
วันนี่้มีงานฟรี เลยไปฟังมา จัดที่ SCK Dojo ครับ ตอนไปผมหลง ลง MRT ผิดสถานี และตอนเดินมาเชื่อ Google Map เข้าผิดซอยด้วย 555 โดยสำหรับหัวข้อวันนี้จะประมาณนี้ครับ
MongoDB คือ อะไร
เป็น NoSQL แบบนึง โดยจะในรูปแบบ Document โดยที่ 1 Document อารมณ์ประมาณ 1 Record แต่มันทำได้ยึดหยุ่นกว่า เช่น ไม่ได้ Strick เรื่อง Field โดยที่ 1 Document จะใหญ่สุดๆได้ 16 MB ซึ่งจะจัดเก็บในรูปแบบ BSON (JSON ที่บีบอัดแล้ว)
- Advantages
- Cloud base NoSQL As A Service MongoDB Atlas Database
- flexible document schema ไม่ต้องกังวลเหมือน RDBMS มันไม่ lock column ยัดลงไปได้เลย มี หรือไม่มี Schema ก็ได้ แต่ควรทำ schema validation จะได้ไม่มีปัญหาภายหลัง
- ใน Database กำหนด Collection อะไรให้ก่อน ซึ่ง Collection = กลุ่ม Document มี Key/Index Limit 64 ตัว
- support หลากหลายภาษา เข้าใจว่าเป็นพวก Library / Driver นะ
- powerful querying ด้วยตัว MongoDB's Query Language (MQL) + analytic
- Easy to horizontal scale-out with sharding ต้องวาง Component ดีก่อน
- Simple Install - Disadvantages- ง่าย เลยทำให้ผิด บ่อย อาจจะเอาแนวคิดของ RDBMS ตั้ง แต่จริงๆควรเอา Usage Pattern มาตั้งมากกว่า
MongoDB Version
- Community
- Enterprise
- Atlas - PaaS เอา DB ไปฝาก ตอนนี้มีของเด่นๆ
- พวก Search+ AI Atlas Search
- Streaming Processing = kafka
ตัว Version ของ MongoDB มี Stable 5 6 7 8 / Rapid พวก .1 . 2 (มันของที่เอาไปใน Stable ถัดไป มาให่ลองก่อน)
MongoDB Deployment
- Standalone

- Replication (Replication Set) - เน้น HA
- 1 ตัว Primary (Read/Write) ที่เหลือเป็น Secondary โดยจะ Sync ทุก 2 Sec ถ้า Primary หัวหน้าตุย Secondary ที่ Timestamp มากสุดจะขึ้นแทน
- ตัวกลุ่มที่ Voter (กลุ่มที่จะสิทธิได้เป็น Primary ) ได้สุดสุง 7 ตัว
