
สำหรับวันนี้งานจัดที่ SCBX NEXT TECH ที่ Siam Paragon ครับ โดยงานเป็น On-Site แรกของผมในปี 2025 ด้วยครับ โดยหัวข้อที่จดๆมาก็มี ดังนี้ครับ
แนะนำงาน FOSSASIA+
- งาน FOSSASIA+ เป็นงานคุยเรื่อง Open Source โดยมีหลาย Track อย่าง Software Design / Database / AI หริอ Cloud เป็นต้น
- ถ้าสนใจ สามารถสมัครได้ตาม QR Code ครับ ปีนี้มันจัดที่ True Digital Park

- อ่อ และถ้าเป็นนักศึกษาจะได้ส่วนลดด้วยน้า

Practical Unpractical in Open Source Software
Speaker: Kongkeit Khunpanitchote (Maintainer ElysiaJS)
หลาย App ที่เราใช้ๆกันอย่าง Discord / VS Code / Postman / Figma ทั้งหมดถูกเขียนด้วย Electron มันเป็น Web นี่แหละที่เอามารันบน Desktop มันเป็น webview
End User View ไม่ชอบ มันช้า และกิน RAM
📌Why Design
- Business View เน้นลด Time / Cost
- Developer View Reusable Resource Share
ไม่ว่าจะมุมไหนก็ตาม เราจะมองว่ามันวิธีการที่ดีนะ Practical แต่ทว่าวิธีการที่มองว่า Practical มันอาจจะใช้ไม่ได้กับทุก Case นะ อย่าง เช่น App ที่ใช้ HW สูงๆ อย่าง Blender / Adode Premire
📌ดังนั้น Practical Subjective แต่แบ่งได้ 2 มุม
- For Product เน้น Shipping Fast ให้ไว ไม่ได้สน Perf / Sec
- For Library พวกทำ Lib / ทำ Framework มันจะมองไปอีกมุม เน้นการแก้ปัญหาส่วน Technical Needs และพยายาม minimal footprint ไม่กระทบชาวบ้านเยอะ เวลา Release เลยช้าออกไป


📌แล้วอะไรคือ Technical Needs
Technical Needs - ส่วนที่มัน Common ไม่อยากทำซ้ำ อยากให้ Develop ซึ่งเป็น End User ใช้งานได้ง่ายสะดวก ต้อง minimal footprint
📌ลองมาดู Speaker เล่า Use Case และกัน
💡A Command palette for react - เน้นให้ Dev ใช้งานสะดวก แต่มันจะชอบแทรก inline css เข้ามาให้เรา มันดูยาก แต่ที่ Design แบบนี้อยากให้ minimal footprint ไม่ต้องไปลง Lib เพิ่ม
💡SVELTE เลือกที่จะสร้าง Compile เอง เพราะ อยากลด Overhead (พวก Package ที่ส่งไป Client) ทำให้เล็กและน้อยที่สุด
💡Ajv JSON Validator เป็น lib ที่มีมานานแล้ว การทำงานของมัน จะใช้ eval() เอา string ไปใส่ มัน Run ได้เลยแต่ ทำไม load เยอะ ภาพนี้น่าจะตอบได้เลย performance มันดีมาก
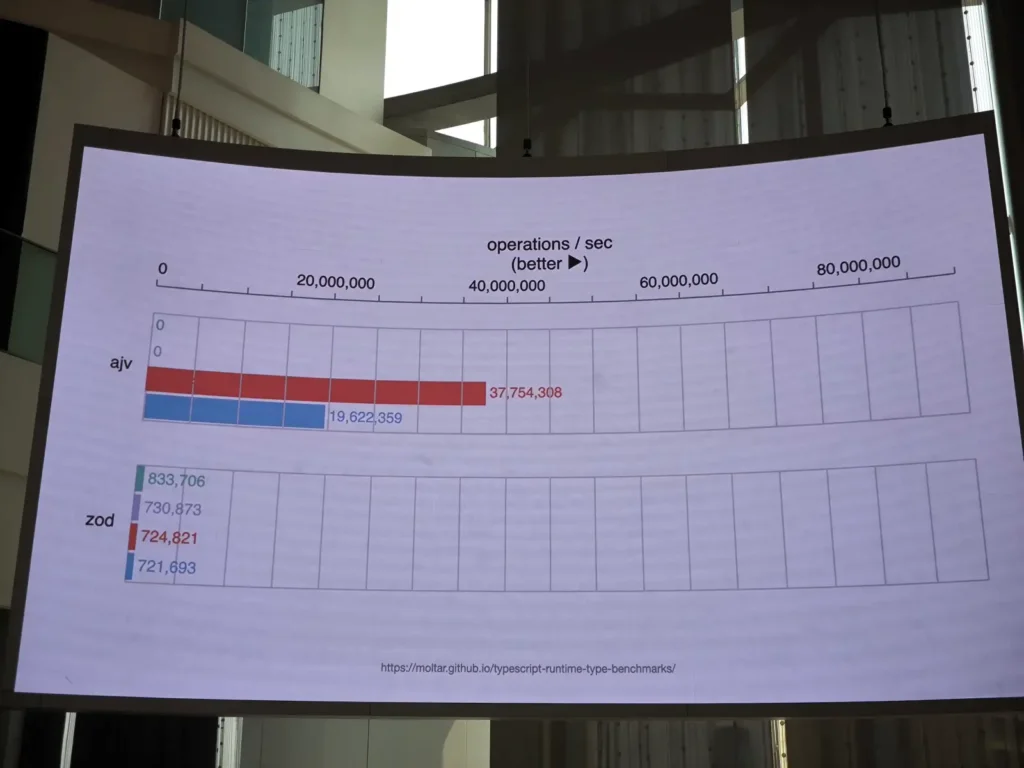
แต่ eval() มันไม่ดีกับ Security ทำไมถึงใช้กัน นี่เป็นอีกมุมเน้น Performance แต่ต้องแลกมาด้วยว่าต้องมาทำท่ายาก เขียน Code เพื่อตรวจทุก Case ให้มันครอบคลุม และง่ายกับ End User

