
สำหรับวันนี้มี 3 หัวข้อตามนี้ครับ รอบนี้มาช้าหน่อย วุ่นวายกับงานประจำ และขอย่อยก่อน เดี๋ยวมืนเอง
และมี มีเวอร์ชันเต็มๆใน Live ด้วยครับ เผื่อผมจดขาดไปครับ
Architecture as Algorithm
- Software Architecture คือ อะไร ?

set of structure needed to be reason about the system - อะไรสักอย่าง (Set of Structure) ที่มีอธิบายตัวระบบ
- set of structure จะมีตัว Software Element / Relation / Properties
- system ตัว computing System ซึ่งตัว Compute > Computation มีนิยามดังนี้
A Computation is a process that obeys finitely decribable rules
Rudy Rucker
Rule กฏที่เรากำหนด ถ้าในงานเราเป็น Business Rule นะ โดยที่ Speaker ยกตัวอย่างง่ายๆ การ +1
- ถ้ามีกฏเดียว อาจจะเจอปัญหาว่า Infinite Loop ได้
- ทางแก้เพิ่ม Boundary เข้าไป
ถ้าเราสังเกตุดีพบว่า finitely describable rules มันอยู่ในรูป A --(Process)--> B แล้วการทำงานของมันมี Cost นะ ซึ่งผลที่ได้มันขึ้นกับว่า
- A อยู่ในรูปไหน เป็น Input / Information
- B ต้องการแบบไหน
- และใช้วิธีการ (Process) อย่างไร ซึ่งจะได้ Cost ที่แตกต่างกัน เช่น ดัดหินตรงๆ กับ การค่อยๆงัดหินให้ขยับ Cost ต่างกัน
และนั้นแหละครับ Cost ของ Computation ที่เป็นส่วนนึงของ Software Architecture มัน คือ Algorithm มีศัพท์ Computation Complexity ตัว Big O ที่เราคุ้นเคยกัน โดยที่
- Algorithm ต่างๆ ถ้า Input/ Information มากขึ้นเรื่อยๆ Big O จะมีความแตกต่างกันอย่างชัดเจน
- ภาษาที่ใช้ Implement ต่างกัน (Efficiency) ใช้ภาษาที่ช้า แต่ โที่ดีกว่า ทำ Cost ได้น้อยกว่าภาษาที่เร็ว แต่ Algorithm แย่ๆได้
//เหมือนมาเลือก Trade Off เลย
จริงๆแล้วทุกอย่างมันไปให้อยู่ในรูป A - action-> B หมดเลย Software Architecture ลึกมันก็เป็น Algorithm นี้แหละ
Information > Process(Algorithm) > Output Request > Software Architecture > Response
- Logical Structure
Logical Structure - สิ่งใดๆที่เราสามารถให้เหตุผล (Reason) และบอกลำดับขั้นตอน (Computation - Algorithm) โดย Logic คือ อะไรที่เป็น T/F ได้ ยกตัวอย่าง เช่น จากจุด
- ถ้ามี 2 จุด เราได้ Direction
- ถ้ามีจุดหลายอัน และมีเส้นทาง จะได้เป็น Chain
- ถ้ามีจุดหลายอัน แต่เส้นทางพุ่งเข้ามาที่จุดเดียว จะเป็น Aggregator และน่าจะเป็นจุดที่เกิด bottleneck
- หรือกลับกัน มีจุดเดียว แต่กระจายออกไปหลายจุด จะได้ Distributor
