สำหรับ Week นี้เป็นการเรียนภาษา R โดย Recap ที่เรียนๆมาตามนี้ครับ
ภาษา R
ภาษา R เป็นภาษาที่มีอายุมานานแล้ว พอกับ Python นี่แหละ ภาษา R ตัวเล่นกับ Data ได้ไว แอดทอยมีคำกล่าว
R is a fast data cuching language
R เป็นภาษาที่ Case Sensitive โดย Tools เขียน R online มีหลายตัว เช่น
- posit.cloud รองรับ R / Python / SQL / C++ เป็นต้น ผู้พัฒนา Lib ดังๆอย่าง tidyverse (hadley wickham) / pandas (Wes McKinney) อยู่ บ นี้นะ
- DATALORE ของ JetBrain ได้หลายภาษาเหมือนกัน
- Google Collab
หากไม่ได้ใช้บน Cloud ใช้ตัว R-Studio ได้นะ เหมือน posit.cloud
Delete บน posit cloud ไม่มีใน Recycle Bin นะ ถ้า Run Local มีนะ ระวังเรื่องการลบด้วย
ถ้าสงสัยอะไรเกี่ยวกับ Syntax ของ R ใช้คำสั่งตามนี้
help(function_name) ?function_name
Variable (ตัวแปร)
มันจะกลับสาย Dev ปกติใช้เท่ากับ =<-->
x <- 100 y <- 200 result <- x+y #Same Result 100 -> x 201 -> y x+y -> result
การตั้งชื่อตัวแปร เหมือนกันหลายภาษาเลย
- ห้ามขึ้นตัวด้วยตัวเลข
- ควรเป็น Lowercase ระวังเรื่อง Case Sensitive ด้วย
- ถ้าตัวแปรยาวๆแอดทอย แนะนำเป็น snake_case
ใน R เราสามารถคุม Flow ของตัวแปรได้ จากเดิมที่เราประกาศ x / y ไว้ ถ้างานนั้นจบแล้ว เราสามารถเอาตัวแปรที่ไม่ใช้ออกได้ ใช้ function rm(<varaible_name>)rm(x) / rm(y) เอาตัวแปร x y ออกจาก memor
Data Type
- numeric (number หรือ decimal ในหลายๆภาษาเช่น c#, java)
x <-100 #declare integer class(x) #class use for check varaible type age <- 34L #declare integer class(age)
- character (text)
my_name <- "ping" ; class(my_name) ; print(my_name)
#print แสดง standard io
#paste0 เชื่อมคำ
paste0("ping","eat","banana") #result > pingeatbanana
#paste เชื่อมคำ + เติม space คั่น
paste("ping","eat","banana") #result > ping eat banana
ถ้าเราอยากรวบคำสั่งให้ทำงานทีเดียว ใช้ ; คั่น
- logical (Boolean TRUE / FALSE)
- กำหนดเข้าไปเลย
x = TRUE class(x) y = FALSE class(y) a = T class(a) b = F class(b)
- หรือ ดูจาก Logical Operation
==/>=/<=/!=
(3+2)*5 == 25 (3+2)*5 == 50 (3+2)*5 != 50 (3+2)*5 >= 50 (3+2)*5 <= 50
- date
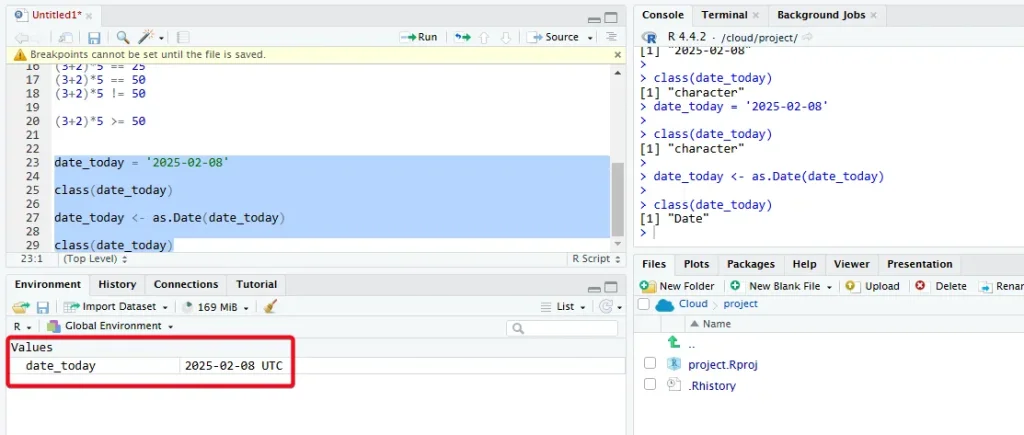
ปกติแล้วจะประกาศตรงๆไม่ได้ ต้องทำเป็น String ใช้ as.Date มาแปลง
date_today = '2025-02-08' class(date_today) #string date_today <- as.Date(date_today) #Convert to Date and write back to date_today variable class(date_today) #date
- factor
ตัวแปรแบ่ง category ในทางสถิติ categorical data
gender <- c("m","m","f","f","o")
class(gender) #string vector
gender <- as.factor(gender)
class(gender) #factor
table(gender) #นับว่าแต่ละกลุ่มมีจำนวนเท่าไหร่ ใช้กับ factor
#result
#gender
#f m o
#2 2 1
- การแปลง data type ไปมาใช้ as.xxx_dataType
num = 1 as.character(num) as.logical(num) #TRUE num = 0 as.logical(num) #FALSE #============================= #แปลง String 2 Date date_today = '2025-02-08' date_today = as.Date(date_today) #============================= #แปลง vector > factor as.factor() #============================= #แปลง String 2 numberic x = "100" x = as.numeric(x) #numberic
Data Structures (โครงสร้างข้อมูล)
- Vector
Array ต้องเก็บข้อมูลที่มี Data Type ชนิดเดียวกัน
- Create (seq Function)