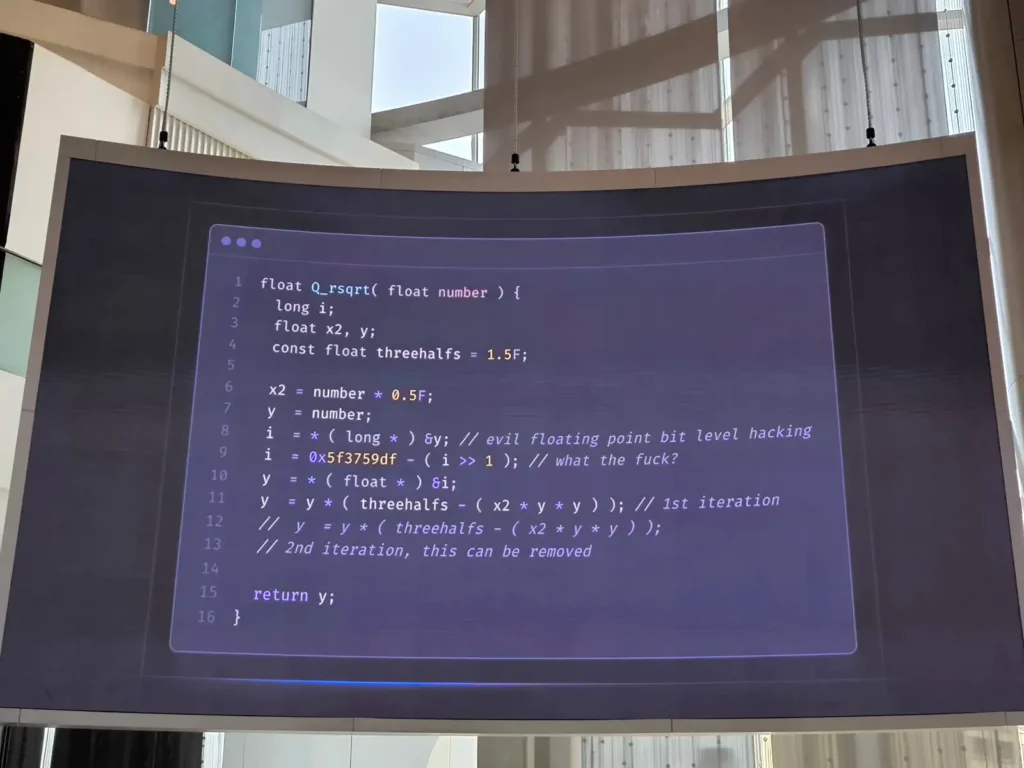
💡Fast Inverse Square Root เป็น Code ที่ช่วยให้เกม Doom รันได้บน คอมเก่าในยุคนั้นนะ แต่มันอ่านยาก ยอมแลก เพื่อให้ Run ได้ในหลาย Enviroment ที่มากขึ้น
💡Elysia การ Map ของพวกลงไป ง่ายกับ End User แต่ Code ที่ใช้ Handle เรื่องนี้มี Code หลาบร้อย / พัน เพื่อให้ใช้งานได้สะดวก
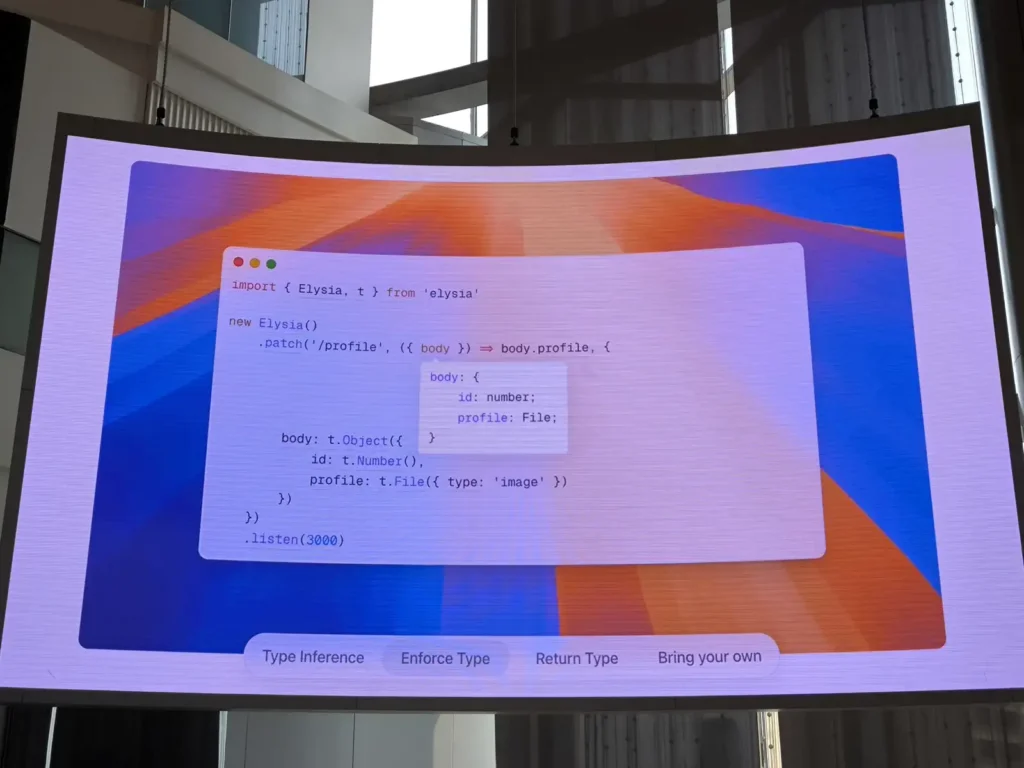
- มันจาก idea ใน js เรายัดอะไรลงไป พวก toString ออกมาจะได้ Code เลย
- Idea ของ Sucrose เอา Input พวกนี้เข้า AST มา และมาเติมอะไรที่ต้องการลงไปได้ Sucrose อารมณ์เหมือน Compiler และเอาเทคนิคนี้มาสร้าง Optimize Code ขึ้นมาได้เลย หรือเติมของก็ได้
จาก use case ทั้งหมด จะเห็นว่าเพื่อให้มันง่ายกับ End User ทาง Maintainer เลยไม่ได้เลือกวิธีการที่คนทั่วไปใช้กัน (Practical) แต่จะงัดมาทุกท่าที่คนทั่วไปไม่ได้ใช้ (Impractical) เพื่อให้มันครอบคลุมที่สุด ในทุก Edge Case และ minimal footprint
Resource: Slide
Take Control of Your Own Data via Self-Hosting Through Open Source Software
Speaker: Karnsiree Wongkolkitsilp

Session นี้มาแสดงให้เราเห็นว่าหลาย Service มันมีความสะดวกสบายก็จริง แต่เวลาใช้งาน Data มันอยู่กับ Service Provider ทั้งหลาย แต่เราจะรู้ไหม ว่า Service เหล่านั้นจัดการกับข้อมูลของเราอย่างไรบ้าง
📌แนวทางจัดการข้อมูลของ Service เหล่านั้นมี 2 ทาง
- แจ้ง + ตกลงใน End User Agreement ว่าจะเก็บอะไร ไม่เก็บอะไร ที่ยาวๆ แล้วเราไม่ค่อยอ่านกัน
- หรือ บางเจ้ามี Export Data ออกไปให้วิเคราะห์ แต่จะได้ทั้งหมดไหม บางทีระบบเก็บละเอียด แต่อาจจะให้ Export ไม่ได้ละเอียดขนาดนั้น เพราะ
- Business เอาไป อาจจะแข่งขันไม่ได้
- หรือ Performance ถ้าให้ดึงถี่ อาจจะก่อภาระ Server
- หรือ Development ขอเผื่อไว้ก่อน
📌แล้วถ้าเรากังวล จะต้องทำยังไง ?
เอา Open Source ที่มี Feature คล้ายๆ มา Deploy ใช้เอง เราต้องเข้าใจก่อนว่า Anatomy ทั้งไปเป็นยังไง หลักส่วน App Tier / Data Tier หลายตัวเป็น Container ให้มาลงแล้วด้วย
มี keyword Self-Hosting เอามาลงเอง ซึ่งคำนี้มีมานานแล้ว จริงๆเหมือน Model การขายด้วยแหละ เอามาลงเองฟรี หรือ subscribe ใช้งาน และตัว open source เองมันมีความสวยงาม ถ้ามี pain อะไร เราเข้าไปช่วยแก้ หรือทำอีกตัวขึ้นมาแชร์ได้ด้วย

