
Blog นี้มาจดสรุปที่เรียนมาของแอดทอยอีก เช่น เคยครับ โดยมีหัวข้อตามนี้
Why Stats
Stats วิชาที่มีมานานหลายร้อยปี โดยต้องรู้
- population ประชากรทั้งหมด มันมีเยอะมาก
- sample คนที่เป็นตัวแทนจาก population โดยต้องมีหลักการเลือกให้เป็นตัวแทนของ population ทั้งหมดที่เรียกว่า sampling โดยถ้าทำได้ เราสามารถขยายผล generalize กลับไปตอบแนวคิดของ population ได้
💡Stats - The way we try to understand the world
Stats ศาสตร์การหา small data เพื่อมาตอบปัญหาที่ใช้กับ population ทั้งหมดได้ (Big Data)
ที่ฟังมาผมชอบอีกตัวอย่าง Stats การทำอาหาร แล้วเราช้อนไปคน และตักชึ้นมาชิม (Sample) > ตอบว่าทั้งหม้อ OK เหมือนกัน
นอกจากนี้ลองนึกการซื้อหุ้น เราไม่รู้ข้อมูลทั้งหมดเหมือนกัน ต้อง Sampling งบ เข้าไปดูธุรกิจบางส่วน ใช้ Product / Service มันเป็นไม่ได้ใช้ทั้งหมดนะและเรื่องการหาแฟนก็เข่นกัน เจ็บ โสดดอยู่ 555
💡Stats - The way to make better decisions
จาก sample เรารู้ะไรบ้าง mean / sd / min max range / normalize เป็น scale
population > -sampling- > sample
จาก population จนได้ sample มีหลักการเลือก 2 กลุ่มใหญ่ๆ
- Probability Sampling - ได้กลุ่มตัวอย่างที่มี Quality
- Non Probability Sampling - เป็นวิธีสุดท้ายที่เหลือ มันตามใจมาก
- Probability Sampling
📌Simple Random Sampling - ทุกคนมีโอกาศจะโดนสุ่มเท่ากัน ถ้ามีลูกบอลเลข 1 - 10 มีโอกาศ 10% ที่ดึงออกมานั่นเอง