ลองกับมาที่ภาพของ Software Architecture แทนจุดด้วยของ Resource บางตัวลงไป เช่น Container / DB ใช่แล้ว มันจะได้เป็น Logical Structure ที่ให้เห็นว่าตอนนี้ระบบมันทำอะไร >> set of structure needed to be reason about the system
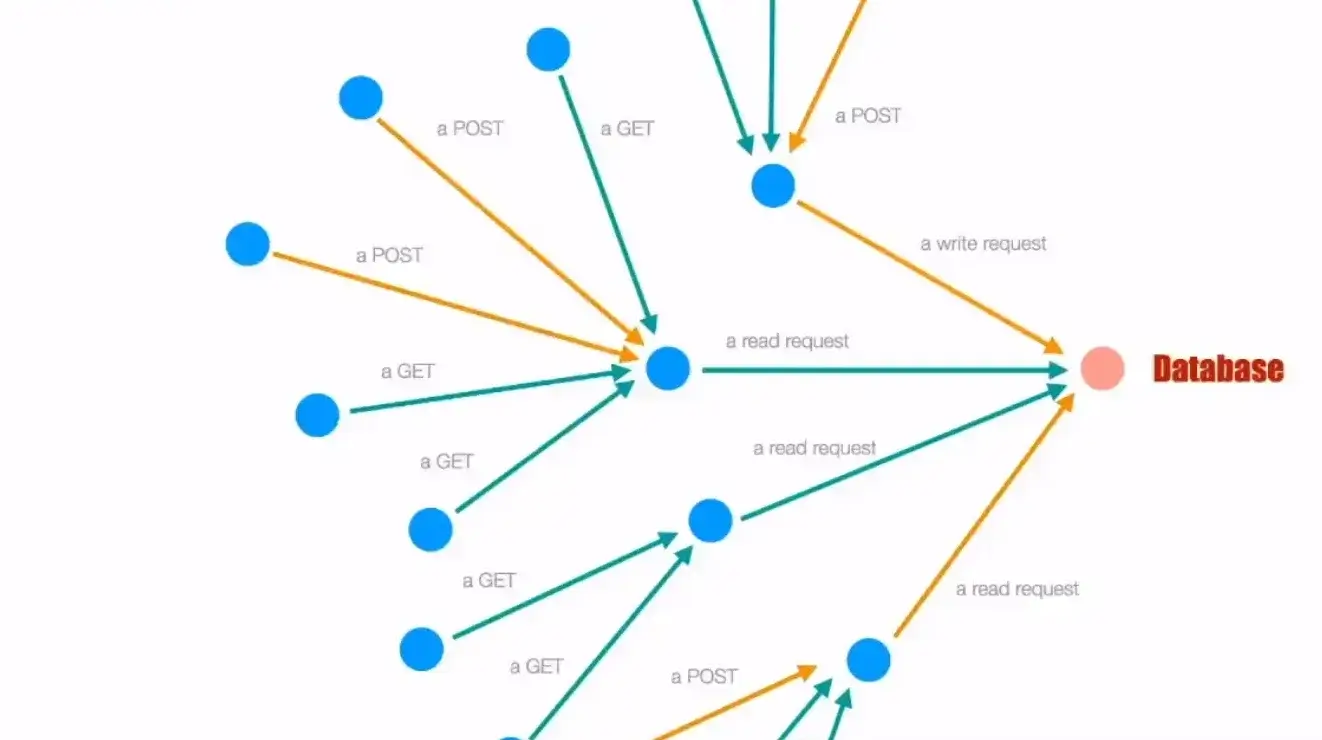
แต่ปัญหา เรามักคิดที่ละเส้น ทำให้ไม่รู้ว่า Cost จริงที่ใช้เท่าไหร่ เกิดปัญหา Performance ตามมาเก็บต้น ถ้าเราเก็บภาพรวม เห็นความสัมพันธ์ สามารถ Optimize ได้ถูกต้อง
แม้ว่าวิธีการเดียว แต่ Input ใหญ่ขึ้น มันช้าลงได้เหมือนกัน ยกตัวอย่าง ถ้าเรารู้ Input แต่ละเส้น เราสามารถ optimize ได้ เช่น
Logical Structure แบบแรก concat > filter > map แบบนี้ หลัง Concat N มันใหญ่ขึ้น ทำให้ใช้ Cost ตอน Filter กับ Map มากขึ้น แบบสอง filter > map > concat ** แต่การทำแบบนี้ได้ ต้อง Proof ก่อนนะว่ามันไม่กระทบกัน
- สุดท้ายแล้ว

Optimizing Systems: Linking Theory of Constraints, Queueing Theory and Reaction Design Pattern
- Theory of Constraints
มันการเข้าใจข้อจำกัด โดยตัวอย่างของเรื่องนี้ การเทน้ำออกจากขวด A (น้ำอยู่ในขวด) -- วิธีการ (Algirothm) --> B (น้ำออกไว) โดยที่เราห้ามทำลายขวด นัันแสดงว่ามีปากขวด เป็น bottleneck
ถ้ามองในมุมของ Software ระบบ Consume งานได้น้อยกว่า Request ที่ยิงเข้ามาครับ ซึ่งถ้ากลับไปในเรื่องปัญหาเทน้ำออกจากขวด เราต้องมาหาวิธีการเทปกติ > หมุนขวดให้อากาศเข้าไปแทนที่ และสุดท้ายใช้หลอดเป็นตัวน้ำอากาศแทน (Optimize)
การเกิด bottleneck แสดงว่ามีการรอ หรือมี Queue เกิดขึ้นมานั้นเอง โดยที่การมี Queue ไม่ได้เลวร้าย ถ้ามีการจัดการที่ดี
- มี Queue ดี เพราะ ถ้ารวบแล้ว ทำให้ compute คุ้มค่า อารมณ์เหมือน เรารวบอาหารตามสั่งในรอบนั้นๆ ทำด้วยกัน
- แต่ถ้าใหญ่ไป หรือ จัดการไม่ดีพอ และ availability ลดลง เคสนี้จะอารมณ์แนวๆ ถ้าคนทำงานเครียดกดดัน งานมันจะไม่ดี สั่งข้าวผัดไป อาจจะได้อย่างอื่นแทน หรือ ถูกลืมไปเลยว่าสั่งข้าวไว้
5 Steps of Theory of Constraints
- Identify Constraint - จากภาพรวม อะไรที่เป็นคอขวด
- Exploit the Constraint - จุดที่เป็นคอขวด มันใช้ resource คุ้มยัง ไม่มี idle //เอออันนี้เป็นจุดที่คิดเลย เพราะส่วนตัวเคยดูระบบใน Grafana คิดว่า Resource ไปพอ แต่อยู่ในช่วง Idle ยาวๆ เลยตัดสินไปไล่งม Code แทน
- Subordinate and Synchronize to Constraint - ทำให้ smooth ไม่ใช้เพิ่มงาน และให้ Task งานมันสอดคล้องกัน
- Elevate the Performance of the Constraint - debottleneck ที่พลาดกัน ส่วนใหญ่ จะทำตรงนี้เลย เช่น เอาคนไปเพิ่ม หรือ เร่งงาน แต่ไม่รู้ว่าปัญหาจริงๆ คือ อะไร