📌Share Tools โดย Speaker
| commercial | commercial | opensource | note |
|---|---|---|---|
| Password Manager | LastPass / Bitwarden | VaultWarden | Valultwarden ถ้าเราลงเอง มันจะมีบาง Feature เช่น ตรวจกับที่ Leak เหมือนเสียเงิน หรือ ทำ 2FA ได้ มี Mobile App warden |
| Music Streaming | Spotify / Deezer | Navidrome | |
| Video Streaming | Netflix | Jellyfin | Jellyfin มันดีกว่าตัว Plex ที่มากับ NAS ดูเวลาได้ แปลง Format Encoding / หรือ แชร์เวลาร่วมกันได้ |
| Photo Sharing & Storage | Google photo / dropbox | Immich | Immich ทำ album และมี auto tag หน้า เหมือนขา Google photo และมี Mobile App ด้วยนะ |
| RSS Reader | Feedly | Miniflux | RSS Reader Subscribe Content ได้นะ ที่นีมีคนไปทำเพิ่ม เช่น ถ้าอ่านไปแล้ว ข้ามได้ หรือ สรุปรวม |
| Read It Later | Wallabag | มีข้อดี export ออกมาได้ เก็บ highlight ให้เราด้วย | |
| Note-Taking | Google Keep | Memos | จริงๆ มีตัว obsidian แต่มันจะซับซ้อนกว่านะ |
| Bookmark Manager | Raindrop | Linkding | ตัว Linkding ติด Tag ให้ Bookmark ได้ ค้นหาได้ / Archive Export |
| Web Analytics | Google Analytic | Umami | ตัว Script เบากว่า Google Analytic ด้วยนะ |
Resource: Slide / https://www.opensourcealternative.to/
Generative AI for Python developers
Speaker: Kanin Kearpimy

Generative AI - AL ที่ติดความจากคำพูดเรา แต่ตัวคอมรู้จักในรูปแบบ Token และเอา Token นั้น โยนเข้า LLM Model ไปติด ให้มันท้ายความเป็นไปได้ ว่าจะเป็นคำไหนออกมานะ (Probabilistic Distribution + Context)
เราจะรู้ได้ยังว่ามี Token เท่าไหร >> https://platform.openai.com/tokenizer ถ้าลองเข้าไปเล่นจะเห็นว่าแต่ละ model มีวิธีคิดต่างกันนะ
ตัวอย่าง Probabilistic Distribution และคำมีความเป็นไปได้ + กฏ + Context หรือ กฏ แบบ we need to stop
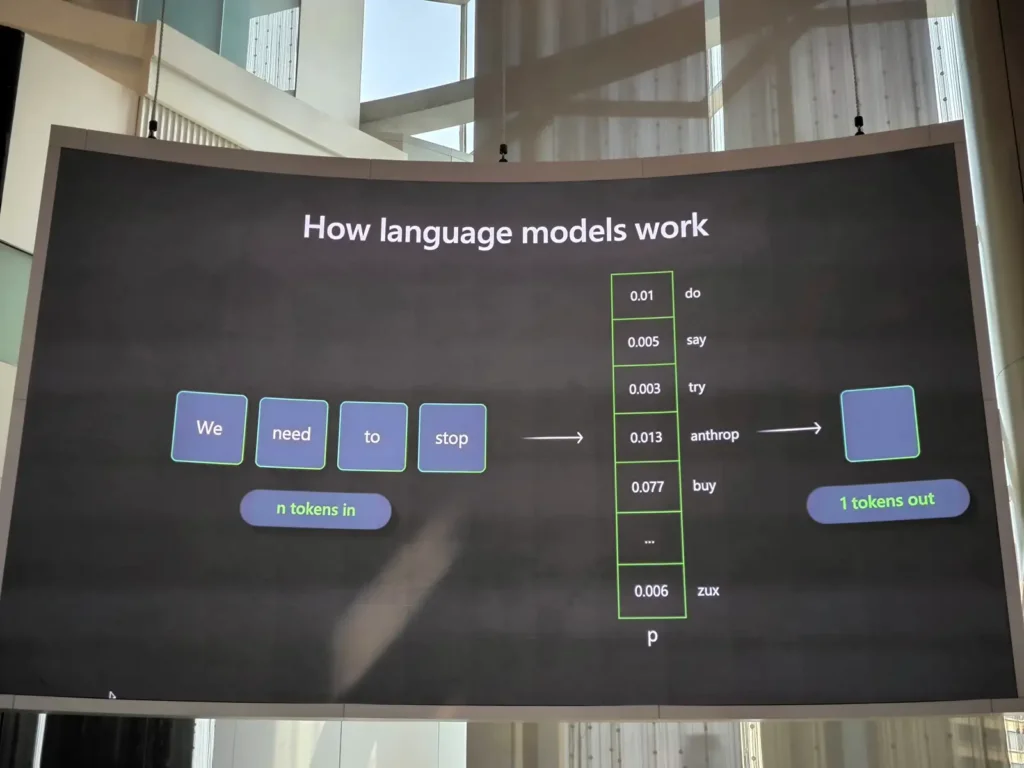
📌Prompt Engineering
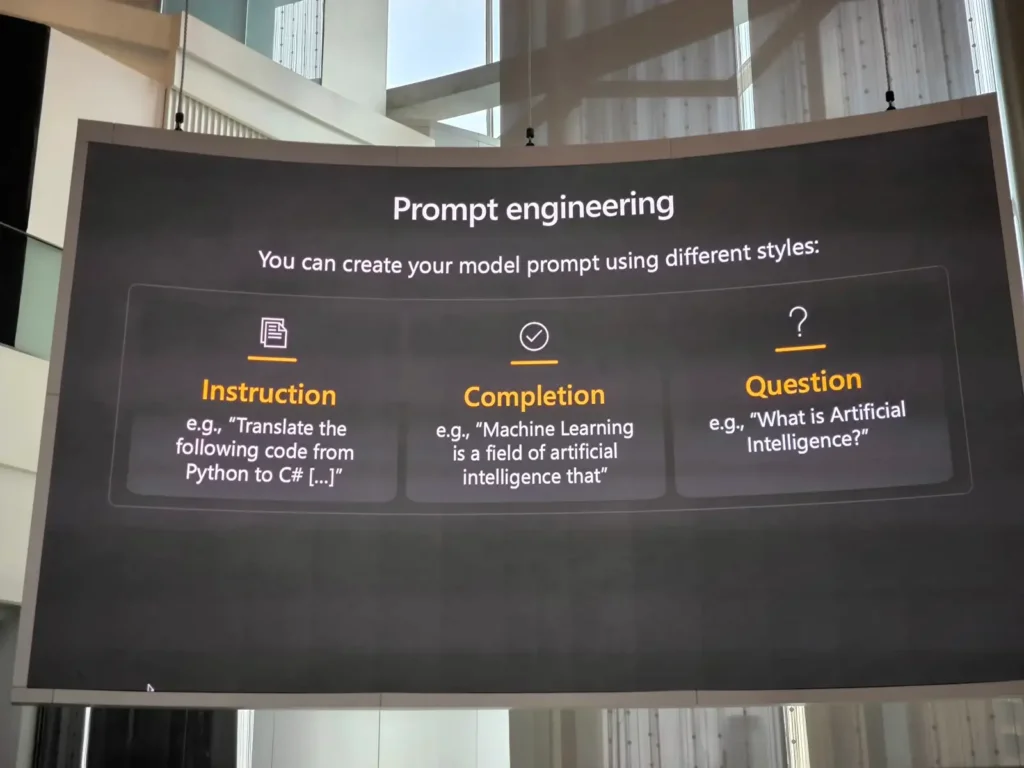
เพื่อทำให้ Probabilistic Distribution มันดี เลยมีเทคนิค Prompt Engineering โดยมี 3 ส่วน
- Instruction - สั่งเข้าไป
- Completing - เติมคำเข้าไป
- Questions เติมสิ่งที่เราถามไปได้
แต่ต้องมีตัวกันด้วย ไม่ให้ตอบแปลก ได้แก่
- System Prompt - กันจากระบบเลบ
- User Prompt ปกติเราจะได้ใช้ตัว User Prompt
📌สรุปแล้วมี Guideline ในการ Prompt ดังนี้