- Replication Set ยัดได้มากสุด 9 / หัก Voter 7 แสดงว่าสามารถเปิด Read On Standby 2 ตัว แต่ข้อมูลจะช้ากว่า 2 Sec //เอาปรับสัดส่วนได้นะ 4 Voter 3 / ROS 1
- จริงๆ Secondary ทุกตัว ไม่จำเป็นต้องไปดึงจาก primary ก็ได้ ถ้ากลัว primary ทำงานหนัก เอา P <-S0 <S1,S2,S3 มาดึงต่อไป แต่ S0 พังเละ
- ถ้า Secondary ส่ง write > read node มันไม่ให้ //DB2 คือ HA หลุดเลย
- Initial Secondary ถ้าตายไปแล้ว Data เยอะ Copy มาใส่น่าจะไวกว่า Sync , Speaker เคยลองแล้ว 1TB ใช้ 2 Week - Sharding - แยกเก็บ ช่วยกันอ่าน parallel (Horizontal Scaling)
- ถ้าข้อมูลเกิน 1 TB ควรแยกออกมา เพื่อให้ Backup เร็ว / Query เร็ว ลด Cost ด้วย ยิ่งใช้แรมเยอะ เครื่องมันแพง แบ่งเครื่อง node ออกมาเป็นกลุ่มย่อยๆ
- ที่ยาก Shard Key ทำให้ ทุก Shard Balance ได้
- Collection Shading - Table Partition ใน RDBMS
Tuning อาจจะดู Data แยก Collection ออกมาก่อน แล้วถ้าไม่ไหวค่อยมาท่า Sharding ก็ได้นะ
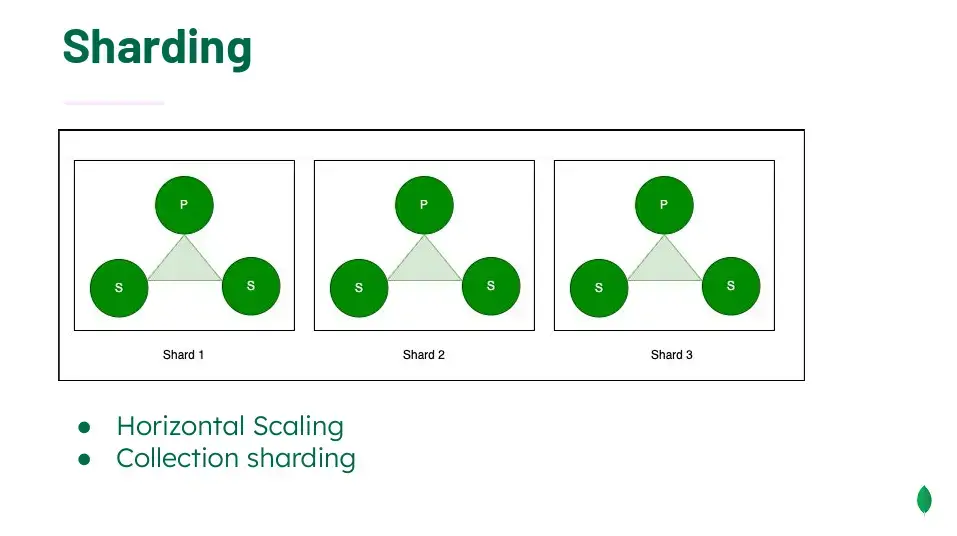
- Sharding + Replication Set แบ่งกลุ่มกันทำงาน และมี HA
Data Modeling
แนวคิดมันจะต่างกับ RDBMS มองตาม App usage (Read / Write Ratio) เน้นที่ใช้กัน 6 ตัว
- Computed Pattern (เดิม Pre-Computed)
- ทำอะไรบ้างอย่างก่อน Write / Update เช่น ทำ Sum / Average
- ส่วนตัวทำที่ App หรือ แยก Batch อันนี้ทำที่ฝั่ง Client ของ Mongo แล้วส่งไป Save ถ้า document เป็น Order ติด Sum / Count - Inheritance Pattern
- Polymorphism ของ OOP ข้อมูล มี Field ที่ต่างกันน้อย เหมือนกันเยอะ
- ถ้าไปแยก Collection แล้วมา Join Cost มันจะเยอะ เลยเอามารวมกัน และหา Column ที่ Common เป็น Key - Extended Reference Pattern
- เอา Field ที่นิยมใช้ มาแปะกับอีกที Collection ภาพแบบ denormalization นี้แหละ ลด Join
- แต่เอามาแปะเยอะไม่ได้ 1 Document 16 MB หรือ ประมาณ 200 Fields - Schema Versioning Pattern
- ใช้ตอน App ไม่อยากมี Downtime เพิ่ม Field schema_version เข้าไป ของเดิม ถ้าไม่เคยทำอาจจะ assume เป็น v1 จาก query - Subset Pattern