- Repeat the process - ทำซ้ำ เพราะแก้จุดนี้แล้วง bottleneck มันจะย้ายจุดไป แต่การปรับ ต้องมองย้อนกลับมาด้วยนะ ไม่งั้นปรับแบบอุดเรื่อรั่ว
เอามา Theory of Constraints ทำอะไร
- ปรับ process การทำงาน
- Performamcd Tuning (SW) กลับไปมองภาพรวมนะ การทำ local optimze เข้าทำ process แล้วไปเกิดก่อน queue ใหญ่ๆตอน write
Key takeaway: ดูภาพรวมก่อน optimize ควรเสริมภาพรวม อย่าทำ local optimize
- Queueing Theory
เอามาตอบ queue length / waiting time / utilization / service rate มาทำให้ตัวระบบมันได้ Throughput ที่ดีที่สุด
เดิมๆ มันจะอยากรู้ว่ารับได้แต่ไหน ทำโดย
- สุ่ม - ปกติส่วนใหญ่เราเองใช้วิธีกันนนะ ตัวผมเอง ได้เลขจากที่ A ไปเอา reference B เลย 555
- Full Load test
- Formal Model + sample (sampling) test
ถ้ามองทั่วไปๆ เราจะวัด Capacity ได้จาก
- Little Law เคยได้ยินจากพวกร้านอาหาร หรือ สายโรงงาน ผมเพิ่งรู้ว่าามันเอาทำใช้กับ Software ได้ด้วยนะ สูตรสั้นมาก L=λW
L=λW L = จำนวนของ Request ใน Queue >> ต้องนี้ประมาณได้ ว่าต้องรอควรมี Buffer เท่าไหร่ ไม่ให้มันน่าเกลียดรอนาน และต้องมาจูนให้ ดีทุกฝ่าย Cost Effective λ = จำนวน Request ที่รับได้ ณ ช่วงเวลาหนึ่งๆ เช่น 5000 Req / Sec = 5000 / 60 = 83.33 W = เวลาจัดการ Request (response time)
- Wait time - เวลารอในการทำ Task ที่ดีควรจะการ Wait time น้อยๆ
ตัวอย่างที่ Speaker ยกขึ้นมาจะเป็นระบบ LMAX ที่ลดตรงนี้ แล้วทำงาน Single Thread ได้อย่างประสิทธิภาพ

รูปแบบของ Task - Sequence / Parallel การทำให้เร็วขึ้นจะมี
- Linear Scalability - เพิ่ม Resource เพิ่มเครื่อง โดยคาดว่า Throughput x ตามจำนวน Resource ที่อัด แต่จริงๆมันมีข้อจำกัด Task - Sequence / Parallel
- Amdahl's law - การเพิ่มเครื่อง/Node ไม่ได้ ให้ผลลัพธ์แบบ Linear Scalability มันมีปัจจัยจาก Network รวมถึงงานด้วย จะมีงานบางอันมัน Parallel ไม่ได้ หรือ ง่านที่ Parallel มี Dependency ต่อกัน
ปัญหาของ Amdahl's law ถ้ามี Node เยอะๆ จะเกิดเส้นในการสื่อสารมากมาย (Brooks’s Law) ทำให้เกิดเรื่อง Coherency Delay. - Universal Scalability Law - มาแก้เรื่อง Coherency Delay โดยตัวอย่างการ Apply จะเป็น Logic ของ Load Balancer
พวกสูตรไปดูใน Slide ครับ ธาตุไฟเข้าแทรกกกกก 🔥
ถ้าวัดได้ เราจะพบปัญหาที่ต้องจัดการ 2 กลุ่ม จากสูตรทั้งหมดมา
- งานที่ parallel ไม่ได้ ลดเวลา ปรับ algo
- งานที่ parallel ลด Coordination ได้ไหม CALM Theorem
แล้วเอา Queueing Theory มาใช้ร่วมกับ Theory of Constraints ?