1:5 #generate number 1 2 3 4 5 seq(1,100,5) #googl sheet =SEQUENCE()
- Create c function
#without key gpa = c(3.14, 3.50, 3.00) #with key gpa = c(ping=3.14, kook=3.50, tarn=2.00)
- access/subset start index from 1
#1. with index
gpa[1]
gpa[1:2] #เอา ping kook
gpa[2:3] #เอา kook tarn
#2. with name
gpa["ping"]
gpa[c("ping","tarn")]
#3. with condition
gpa[gpa > 3]
- Vectorization ทำ operation ทั้ง Vector
gpa + 0.05 #เพิ่ม GPA ให้ทุกคนใน Vector คนละ 0.05 gpa - 0.02 #ลด GPA ให้ทุกคนใน Vector คนละ 0.02 #ถ้าภาษาอื่น จะต้องใน for loop
- ถ้าจะแก้ไขข้อมูลใน Vector เราต้องรู้ Index หรือ Key
gpa[1] <- 3.99 gpa["kook"] <- 4.00
- เอา Vector มาต่อกัน
#Concat gpa = c(ping=3.14, kook=3.50, tarn=2.00) gpa2 = c(guide=3.14, bank=2.50) final_gpa = c(gpa, gpa2) #merge 2 vector #result should be #ping kook tarn guide bank #3.99 4.00 2.00 3.14 2.50
- Matrix
vector ที่มีหลายมิติ ต้อง Type เดียวกันนะ
- Create
matrix(1:10, ncol =5) #result # [,1] [,2] [,3] [,4] [,5] #[1,] 1 3 5 7 9 #[2,] 2 4 6 8 10 #======================================= matrix(1:10, ncol =5, byrow = TRUE) #result # [,1] [,2] [,3] [,4] [,5] #[1,] 1 2 3 4 5 #[2,] 6 7 8 9 10 #======================================= #สร้างเป็นเลขคี่ seq(1,30,2) matrix(x, ncol =3)
- Vectorization คุณทุกตัวใน Matrix เหมือนกันหมด
> m1 = matrix(1:10, ncol =5)
> m1
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> m1 * 2
[,1] [,2] [,3] [,4] [,5]
[1,] 2 6 10 14 18
[2,] 4 8 12 16 20
- Element-Wise Computation - เอาตัวเลขใน matrix ตำแหน่งเดียวกันมา บวก ลบ คูณ หาร
mA <- matrix(c(1,2,3,5)) mB <- matrix(c(1,2,4,5)) mA + mB mA * mB
- subset matrix use index for eacg dimension
> mC <- matrix(c(1,2,3,5), ncol = 2)
> mC
[,1] [,2]
[1,] 1 3
[2,] 2 5
> mC[1,1]
[1] 1
> mC[2,1]
[1] 2
> mC[, 1]
[1] 1 2
> mC [2, ]
[1] 2 5
- list
เก็บ data แนวๆ document / json
- create - ตอนสร้างครั้งแรก ผมเหมือน json มี Key และ Value โดยจะเป็นอะไรก็ได้
employee_1 <- list(
name = "pingkunga" ,
age = 34,
program_skil = c("csharp","sql","vue"),
netfix_sub = TRUE,
idcode = matrix(c(1,2,3,5), ncol = 2)
)
- Access ด้วย วงเล็บก้ามปู [] มี 2 แบบ
-["key_name"]ดึง key + value
-[["key_name"]]เอา Value ของ Key นั้นๆออกมา
#Get Key > employee_1["name"] $name [1] "pingkunga" #Get Value of each key [[]] > employee_1[["name"]] [1] "pingkunga"
- ถ้าใส่ Key ผิด มันจะ Error หรือ ยังไง ระหว่างเรียนพิมพ์ผิด เลยได้ Case นี้มาด้วย สรุปได้ NULL ไม่ Error อะไร
> employee_1[["program_skil "]] NULL
- นอกจากนี้ ถ้า Value เป็นพวก Vector เราสามารถใส่ index / key เสริมเข้าไปได้นะ
> employee_1[["program_skil"]] [1] "csharp" "sql" "vue" > employee_1[["program_skil"]][2] [1] "sql" > 3 [1] 3 > employee_1[["program_skil"]][3] [1] "vue"
- นอกการใช้วงเล็บก้ามปู [ ] ทำแบบ Vector ได้ด้วย โดยใช้ $
#Get Value of each key $ > employee_1$program_skil [1] "csharp" "sql" "vue" > employee_1$program_skil[3] [1] "vue"
ถ้ามีอีกตัว เพิ่มเข้าไปได้เลยนะ ถ้าแม้ว่าจะมี Key ไม่ครบมันเทรวม
employee_2 <- list(
name = "guide" ,
age = 38,
program_skil = c("spring","sql")