📌Systematic Random Sampling - มี Rule กำหนดชัดเจน เช่น เลือกคนแรก แล้วเว้นไป 2 เลือกคนถัดไป หรือ เอาจากอายุ
📌Cluster Random Sampling - แบ่งกลุ่ม แล้วเอากลุ่มนั้นมาเป็น Sample เลย
📌Stratified Random Sampling - แนวทางแบ่งกลุ่ม แล้วเอากำหนดสัดส่วน และสุ่มจากลุ่มนั้น เอามา Sample ยกตัวอย่างในไทย
- อาจจะแบ่งเป็นพื้นที่ 5 ส่วน กทม ปริมณฑล / ภาคเหนือ / ใต้ / อีสาน / ตก
- กำหนดสัดส่วนที่สุ่มของแต่ละพื้นที่ เช่น กทม ปริมณฑล 10% / อีสาน 32%
- จากนั้นสุ่มขึ้นมา อาจจะเอาแนวคิด Simple Random Sampling มากำหนดพื้นที่ แบ่งเท่ากันตามตำบล อำเภอ ใช้คอมมาจัดการลด Bias และอาจจะมี Fact พิเศษของลูกค้า เป้าหมาย มา override ได้นะ
- LEFT HAND RULE ใช้ตอนลงสัมภาษณ์จริง จะเลี้ยวซ้ายวนถามในแค่ละพื้นที่ อาจจะเดิน 5 หลังเว้น ใช้หลักการ Systematic Random Sampling
เจ้า Stratified Random Sampling ผสมหลายหลักเหมือนกันนะ ( บ Market Research ชอบใช้กัน) ทำแบบขนาดใหญ่
- ปกติเวลาอยากได้ Sample n จะติดเรื่อง Time / Budget
- cpi (cost per interview) ค่าใช้จ่ายต่อหัว Sample
- สำมะโนประชากร (census) update ทุกๆ 10-15 ปี ของไทยจัดทำโดยสำนักงานสถิติแห่งชาติ แต่ไม่ได้ถามทุกคนนะ สุ่มครอบครัว ถ้าของเอกชน ม มหิดล มีทำนะ
- เอาเจ้า Stratified Random Sampling มาเพือช่วยให้ได้ sample ที่ครอบคลุม
- Non Probability Sampling