เอามาใช้ในช่วงตอน Identify Constraint ได้ Constraint มาใช้สูตรของ Queueing Theory ในตอน Exploit the Constraint แล้วมา Optimize
รู้พวกนี้มา Apply กันยังไง
- Capacity Planning จาก Little Law
- Max Waittime
- SLA with Buffer - เผื่อแบบมีหลักการ
- Total Cost Optimzation หาคุ้นทุนใส่ของแต่ละ Solution เมื่อเทียบกับ waittime และ cost
- Reactive Design Pattern
Build for Resilience - Design for Failure + Recover เป็นท่าที่ใช้รับมือกับปัญหาต่างๆ หลาย Keyword เรารู้อยู่แล้วนะ เช่น timeout โดยมันมีหลายท่าตามใน ฺ
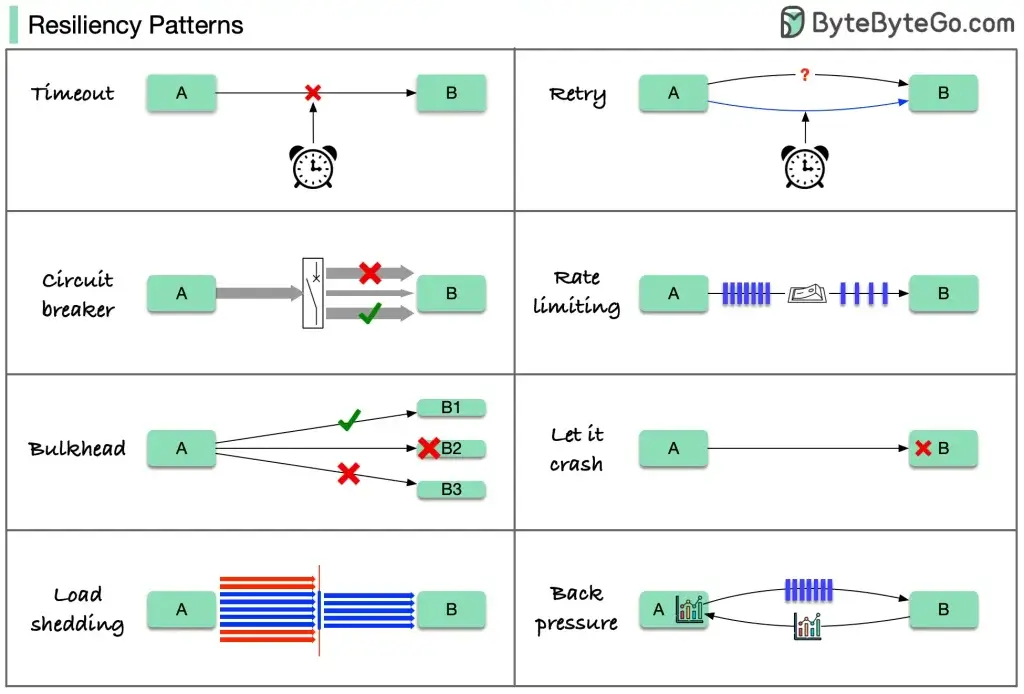