- กำหนด บุคลิก ลักษณะ หน้าที่ให้ชัดเจน (Persona) รูปแบบการแสดงออก Tone + Style รวมถึงการใส่ chat history เข้าไปด้วย ตัว AI มันไม่ได้ำบริบทเข้าไปหมดนะ การใส่ history มี Token ที่เสียเพิ่มด้วย
- ทำ meta grounding พวก
- Example
- Context
- Data ตอนนี้เทคนิคดังๆ ทำ RAG ให้ไปตรงกับ DB ของเรา - กำหนด Guard Rail บอกว่าอย่าทำสิ้งนั้น เตือนไป
📌ถ้าจะใช้ AI บน Azure
- Azure OpenAI เป็น Model LLM โดยให้เชื่อมต่อผ่าน Deployment Model Id + API Endpoint + Key
- ถ้ามี Model หลายตัวที่ต้องการใช้ตาม use case ต่างๆ เช่น Text / image ไปลองดูจาก Azure AI Foundry และก็ Deployment Model Id + API Endpoint + Key
อ่อ ลองหาๆดูมีคนเขียน Blog ไว้และ Azure OpenAI Service GPT-3 — แนะนำวิธีเริ่มต้นใช้งานและต่อกับ Application ง่ายๆ ! | by Orapin Anonthanasap | Medium
📌Azure OpenAI Function Calling
ทำให้ AI มันรู้ว่า ถ้ามีคำถาม pattern ตามนี้ ให้ Trigger Function หรือ ยิง Endpoint โดยที่ AI จะพยายาม Fill ข้อมูลให้ด้วย
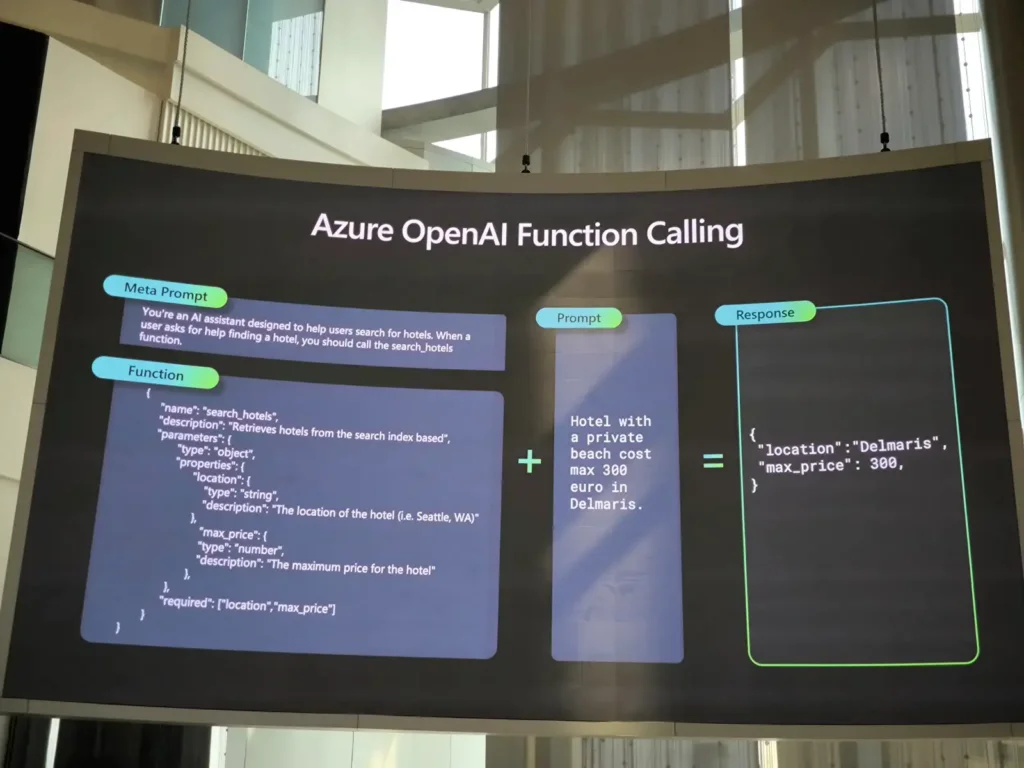
เมื่อได้ผลลัพธ์กลับมาจาก Function ให้ AI ตอบแบบมาช่วยแต่งตำให้เหมือน คนตอบ
ตอนจบ Meetup ก่อนกลับ มือถือเด้งให้ใช้ Gemini เลยได้ลองใช้ ถามทางกลับบ้าน มันเด้งเปิด Google Map นะเลยคิดว่าน่าแบบเดียวกัน
📌Model Knowledge
Model มันเรียนมาจำกัด เอาง่าย Model มันไม่รู้ว่าในร้านเราขายของอะไรบ้าง ต้องเอาข้อมูลจากใน DB เรามาใส่เพิ่มเป็น Prompt ก่อนส่งให้ Model เทคนิคนี้เรียกว่า RAG โดยมี Flow ดังนี้
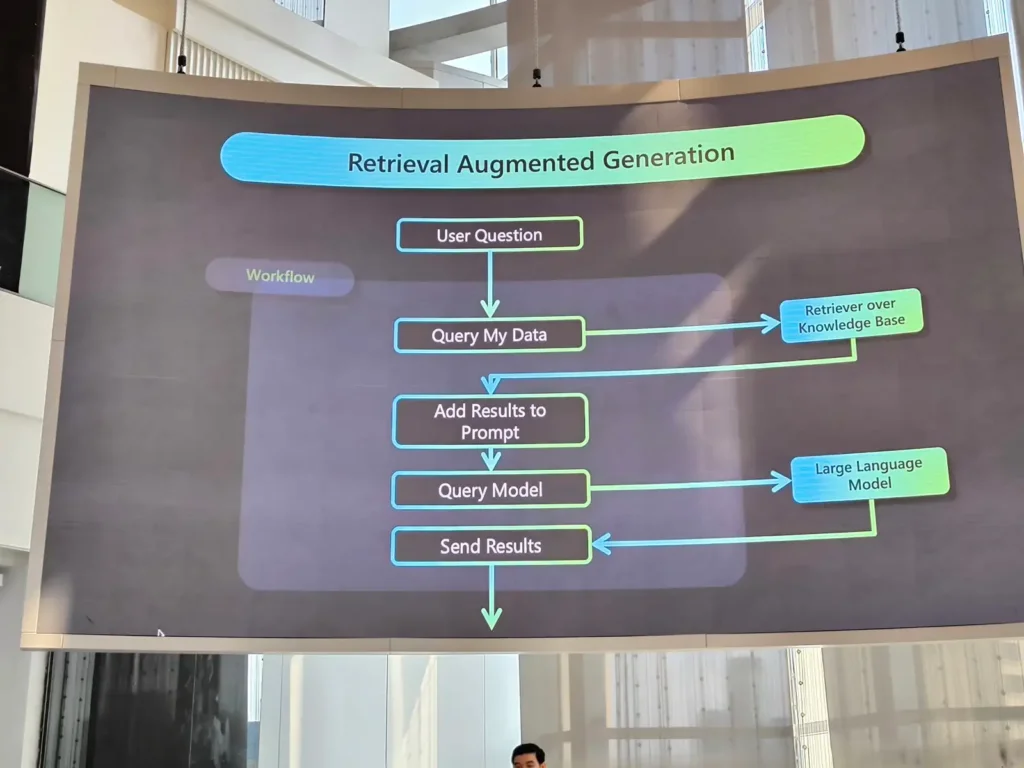
Resource: Google Colab / Workshop https://github.com/kanin-kearpimy/generative-ai-for-python-developer
แนะนำ Microsoft Applied Skill
หากใครอยากเรียนรู้ AI ตอนนี้ Microsoft มีโครงการให้เรียนรู้ และมี Lab ให้ลองนะ ลองอ่านได้จาก Blog นี้นะ
ได้ยินแว๊บๆ กลางปีนี้มีแจกสิทธิสอบ Cert นะ
The Magic Behind Shaders in Unity!
Speaker: Gittitat Ekchantawut
Session นี้มาแนะนำตัว WebGPU ตัวที่ใช้ HW มาช่วยการคำนวณได้สูงที่สุด เพราะ WebGL (เน้นวาด) / WASM ยังข้อจำกัดอยู่นะ เลยช้าอยู่ตามกราฟของ Transformer.js WebGPU เห็น Perf ชัดเจนเลย
นอกจากนี้งานแบบเดียวกัน WebGPU ใช้ Resource น้อยกว่า WebGL