📌 Convenience Random Sampling ตามสะดวก เราสร้าง Google Form เอาไปแปะใน Line / Social ตัว sample จะแบบตามสะดวกเหมือนกัน เพราะ มันจะตามเพื่อนเรา หรือ คนที่ผ่านมาช่วยกด แต่วิธีการนี้ไม่เหมาะกับการใช้งานจริง แต่ช่วยลด Cost / Time ได้เยอะ
📌 Snowball Random Sampling - ใช้กับ Domain ที่หา Sample ยากมากๆ เช่น ซื้องาช้าง หาคนแรกให้เจอก่อน แล้วขอ Contact จากคนแรก 2 3 4 ต่อไปเรื่อยๆ โยน Snowball ต่อไปเรื่อยๆ
💡ถ้ามี Data มากขึ้น เราจะตัดสินใจได้ดียิ่งขึ้น
- เลือกวิธีการไหน
📌ขึ้นกับ Time / Cost และจำนวน Sample ที่ต้องการหา
📌วิธีการที่เราเลือก Sampling ส่งผลกับความน่าเชื่อถือของ Research ด้วย (Garbage In > Garbage Out)
📌ลองดูตัวอย่างการหาจำนวน Sample ของ surveymonkey.com
- Confident Level เราเชื่อมั่นค่าค่าที่เราวัดจะครอบคลุม 95% วันไป 100 รอบ จะมีหลุดโลกไป 5 รอบ > ยิ่ง n (Sample) เพิ่มขึ้นความมันใจจะเพิ่มขึ้น
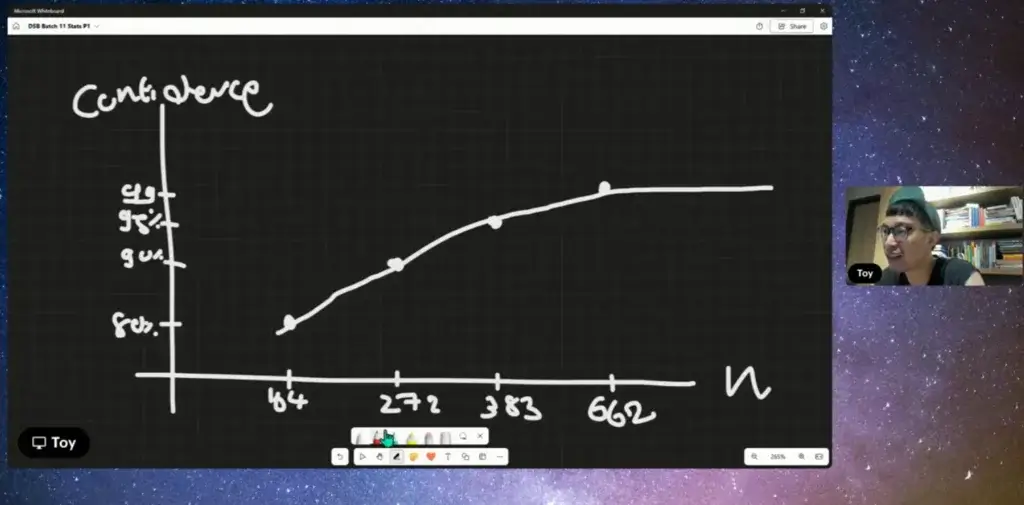
- Margin of Error (%)
❓ ยิ่งต่ำยิ่งดี เพราะมันจะลดการแกว่งของผลลัพธ์ได้ ค่านี้ ถ้าคนเห็นด้วย 70% Margin of Error 10% จะมีช่วงที่แกว่ง 60% / 80%
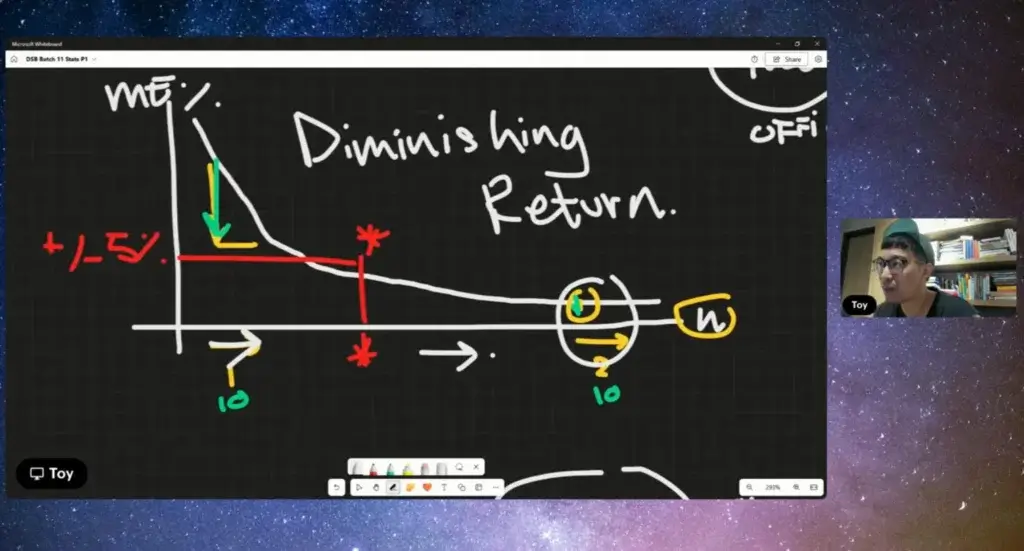
❓ แต่ความสัมพันธ์ของ Sample กับ Margin of Error (%)
❓ มันจะมีค่าที่คุ้ม และไม่คุ้ม (diminishing return) ยิ่งกด Margin of Error (%) กลายเป็นว่า Sample เยอะขึ้น มันกระทบ Time / Cost
❓ เอาง่าย ปกติ +-5% (Arbitrary นะ ไม่ได้มีกฏตายตัว)
Essential Stats
ปกติแล้วสถิต มันมี 2 แบบนะ
- Descriptive statistics - บรรยายสรุปข้อมูลจากจากข้อมูลที่ได้มา ตามเครื่องมือต่างๆ
