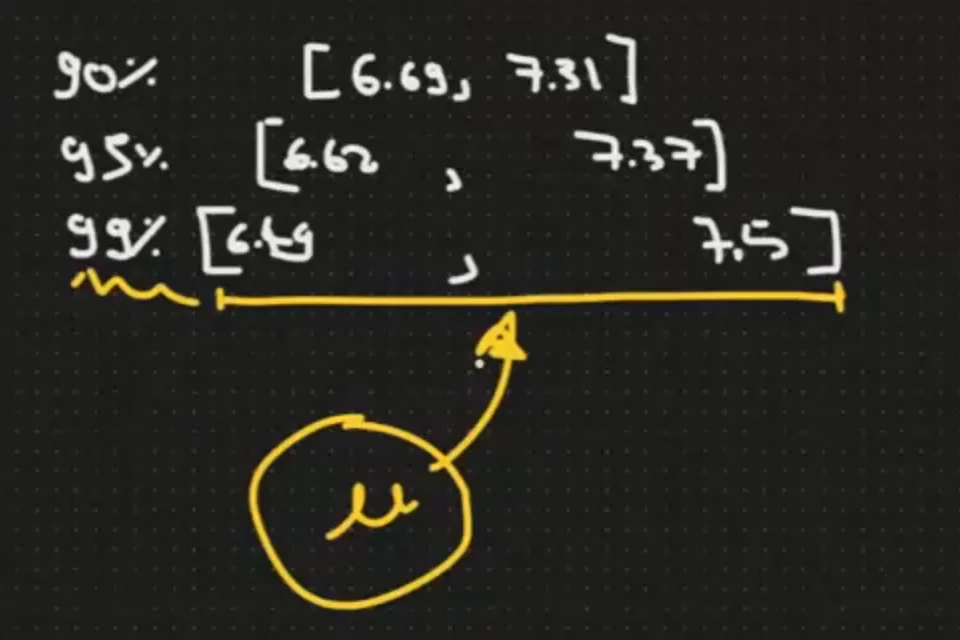
ยิ่งช่วงที่กว้างขึ้นมีโอกาศ เก็บค่าที่แท้จริงใน p ได้มากขึ้น
- เพิ่ม Confident (Alpha) > CI จะกว้างขึ้น
- ลด Confident (Alpha) < CI จะแคบลง
95% หรือ Alpha 0.05 มาเป็นค่า Default
ถ้าไม่อยากแก้ Confident (Alpha) ให้เพิ่ม n เอา เพราะ SE = sd/SQRT(n) ถ้า n มาขึ้นช่วงความเชื่อมั่นจะแคบลง แต่ต้องดูด้วยว่า n ไหนที่คุ้มค่า
- Confidence interval for a proportion
ใช้เมื่อ ข้อมูลแบบ Proportion แบบ Yes/No Question ค่า 0/1
Step ตามนี้
- หา Standard Error (SE) มีสูตร
SQRT( p * (1-p) )
ค่า p (%prop) มาจาก ค่าเลือกตามคำถาม เช่น ชอบ เอามาตั้ง และส่วนด้วย n
- หา margin error= Z x SE โดยค่า Z ดูจากตาราง Z ค่า Z ประมาณ
- 90% = 1.65
- 95% = 1.96
- 99% = 2.58 - ค่า p (%prop) +- margin error (ME)
สูตร Excel มีนะ CONFIDENCE.NORM
ตัวอย่าง Google SpreadSheet
10 Idea ที่ได้
- พยายามสำรวจให้เค้ากฏ Central Limit Theorem เพื่อที่จะ Apply กฏที่เหลือได้
- Confidence interval มีมาเพื่อบอกความผิดพลาดของการสำรวจ จากเจ้าค่า margin error ปกติ Default ที่ 95%
- ปกติตัว Confidence interval เค้าจะคงไว้ที่ 95% ถ้าอยากให้ช่วงมันแคบลง ไปเพิ่ม n ที่จะสอบถามเอา แต่จะใช้ Cost เยอะขึ้นมาด้วย
- Unknown Parameter - ค่าที่เราไม่รู้ เช่น mean ของ Population
- Parameter - ค่าที่เราเอามาจาก Sample อธิบาย Population ทั้งหมด ตัวอย่าง parameter mean / median / mode / varience / sd ตอนแรกอ่านจาก w3c แล้วไม่เข้าหัวเลย มาเอีะในข้อก่อนหน้า Unknown Parameter
- สัญลักษณ์มีเยอะแล้วงง แปะของ w3c ไว้ก่อน

- Standard Deviation (SD) - ภายใน DataSet ที่ Sampling มา
- Standard Error (SE) - จากหลายๆ DataSet ที่ Sampling มาหลายๆรอบ
- Confidence interval ที่สอน 2 แบบนะ mean / proportion
- สูตร Standard Error (SE) mean / proportion


- Confidence interval mean - ข้อมูล Likert Scale
- Likert Scale ลองไปหาเพิ่มมาเป็นการวัดทัศนคติ ความคิดเห็น หรือความรู้สึก โดยมีลำดับชั้นเจน (Ordinal Scale) เช่น จากน้อยไปมาก
- Confidence interval proportion ข้อมูล Yes / No
- สูตรของ Confidence interval CONFIDENCE.T / CONFIDENCE.NORM ใน Excel กับ Google Sheet มีเหมือนกันนะ ลองแล้ว
- เรียนไม่ทันแล้วววววววววววววววววววววววววว
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