📌แล้ว Shaders มัน คือ อะไร

- polygon มองเป็นหน่วยที่ย่อยที่สุดใน 3D โดยเอาหลายตัวมาประกอบกันเป็นรูปร่างขึ้นมา ซึ้งถ้าอยากให้มีรายละเอียดเยอะ มันจะต้องมี polygon ใน model เยอะๆ
- materials - เป็น css ของ model ทำให้สวย
- Shaders - เป็นรูปแบบหนึงของ materials ที่ทำให้ Model มีแสง และเรามีมิติออกมา ตามรูป
📌สรุป Shaders
Shaders เป็นการคำนวณ+เขียน logic จาก Computer Graphic Programmer เพื่อให้ตัว Model มันทำงานได้กับทุก Environment ยกตัวอย่าง เช่น น้ำ การกระเพื่อม ที่ดูไหลลื่น มาจากตัว Shaders ที่แบบซ้อนทับแสดงผล โดยที่ Shaders มองเป็น function กลาง ที่มาช่วย แต่มีความเข้าใจใน math ส่วนนึง
Resource: https://github.com/menstood/magic-of-shader

Build an AI copilot with MongoDB Atlas and Azure OpenAI
Speaker: Jirachai Chansivanon

📌Semantic Search
- เมื่อก่อนทำยังไงAPP -> DB ต้องการแบบ Extract Match
- หรือ ถ้าเอาเยอะกว่านั้น มีพวก Search Engine มา
แต่ยังมีข้อจำกัดว่าหาจาก Keyword ได้เท่านั้น หรือดูจาก synonyme
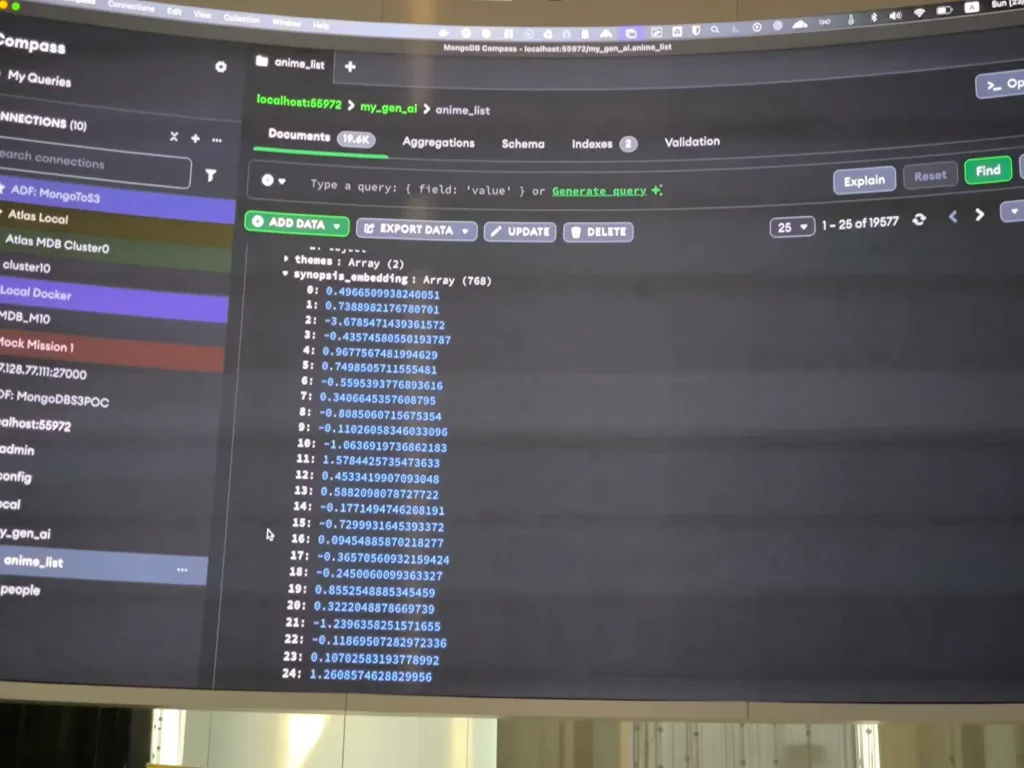
ตัว Semantic Search การหาจากความหมายเลยเข้ามาตอบโจทย์ตรงนี้ เช่น หุ่นยนต์แมวสีฟ้า >> เรารู้แหละว่ามัน คือ Doraemon โดย Semantic Search มันจะแปลงคำของเราเป็นตัวเลข Vector ไปหาความคล้ายด้วย Math นั้นเอง
การแปลงตัวอักษร หรือ รูปออกมาเป็นตัวเลย ต้องเอา Embedding Model มาช่วยแปลงให้เป็น Vector //อ๋อมันทำแบบนี้นี่เอง เห็นใน Catalog แล้วสงสัยอยู่ โดย flow การทำงานคุณจ๊อบ Speaker ได้อธิบายไว้ประมาณี้
user -sentence-> [ App + Embedding Model] - Search By Vector Data -> Vector Database
หุ่นยนต์แมวสีฟ้า
** Data ใน DB Vector Database มาจาก Embedding Model แปลงและเก็บ
** ข้อจำกัด ตอนที่จัดเก็บ และ Search ใช้ Embedding Model ตัวเดียวกัน
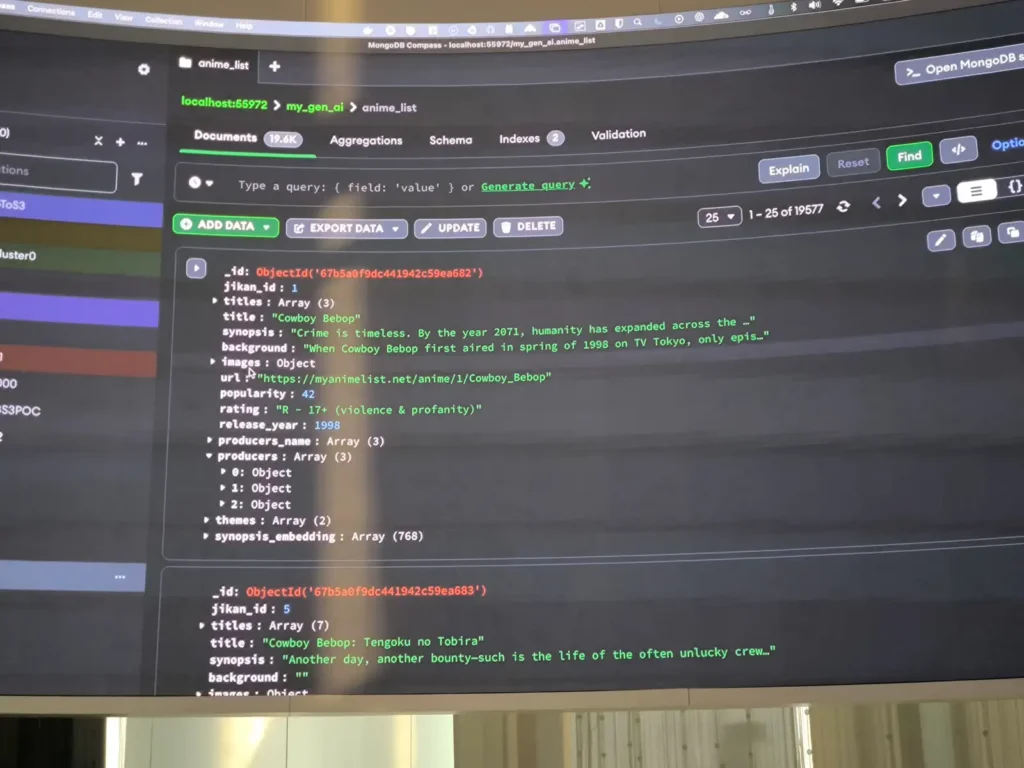