- Inferential statistics - หาข้อสรุป
Descriptive statistics
- Central tendency - วัดค่ากลาง
📌mean - sum() / จำนวนข้อมูล
📌median แบ่งข้อมูล หาตัวตรงกลางเฉลี่ย ถ้าข้อมูลจำนวนเป็นเลขคู่ เอาค่าเอาตรงกลาง 2 ตัว บวกกัน/2
📌mode ข้อมูลที่เกิดซ้ำมากที่สุด มีความถี่ Frequency สูงสุด mode มีได้หลายแบบ
- unimodal - มี mode เดียว
- bimodal - 2 mode
- multi model - หลาย mode
mode ใช้กับ Data ที่ไม่ใช่กับตัวเลขได้ด้วย
ที่ชอบตัวอย่าง มันเอามาคิดแบบนี้จริงๆ ตอนแรกเอามา Adapt ตรวจ Log เค้ามีเอามาวัดช่วยเวลาที่คนเข้าห้างด้วย
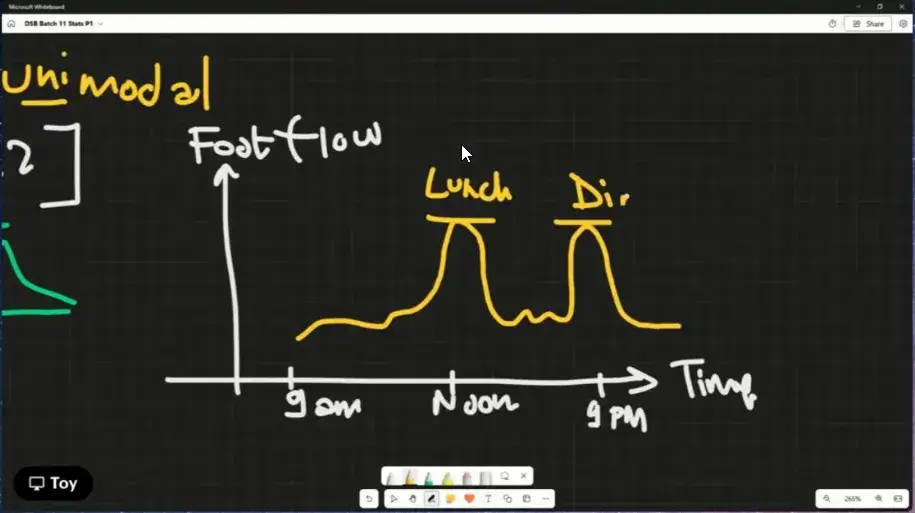
นอกจากดูตัวเลขแล้ว เรายังสามารถใช้กราฟ plot mean / median / mode
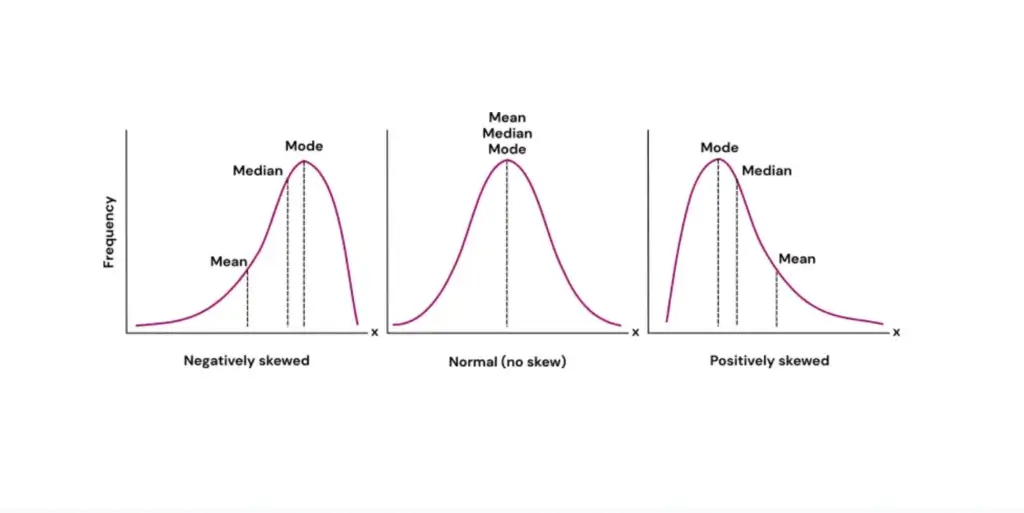
Negatively เบ้ซ้าย / Positively เบ้ขวา
- ถ้าข้อมูล Normal Distribution จะตามภาพกลาง
- ถ้าไม่เข้า แสดงว่าเกิดการเบ้ (Skew) จะเป็นภาพเบ้ซ้าย / เบ้ขวา ตามลำดับ ถ้าเบ้ค่ากลางใช้ median นะ เพราะเป็น robust statistic ค่าสถิติที่ทนกับ Outlier อย่าง เช่น เคส Income Distribution ในไทย มันจะไปทางเบ้ซ้าย
- Measure of Spread
วัดการกระจายตัว Variability / Variable ตัวอย่างเครื่องมือ SD/ variance / range / IQR
📌 Range = Max - Min Range ยิ่งค่าสูง แปลว่าข้อมูลกระจายตัวเยอะ
📌 Variance - ความแปรปรวน จริงๆ นิยามว่า มันห่าง mean เท่าไหร่ น่าจะดี