)
#Concat
all_customer = list(my_list , customer2 )
- Access in List มี 2 แบบเดิมครับ ถอยออกมาในมุมสูงขึ้น แต่ Concept เดิม วงเล็บก้ามปู []
-["key_name"]ดึง key + value
-[["key_name"]]เอา Value ของ Key นั้นๆออกมา
นอกจากนี้ใช้$ได้เหมือนเดิมนะ
all_employee[1] #ได้ [1] : employee_1 all_employee[[1]] #ได้ employee_1 นอกจากนี้ใช้ $ ได้เหมือนเดิมนะ > all_employee[[1]]$name [1] "pingkunga"
- data frame
การแสดงข้อมูลในรุปแบบตาราง เหมือนใน Excel / Sheet / SQL
- Create from vector ต้องมีขนาดเท่ากันด้วยนะ
id <- 1:3
name <- c("ping","guide","kook")
age <- c(34,33,38)
netflix <- c(T,F,T)
spending <- c(199, NA, 0)
#NOTE: NA is null
#each vector must same size
df <- data.frame(id, name, age, netflix, spending)
df
#result
# id name age netflix spending
#1 1 ping 34 TRUE 199
#2 2 guide 33 FALSE NA
#3 3 kook 38 TRUE 0
- check size
#check size dim(df) [1] 3 5 #3 Rows 5 Columns
- access by key
#access by key > df$id [1] 1 2 3 > df$name [1] "ping" "guide" "kook"
- access/subset มี 3 แบบเหมือนเดิม
- 1. with row index/col index
- 2. with row index/col name
- 3. with condition
# 1.with row index / col index #get row2 col 1 df[2,1] #get row2 ไม่ต้องใส่ index df[2,] #get row5 df[5,] #===================================== # 2. with row index / col name #ทำได้ 2 แบบ #>> แบบที่ 1 df[2, "age"] #>> แบบที่ 2 ได้ผลเหมือนกัน df$age[2] #===================================== # 3. with condition df[df$spending > 200, ] #same result df[df$netflix == TRUE,] df[df$netflix,]
- New Column / Delete Column
#new column total_spending df$total_spending <- df$spending + 300 #delete df$total_spending <- NULL
- Update Column by access/subset
#Updatg by position row 3 / columm spending df[3,5] <- 499
- create new data frame เอาไว้ กรองข้อมูลที่เราต้องการ และมาวิเคราะห์ต่อ
#filter data frame netflix_df <- df[df$netflix == TRUE,]
- Save / Read File
#save file
write.csv(netflix_df,"netflix_sub.csv", row.names=FALSE)
#read file
readcsv("netflix_sub.csv")
ตอนแรกสงสัยว่าลบยังง เลยลองไปหาดู r - How do I delete rows in a data frame? - Stack Overflow
แอดทอยมีเสริมว่า Data Structure ใช้ประจำ Vector / List / Data Frame เอาจริงๆ Matrix หรือ Array หลายมิติผมเอาที่เป็น Dev มาปี ใช้แบบนับครั้งได้เหมือนกันนะ
Function
- build-in
มีหลายตัว เราใช้ประจำ เช่น
- print() แสดงข้อมูล
- readline() รอ user input
# Ask the user for their age age <- as.numeric(readline(prompt="Enter your age: "))
- sample() สุ่ม
vector <- c("apple", "banana", "cherry", "date", "elderberry", "fig", "grape")
# Sample 3 elements สุ่มมา 3
sampled_vector <- sample(vector, 3)
# Sample 1 elements สุ่มมา 1
sampled_vector <- sample(vector, 1)
- user-defined
- create function
#basic with
#- parameter num1, num2
#- return บอกส่งอะไรกลับไป ถ้าไม่ใส่อาร์มันจะเชื่อค่าตัวสุดท้าย ตัว return() มันนับเป็น build-in fuxction นะ ลืมใส่วงเล็บแล้วแตก
#- สิ่งที่อยู่ใน function อยู่ใน scope นั้น
add_two_nums <- function(num1, num2){
#sum2 local varaible
sum2 <- num1+num2
return(sum2)
}