📌RAG + AG
- Recap RAG อ้างอิงจาก Session Python ได้เลย
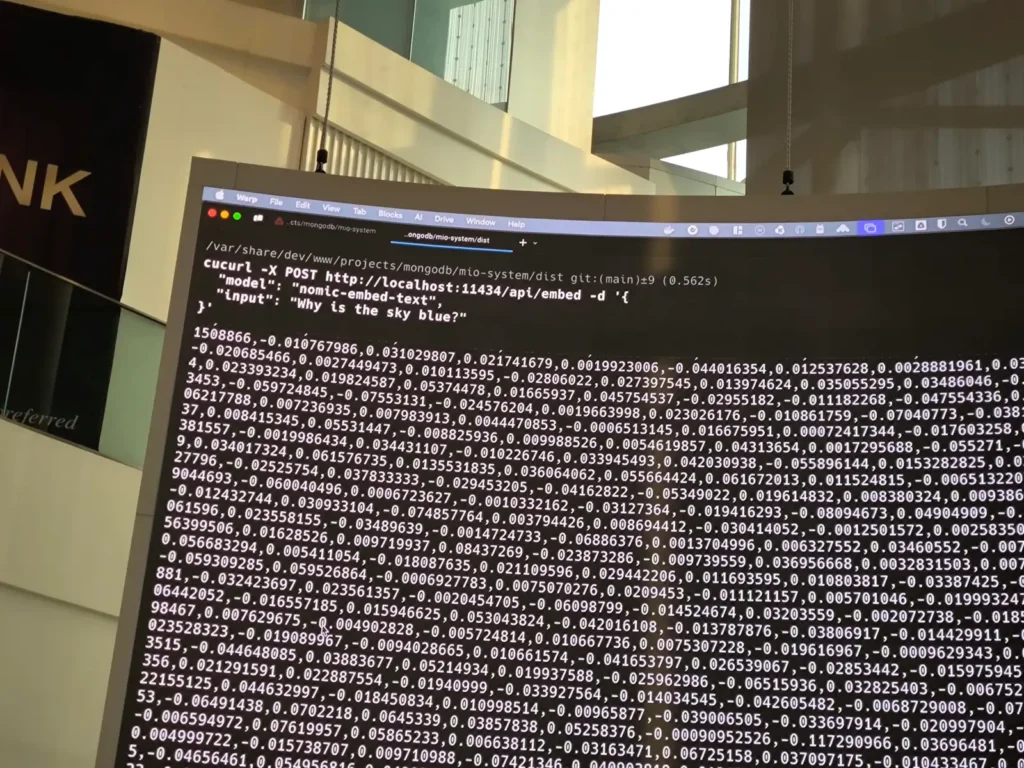
จากภาพเดิม เอาตัว LLM Model มาเสริม มาช่วยตอบคำถาม โดยมีข้อมูลจาก Vector Search 100 result+ deepseek-r1 มาสรุปตอบ โดย Deploy บน OLLAMA (Local LLM) ส่วน Session Python จะใช้ Cloud Service
user -sentence-> [ App + Embedding Model] - Search By Vector Data -> Vector Database -> LLM
หุ่นยนต์แมวสีฟ้า
Demo: TypeScript Elysia + Mongo DB Altas + Embedding Model nomic-embed-text
Resource: https://github.com/antronic/My-RAG-AI-Isn-t-That-Hard-to-Build
Building Container Images for Multi Platforms using Docker Bake
Speaker: Sirinat Paphatsirinatthi

Why Docker Bake
- Simplified Build Config - เดิม การบิ้ว docker ในหลาย platform จะต้องไปกำหนด Command เอง
- Improve Performance with Parallelization
- Consistency Across Team and Environment - ใช้ hcl / yaml config ได้เลบ
Run Single Command docker buildx bake
Resource: https://github.com/dmakeroam/docker-bake-demo/blob/main/docker-bake.hcl
ถ้าทำ Multi Platform จะเพิ่ม platform เข้าไปตามรูป
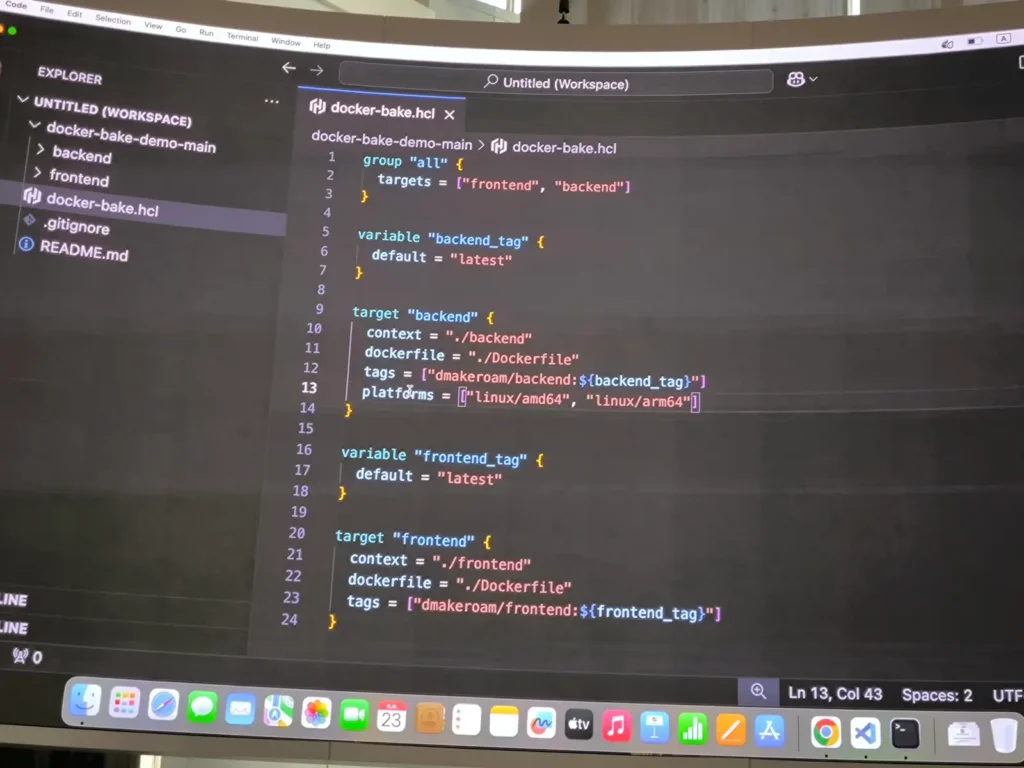
ตัวอย่าง Command
backend_tag=1.1 # Set Variable which define in bake file frontend_tag=1.1 # Set Variable which define in bake file docker buildx bake backend # backend is a target which define in bake file docker buildx bake all # all is a target which define in bake file
Multimodal or Large Language Model, What model should I use?
Speaker: Witthawin Sripheanpol
เมื่อก่อน ChatGPT มันจะ Simple ได้แต่ถามตอบ ยังไม่รู้จัก Image หรือ File นะ แต่ตอนนี้ ปัจจุบันทำได้หลายอย่างเลยตามรูป
ยกตัวอย่าง เช่น ใส่รูปไป ให้ AI ไปหาว่ามาจากไหน Link อะไร
📌LLM History
ยุคแรก > ยุค Deep Learning > ยุค Transformer (ตัว ChatGPT)