- ให้ตัวอย่างมาก่อน แล้วถ้าอยากดูเต็มไป ไปเอาจากอีก Collection จะได้ลดขนาดของ Document
- เช่น Collection Product จะมี Product ห้อย Review 10 อันแรก ถ้าจะเอา Review ทั้งหมดให้ไปดึงจาก Collection Review แทน - Bucket Pattern
- compute + subset pattern เน้นทำให้ Idx Ram + Storage น้อย
- ออกแบบมาทำพวก Time Series โดยเริ่มมีมาใน MongoDB 5.0 Time Series Collections — MongoDB Manual เพราะก่อนหน้านี้ลองไป Apply กันเองแล้วเจอปัญหากัน
- ถ้าคาดการณ์แล้ว Data เยอะ ควรทำ Shard ไม่ให้ document Storage ใหญ่ไป
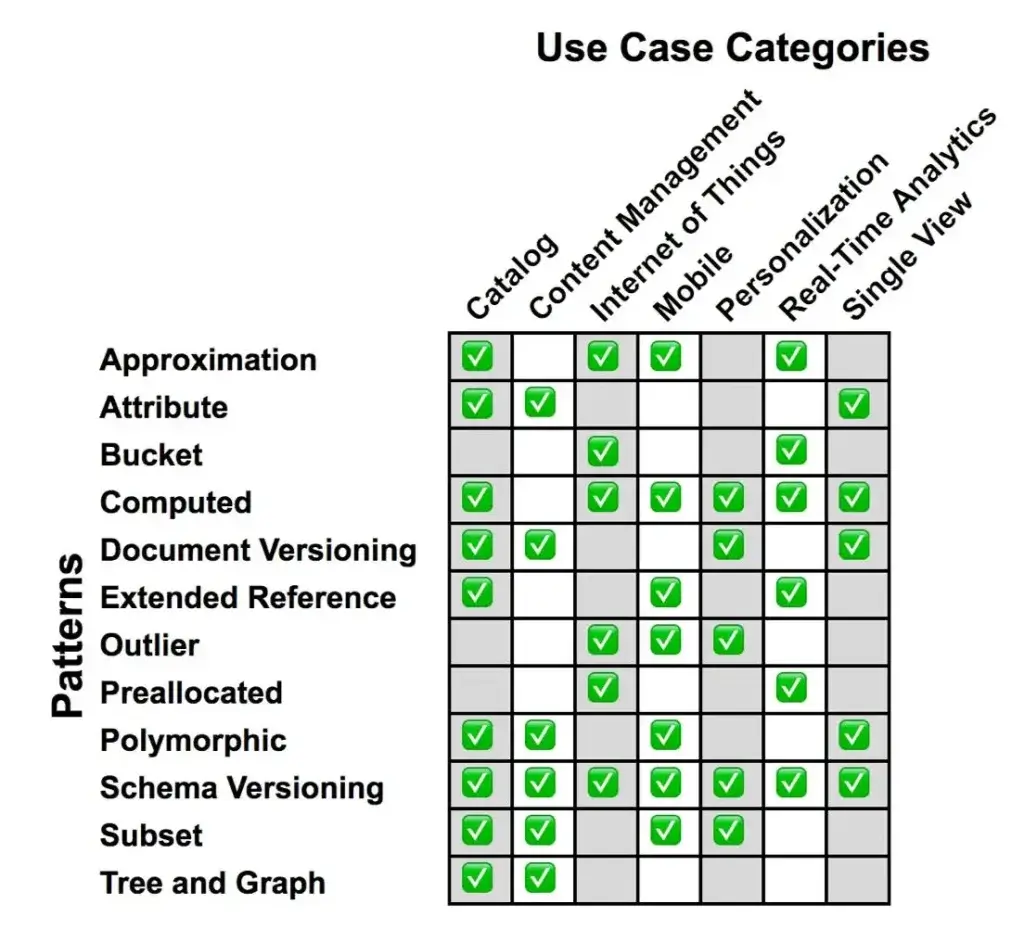
และมี Pattern อื่นๆด้วย สรุปตามภาพนี้ ซึ่งผมก็จิ๊กมากอีกที 55 อ่านเต็มๆที่นี่เลย Building with Patterns: A Summary | MongoDB
Tools
- Monitor + Suggestion
- Open-Source: simagix/keyhole: Survey Your Mongo Land - MongoDB Performance Analytics (github.com)
- Money Power: MongoDB Ops Manager | MongoDB - Data Modeling
- Hackolade - Data modeling tool for NoSQL, storage formats, REST APIs, and JSON in RDBMS
- MongoDB Relational Migrator | Modernize Legacy Apps | MongoDB
อื่นๆ
- พวก pdpa mongo ตั้งแต่ V7 มีตัว Queryable Encryption Queryable Encryption — MongoDB Manual
- Books: รวมท่าการใช้ Mongo Practical MongoDB Aggregations - Practical MongoDB Aggregations Book (practical-mongodb-aggregations.com)
Blog ของท่านอื่นๆ
Resource
และก็พี่ Speaker มีเขียนหนังสือด้วยนะ Implementing CI/CD Using Azure Pipelines: Manage and automate the secure flexible deployment of applications using real-world use cases: Champeethong, Piti, Mardeni, Roberto //ส่วนเรารอของเดิมหมดก่อนไปสักเล่มก่อน ตอนนี้ดองเยอะ
Reference
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