Step 1: Find mean Step 2: sum distance to mean sum((x-mean)^2) / n-1 ** n = sample size ต้องยกกำลัง 2 ถ้าไม่ยก มันจะหักล้างเหลือ 0 Excel VAR.S / VAR.P (S = sample / P = population
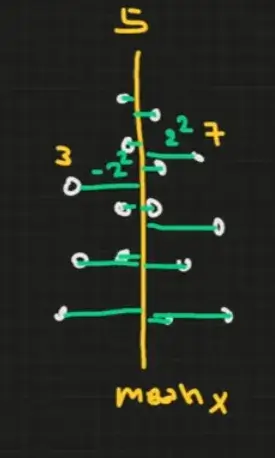
Step 1: Find mean Step 2: sum distance to mean sum((x-mean)^2) / n-1 * n = sample size * ต้องยกกำลัง 2 ถ้าไม่ยก มันจะหักล้างเหลือ 0 Excel VAR.S / VAR.P (S = sample / P = population)
สูตรของ VAR.S / VAR.P ต่างกันที่ตัวหาร
- VAR.S - หารด้วย n-1
- VAR.P - หารด้วย n
ดังนั้น VAR S > VAR P เสมอนะ ที่สูตรจงใจ เพราะมันเป็น Sample นะ มันมีโอกาสคลาดเคลื่อน
📌 Standard Deviation - สรุปการกระจายของข้อมูล
- มีหน่วยเดียวกันข้อมูลดิบนะ เพราะ VAR ไป ยกกำลัง 2
- SD เลยต้อง sqrt(VAR)
- ถ้าข้อมูลกระจาย Normal เราเอา Empirical Rule of Normal Distribution มาหาช่วงข้อมูลจาก SD ได้
+/- 1 SD+/- 2 SD+/- 3 SD
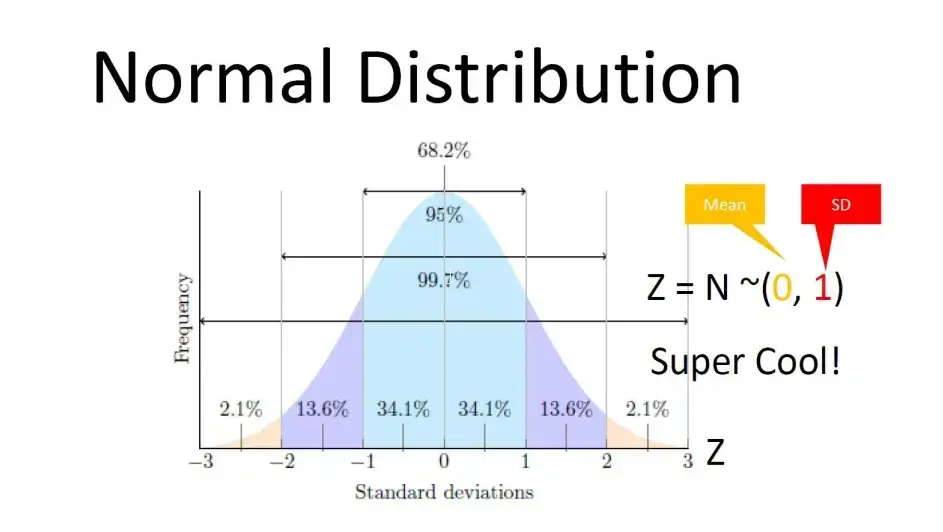
📌 Z Score
- เอา Standard Deviation มาทำ Standardization ทำให้ข้อมูลดิบ (Raw) เป็น Standardization มากขึ้น
- ทำให้ดูได้ง่ายขึ้น ว่ามันเกิน หรือ ต่ำกว่า mean
(x - mean) / sd = Z ค่า Z ลบ คือน้อยกว่า mean , บวก คือ มากกว่า mean มีน่าถึงเรียกว่าตัดเกรด Z Score ไม่ได้ทำให้ Distribution เปลีี่ยนไปนะ ถ้าแปลง Z กลับไปเป็นข้อมูลดิบ raw = (Z * sd) + mean
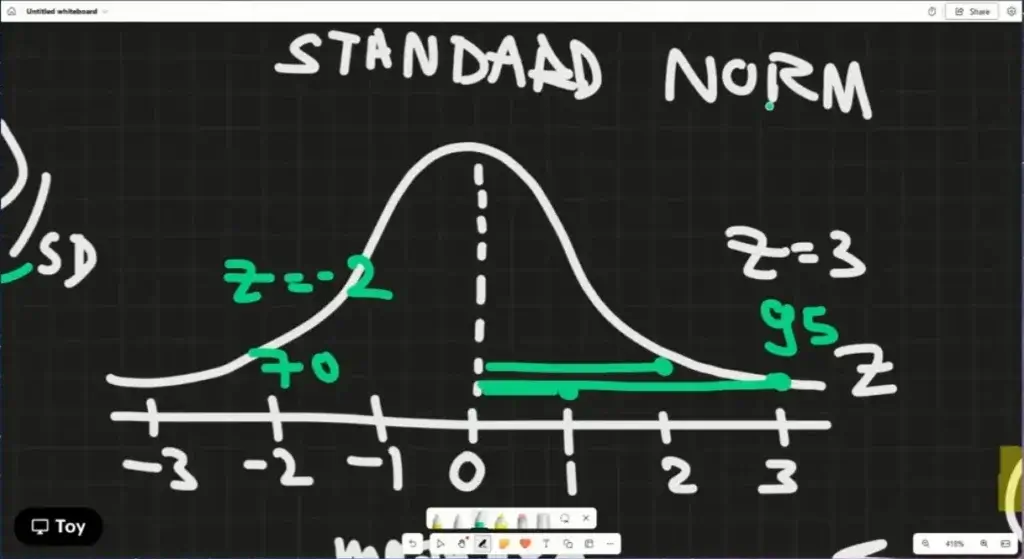
นอกจากนี้ Z Score เอามาตัดเกรดได้ โดยสิ่งที่ต้องทำ
- รู้ค่า Z