📌Transformer คือ อะไร
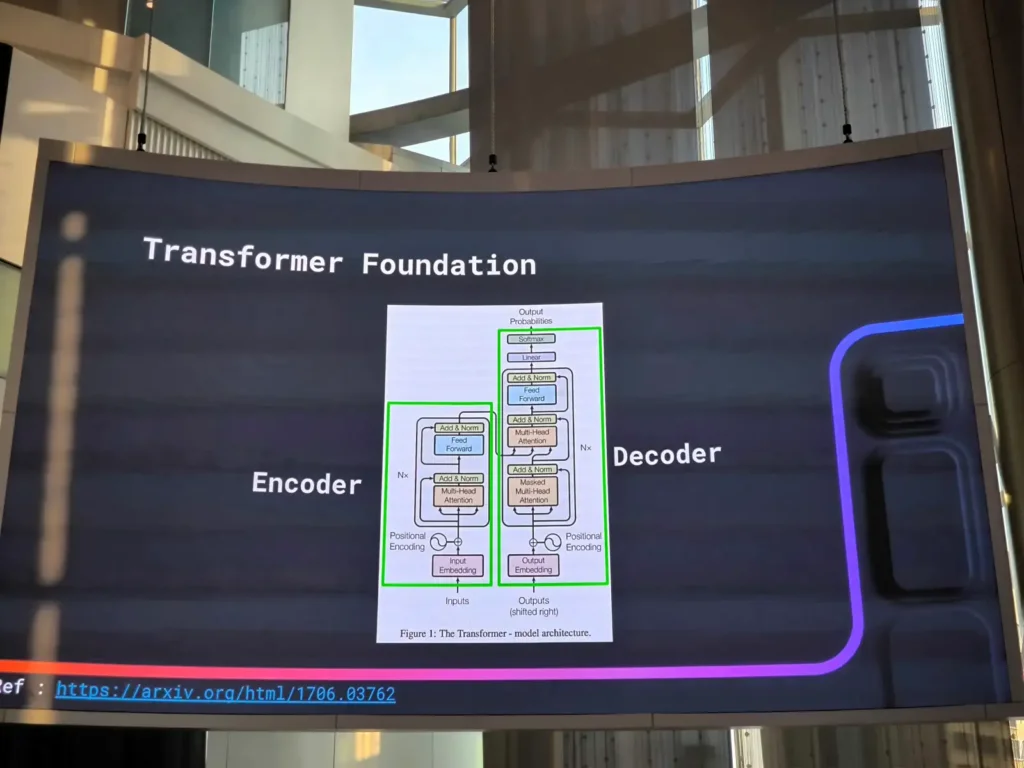
- Encoder ทำ Feature Engineering สกัดข้อมูลออกมาจาก input
- Decoder สร้างคำตอบ โดยการเดาคำ จากข้อมูลที่ AI มันรู้
โดย Transformer มัน LLM ตัวพ่อ Foundation โตยตัว Model มี Nx ทำให้ Scale ได้ จน GPU 1 2 3 ไม่พอแล้ว ตอนนี้ GPT3.5 1 Request ใช้ GPU 16 ใบ ในการทำงานนะ
📌ถ้าอยากให้ AI เข้าใจเรื่องอื่นต้องทำยังไง
ทำ Multi-Model โดยจะส่งอะไรก็ตาม แปลงเป็น Text ส่งให้ Model จัดการ เป็น Solution ที่ง่ายที่สุดนะ ตอนนี้มันน่าจะอ่านเองได้แล้วไม่ต้องแปลง