Focus ที่ตัว Backpressure บอกต้นทางให้พอก่อน โดยมีท่า
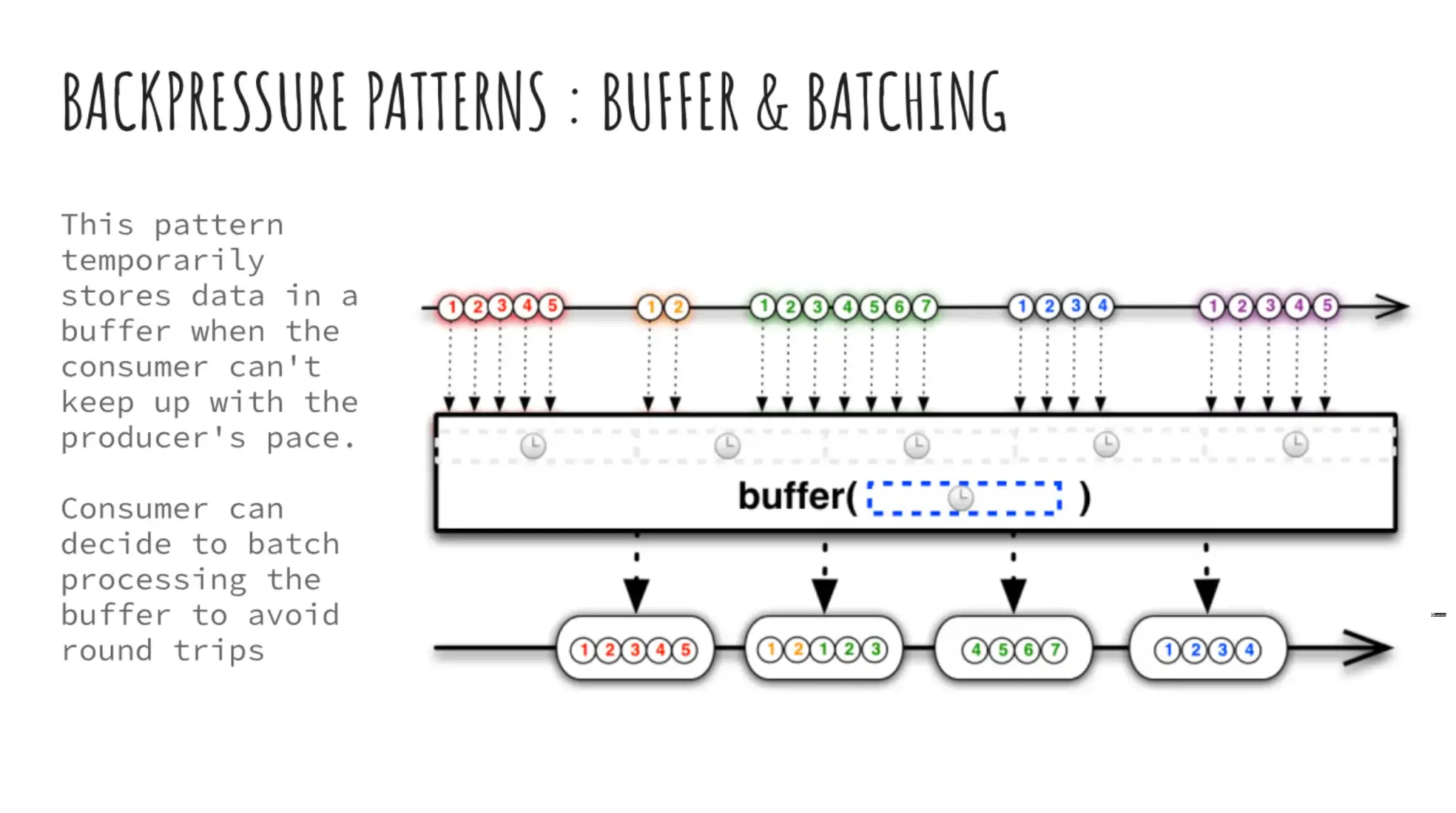
- Buffer + Batching คิว และตัดเป็นรอบๆ
- Load Shedding & Dropping ทำเท่าที่ได้ ที่เกินให้ไปลองใหม่
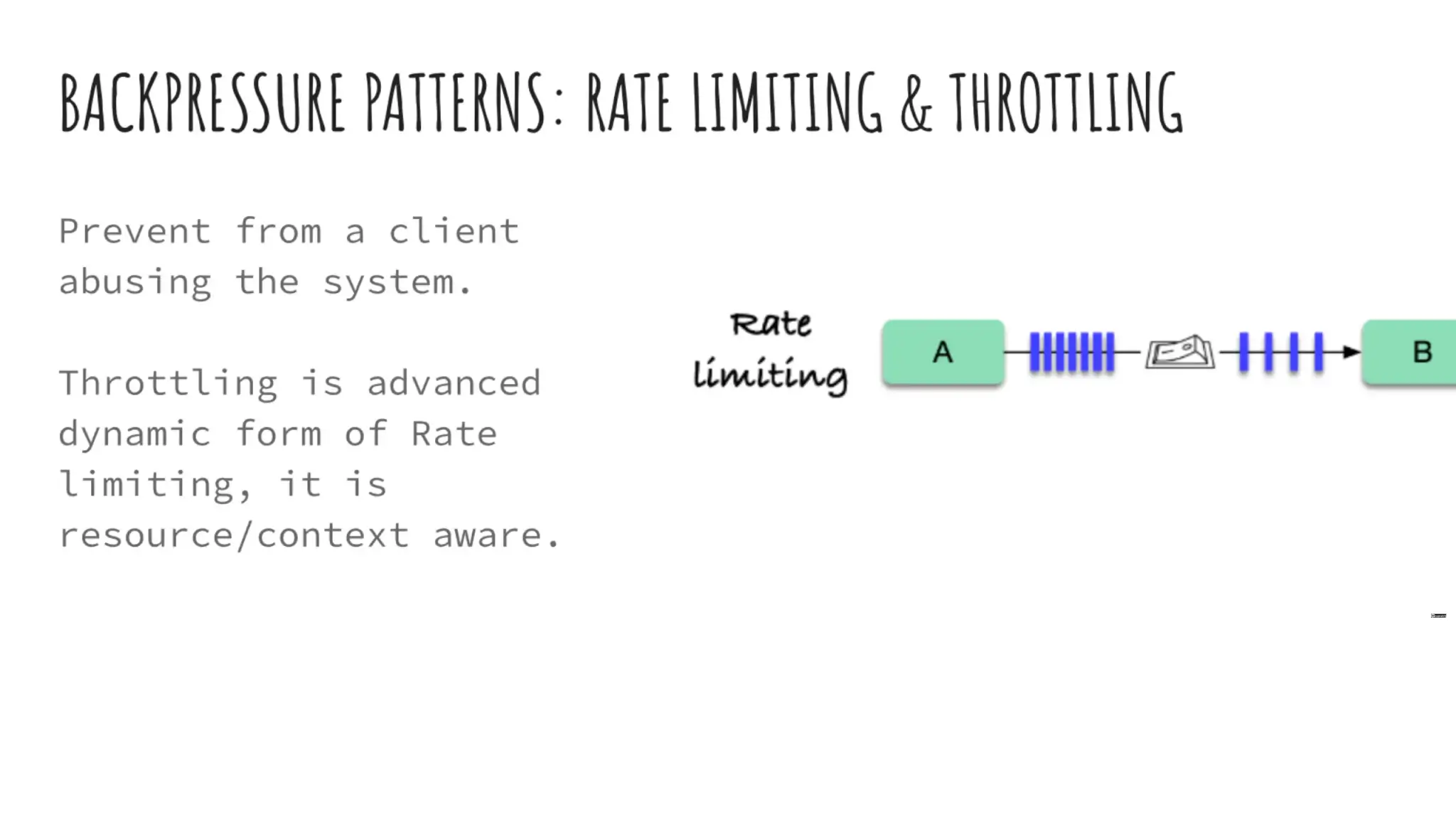
- Rate limiting & Throttling
- Reactive Pull System - ดึงงานไปทำ kakfa > consumer group
- Priority queue
- Adaptive Sampling งานที่ไม่ได้ต้องการความละเอียด เช่น ระยะทางจาก A -> B เราอาจจะไม่ได้ต้องการทุกจุด อีกอันที่นึกได้พวกงาน Observability เคยเห็น Config ที่ให้ Sampling Metric / Trace ส่งออกไปนะ ไม่งั้นมันจะเยอะมา