- เอาค่า Z ไปหาตาราง Z Score รู้พื้นที่ใต้กราฟ ลองหาดูมี Blog ที่น่าสนใจด้วย dsinการหาค่า Z และ prob. โดยใช้ excel
📌IQR (Interquartile range)
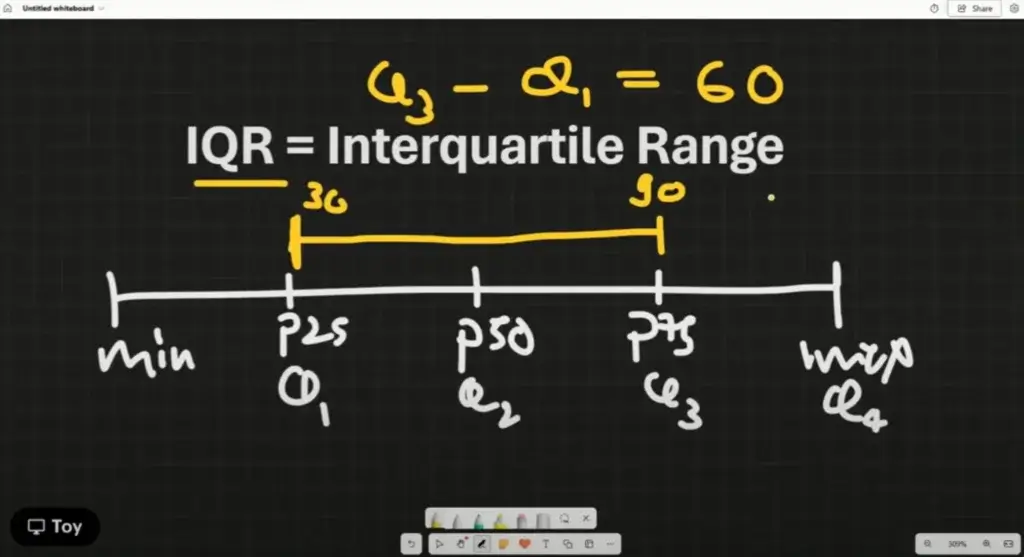
- เราต้องเข้าใน Quartile ก่อน มันมาจาก Q3 - Q1
- ถ้าอยากรู้ว่าเยอะน้อยช่วง IQR ต้องมีข้อมูลอีกชุดมาเทียบ
- IQR ใช้ตัด outlier 1.5 เท่า เพราะ it most closely follows Gaussian distribution
- Measure of Position การวัดตำแหน่ง
Key ต้อง Sort Data ก่อนนะ
- Sort แล้วเราได้ min / max
- เริ่มจาก median อยู่ในหัวข้อนี้ด้วยนะ มันแบ่งข้อมูล 50% มันเป็น robust statistic แบ่งครึ่ง ได้ Percentile 50 (P50) และอีกตัวที่เรียน IQR เหมือนลองไปหาเพิ่มดูจะมี Trimmean / Winsorizing ที่เป็น robust statistic ด้วย
- แล้วที่เอา จะได้ 2 ช่วง แบ่งครึ่งอีก จะได้ Percentile 25 / 75
10 Idea ที่ได้จาก Class นี้
- เรียน Stat กับแอดทอย ง่ายจริงๆ ตอนแรกเราไม่รู้ว่าเอาไปทำอะไร ตอนเรียนโจทย์บอกหา SD แทนสูตรจบ แต่มันอธิบายไม่ได้ ว่าทำไม เพราะอะไร ก่อนมาเรียนหลงเหลือมาใช้ min max mean sum เท่านั้น
- เข้าใจว่าอะไรที่การเลือก Sample เจอหลายแบบ
📶 เคสที่เจอเยอะสุดแบบที่แชร์ Google Form นี่แหละ
📊 อีกแบบที่แชร์ในกลุ่ม FB ไปตอบ แล้วได้เงิน น่าจะเข้า Market Research ช่วงแรกๆทำงาน ไปตอบแบบนั้นบ่อย หาเงิน 55 แต่มีรอบนึงเจอเคสไปฟังขายตรงเลยเลิกไป