📌Multi-Model (Image Focus)
- Image Captioning
Image File > Image Captioning(แปลงรูปเป็น Text) > LLM - Vision Tranformer ให้ LLM เองเข้าใจรูปภาพ การทำงานตัดแบ้งรูปส่งให้ Tranformer ทำงาน
- VLM Foundation ตอนนี้ LLM ตัวเดียว มีความสามารถในการตีความรูปด้วย ตอนนี้มันเป็น Multi-Model
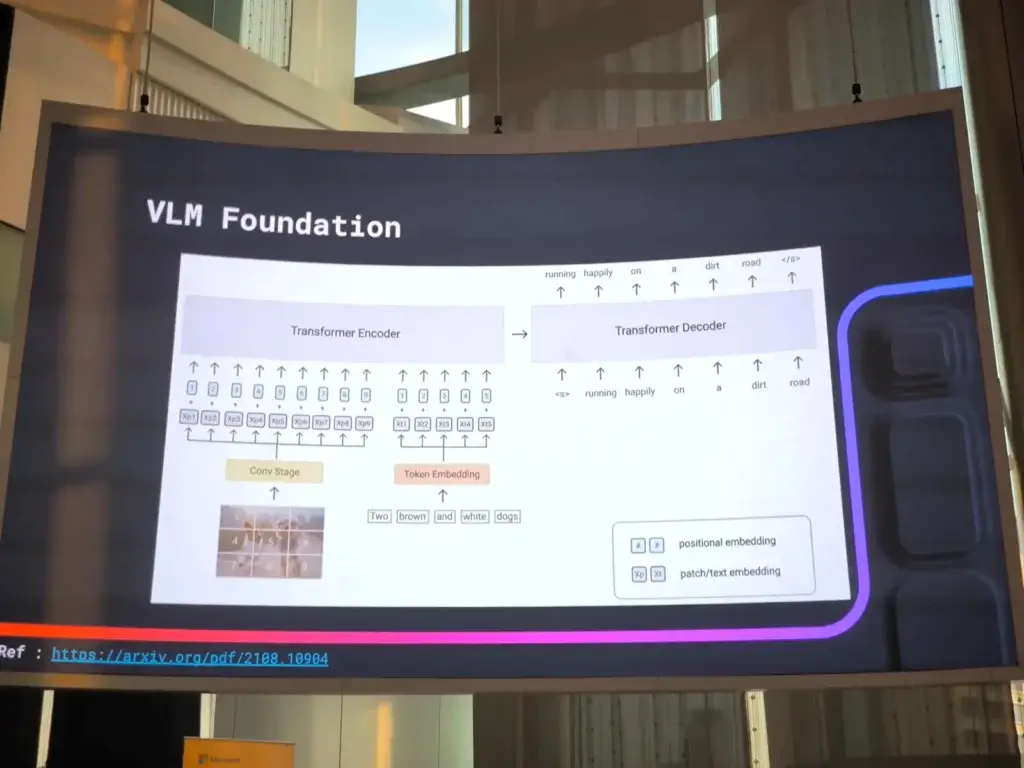
Multi-Model ในอนาคตอันใกล้นี้ โดยมี Encoder ในแต่ละเรื่องมาแปลงให้ตัว LLM เข้าใจ ในรูปแบบ Vector Math
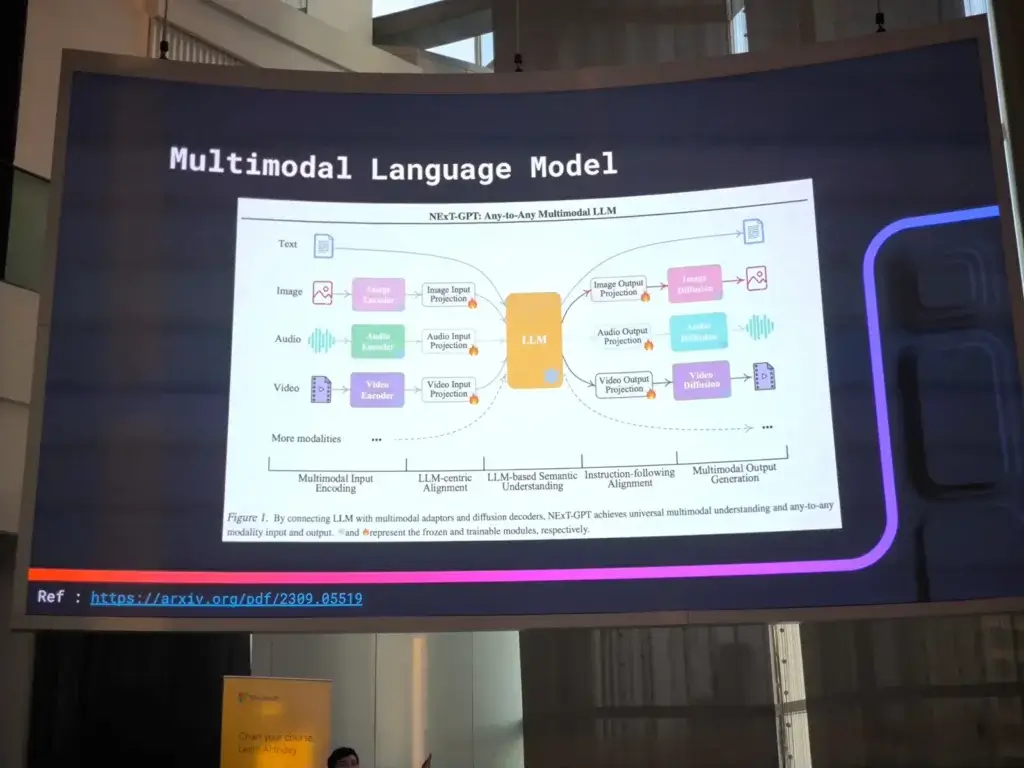
- ตัว Image Encoder มีหลายตัว ตัวที่ดังๆ ชื่อ CLIP (Contrastive Language-Image Pretraining)
- ตัว Projection เอา Vector ที่ได้จาก Encoder มาแปลง Vector ตาม Requirement ที่ LLM ต้องการ อารมร์ได้ของ Encoder มาเป็น Vector 128 แต่ LLM รับ 1024 ตัว Projection จะแปลงเป็นผลลัพธ์จาก Encoder 128 > 1024
Model ที่เด่นๆ ด้าน Image LLaVa มีทั้ง Encoder -> Projection -> LLM ตอนนี้เหมือนจะมาปรับๆ 3 ส่วนนี้ให้เก่งขึ้น ซึ่งถ้าจะเอาไปทำเพิ่ม Find Tune ต้องรวยก่อน มีการ์ดจอหลาย Node ได้ยินว่ามี 3 Step Find Tune

อีก Model Qwen2.5-VL เป็น Multi-Model (Text / Image)
นอกจาก Fine Tune Model แล้วมี อีก Technique RAG + Multi-Model RAG ตัวที่มาแรง ColPali
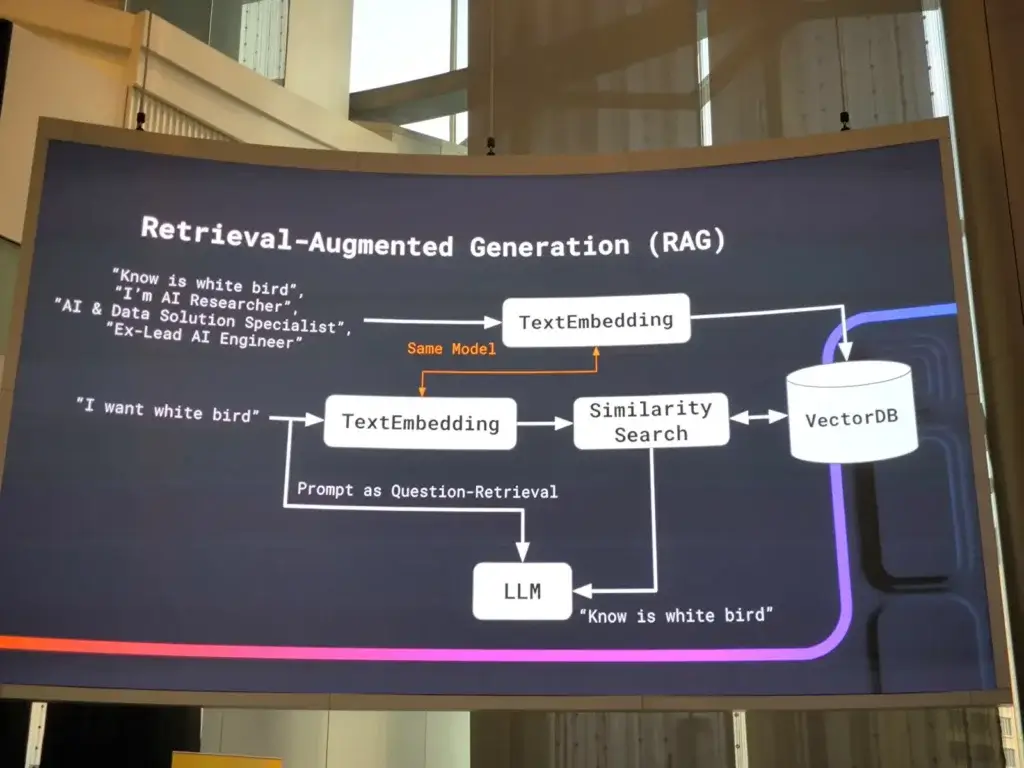

สุดท้าย ถ้าส่วนใหญ่ LLM ตอบโจทย์นะ แต่จะมีหลายเคสที่ช่วยต้อง Multi-Model RAG อย่างไล้ตรวจ Video ว่ามีคุยเรื่องนี้ตอนไหน
Resource: Slide
ถ้าอยากฟังเต็ม Speaker บอกว่ามี Session เต็มๆให้พังได้จุในงาน FOSSASIA+ ครับ
Reference
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