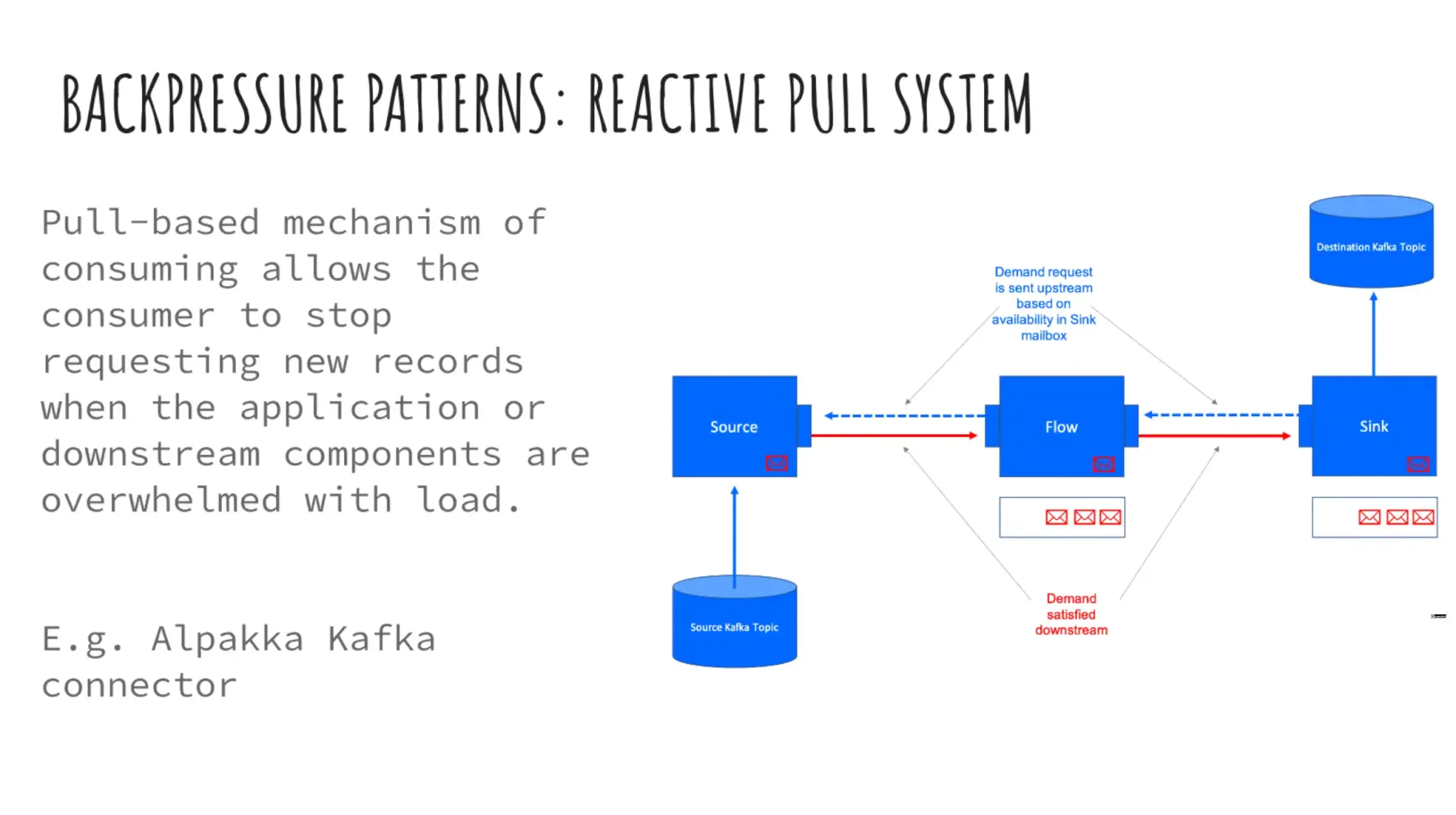
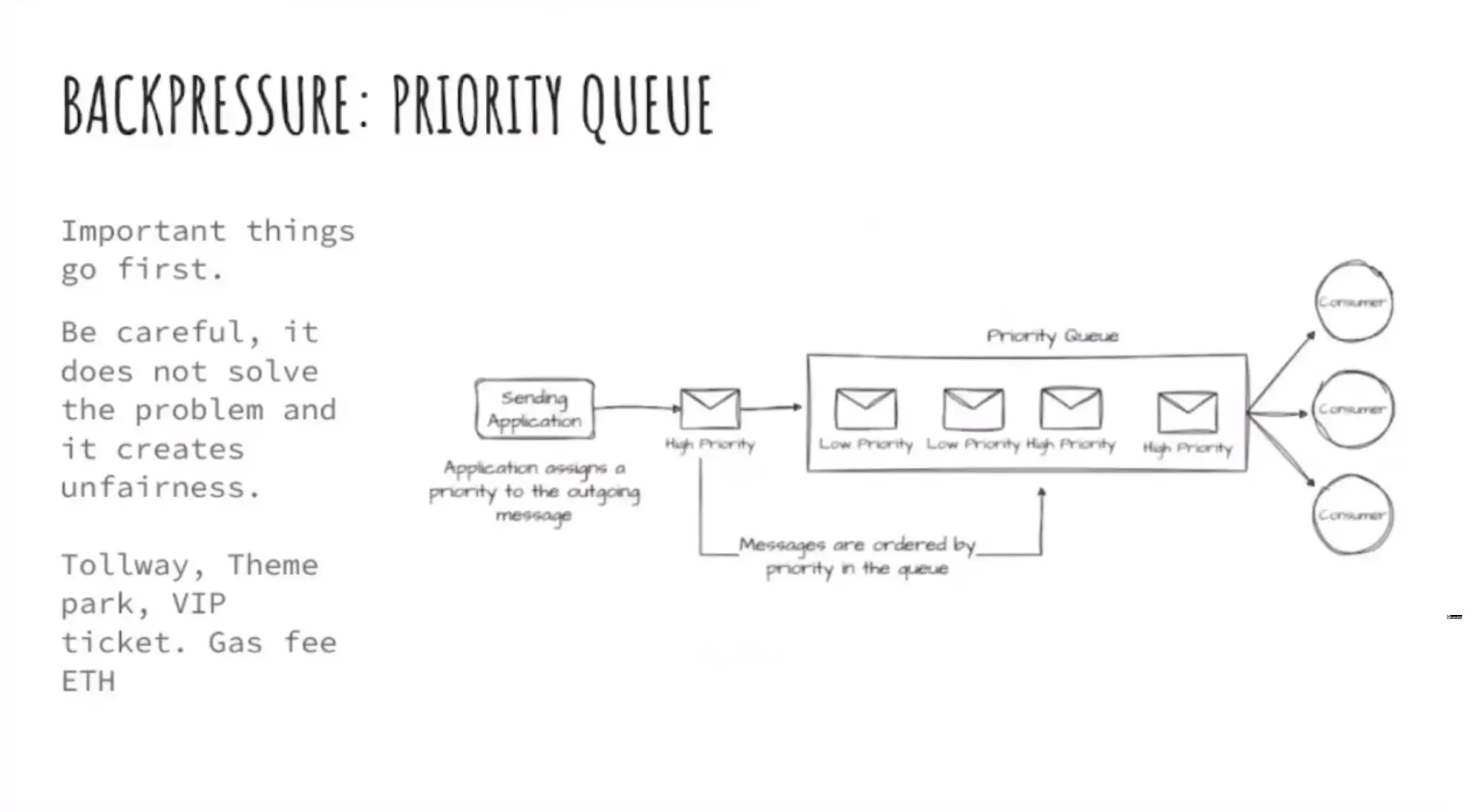
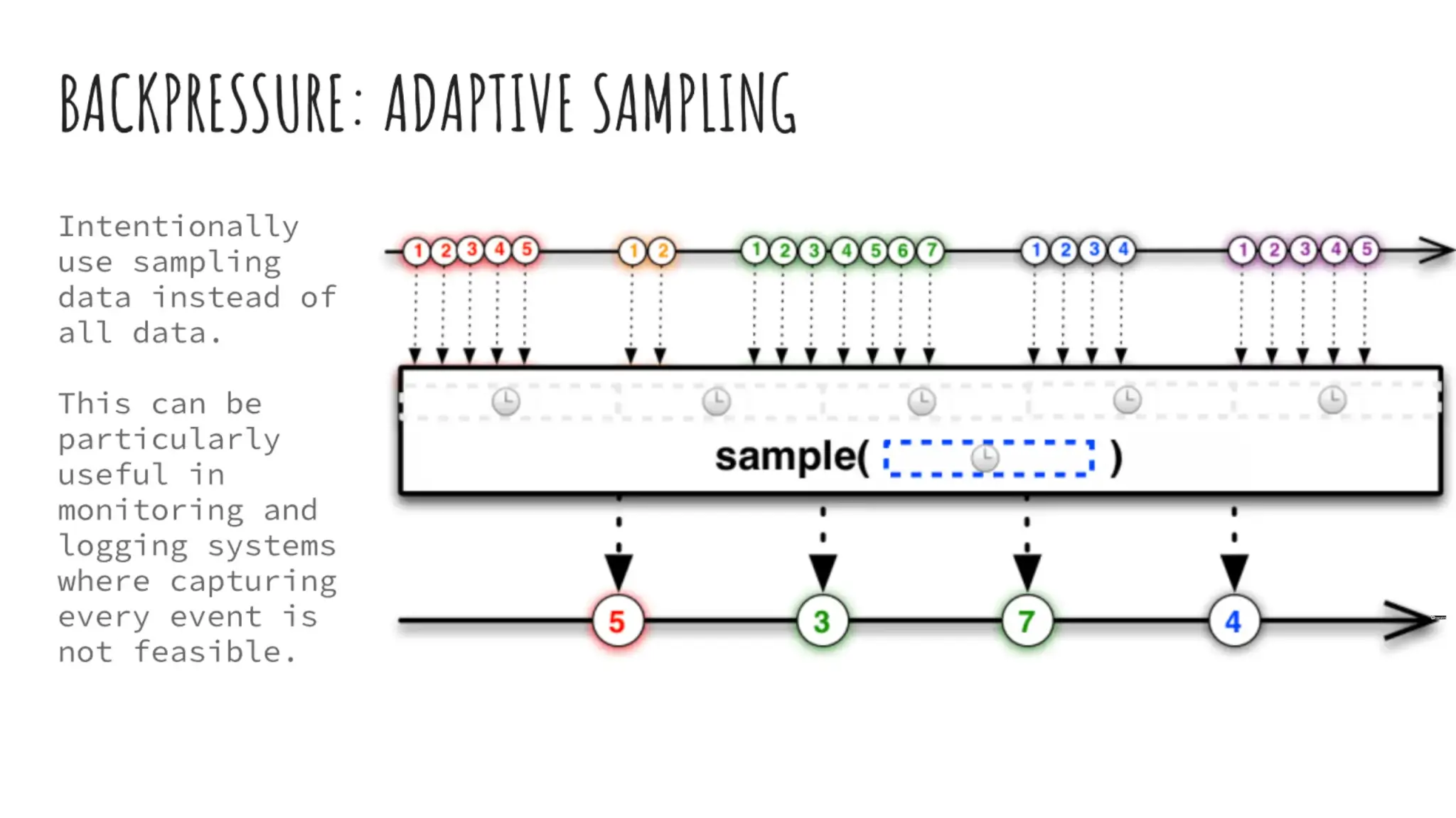
- Step การ Apply จะเป็น Hypothesis Base
- กำหนดว่าเราต้องการจะแก้อะไร Latency / Throughput หรืออื่นๆ
- หา Baseline ของระบบเดิมก่อน (AS-IS)
- Identify Problem เช่น Bottleneck
Note: อาจจะเอา Queueing Theory มาช่วยแก้ Model ปัญหา และใช้ Math (สยองงง) //ส่วนตัวไม่ชอบ Math - Create Hypothesis
- เอา Reactive Design Pattern มาใช้แก้ปัญหา
- Repeat และ Measure
Resource: Slide