📚 และก็เรื่องการทำสำมะโนประชากร ตอนเรียนแม่ฟังด้วย สรุปเมื่อหลาย 10 ปีกว่าก่อน คนมาเคาะบ้านจริง เก็บข้อมูลประมาณ 10 นาที เป็นนิสิต นักศึกษาเข้ามาทำ ช่วงนั้นที่ผมเองยังเรียนอยู่เลยไม่ค่อยรู้เรื่อง ตอนนั้นแม่ผมอ่านหนังสือไม่ออก น้องที่มาเก็บจะอ่านให้ตอบไป แต่ถ้าคนที่พออ่านได้จะในทางเอาเอกสารหย่อนไว้ แล้ววนกลับมาเอาอีกที - การหาคำตอบที่ดี มันเริ่มต้นจากการหาคนถาม หรือ Sample ที่ดี
- ติดอะไรลอง ทำ Basic Stat ก่อน แล้วจะได้เห็นมุมมองใหม่ๆ
- Variance คือ จุดที่ต่างกับ mean ตอนแรก งงว่ามันคิดอะไร
- เห็น Use-Case Z Score เอามาตัดเกรด เข้าใจและว่ามันทำงานยังไง
- Stats - The way to turn samples > into a simple number by aggregation / summaries for tell characteristic of data
- Data Sci เป็นส่วนผสมที่่ลงตัวระหว่าง Stats / Coding / Domain Expertise
ส่วน Market Research มาจาก Stats / Domain Expertise - อย่าโดน ตัวเลขหลอก ได้ Basic Stat แล้ว ต้องเอามา Plot กราฟด้วย
- อาจจะไม่เกี่ยวกับ Class นี้โดยตรงนะ แต่ผมได้ Idea จาก Stats แบบ Basic + Data Viz เอาไปช่วยกับงานจริงๆได้ เจอปัญหาว่าตัวระบบมันช้า เลยเอาข้อมูล Log มาหา Diff Sort Max / Min / Count แล้วเอามา Plot กราฟตามเวลาหาจุดโดด แล้วช่วยลดงานทำจาก 16-17 ชั่วโมงจนเหลือ 95 นาทีได้
- เดี๋ยวต้องลองกลับไปเรียน Stats ของ w3c ต่อ ตอนแรกท้อมาก มันอะไรก็ไม่รู้ศัพท์ภาษาอังกฤษแปลกอย่าง parameter / variable เดี๋ยวต้องไปลองเรียนต่อครับ
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