#short form
add_two_nums_short <- function(num1, num2) num1+num2
#sample use
> add_two_nums(5,2)
[1] 7
> ans <- add_two_nums(5,20)
> print(ans)
[1] 25
> add_two_nums_short(1,4)
[1] 5
ถ้าดู function definition ให้ชือ function ไม่ต้องมีวงเล็บ เช่น
add_two_nums_short
- create a function with default arg
#default arg
mycube <- function(base = 10, power = 2){
base * power
}
#sample use
> mycube()
[1] 100
> mycube(power=5,base=3)
[1] 243
> mycube(base=5,power=3)
[1] 125
>
Control Flow
- if else
- console ลองแบบง่ายๆ
score <- 70
if (score >= 70){
print("A")
}
- ถ้าเอาแบบให้สื่อทำเป็น function
#with function
grading <- function(score) {
if (score >= 70){
print("Excelllent")
return("A")
}
else if (score >= 60){
print("Good")
return("B")
}
else{
print("Fighting")
return("C")
}
}
#sample
> grading(49)
[1] "Fighting"
[1] "C"
> grading(60)
[1] "Good"
[1] "B"
> grading(90)
[1] "Excelllent"
[1] "A"
- นอกจากนี้ส่วนเงื่อนไข เอาหลาย Condition ได้นะ
#Truth Table (AND)
T & T #TRUE
T & F #FALSE
F & T #FALSE
F & F #FALSE
#Truth Table (OR)
T | T #TRUE
T | F #TRUE
F | T #TRUE
F | F #FALSE
# =========================================================
# ลองคิดโจทย์เอง อยู่ไปนึกถึงตอนทำปี 1 เลยลองเขียนด้วย R
# Function to check if a number is both positive and even
check_positive_even <- function(num) {
if (num > 0 & num %% 2 == 0) {
return(paste(num, "is positive and even."))
} else if (num > 0 & num %% 2 != 0) {
return(paste(num, "is positive but not even."))
} else if (num <= 0 & num %% 2 == 0) {
return(paste(num, "is non-positive and even."))
} else {
return(paste(num, "is non-positive and not even."))
}
}
#Sample
print(check_positive_even(8))
print(check_positive_even(-8))
print(check_positive_even(7))
print(check_positive_even(-7))
- for while
- for วน access แต่บาง Data Strucuture แอทอยเล่าว่าทำ Vectorization ได้ไวกว่านะ เอาโจทย์ปี 1 เลขคู่ มาเหมือนเดิม
vector <- 1:10 #Create Sample Vector
results <- list()
for (i in vector) {
# Check if the element is even
if (i %% 2 == 0) {
# If the element is even, add it to the results list
results <- c(results, i)
}
}
print(results)
- while วนจนกว่าเงื่อนไขจะเป็น False
counter <- 1
max_value <- 10
while (counter <= max_value) {
print(counter)
counter <- counter + 1 #ห้ามลืม เดวมันเกิด infinite loop แล้วค้าง
}
ใครที่อยากดูเต็มๆ ผมมีจดลง Notion ไวนะคร้าบ R101#01 / R101#02 และ R101#03 เดี๋ยวว่าๆค่อย Migrate ไปที่อื่น
แอดทอย แนะนำหนังสือ
The 5 Types of Wealth - ความมั่งคั่งนอกจากเงินแล้ว ก็มีความสุข ครอบครัว สุขภาพ เมื่อเช้าเพิ่งกรอบซื่อหนังสืออีก Semantic Kernel in Action ไป จดไว้ใน List ก่อน
วันนี้ลอง posit.cloud โอเคเหมือนกันนะ หน้าเหมือน R-Studio ที่ลองที่คอมเลย แต่ชอบเจอ Restart Engine บ่อยๆ แต่รอไม่นนานก็ใช้ได้ต่อ อ่อ และมีการบ้านแล้ว แปะไปแล้วใน กลุ่ม เอา Gist มาแชร์ไว้ เกมเป่ายิ้งชุบ https://gist.github.com/pingkunga/bce10fe7b21affd55d7344a34c3d0217
เขียนจบแล้วต้องรีบนอน พุ่งนี้มีงานกลิ้ง ไม่รู้ว่าจะตื่นทันไหม 555
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