Ask us anything on Software Architecture (Panel Discussion)
- คำถาม: AI กับ Software Architecture?
ความเห็นไปในทางเดียวกัน ใช้ AI ได้ แต่เราควรรู้ว่าสิ่งมันคิดออกมา คิดมายังไง นั้นแสดงว่าตัวเราเอง Fundamental ต้องแม่นระดับนึง และดูภาพรวมให้ออก บางที AI อาจจะไม่เข้าใจ logical structure (Business) คำตอบที่ AI ให้มา มันมองใน Scope เล็ก กลายเป็นการทำ Local Optimize แทนได้
อีกอันนึงที่ผมชอบ การทำ Software / Architecture มัน คือ การเลือก Trade-Off จาก Solution-Space ซึ่ง ถ้าอันไหน Pattern ตายตัว AI อาจจะช่วยได้ แต่คนใช้ต้องเอามาปรับเข้าปรับบริบท และดูภาพรวมด้วย
- คำถาม: แนะนำหนังสือที่ควรอ่าน
- Software Architecture: The Hard Parts: Modern Trade-Off Analyses for Distributed Architectures
- The Software Architect Elevator: Redefining the Architect's Role in the Digital Enterprise - จัดการกับคน และ Relation
- Documenting Software Architectures: Views and Beyond
- Just Enough Software Architecture
- Introduction to Algorithms (CLRS - มี Wiki เลยแฮะ)
- คำถาม มีแนวทางการสังเกตุว่า ที่เราออกแบบ Over-Engineer ไหม รู้ก่อนปรับตัวทัน
- คิดตาม Scale ที่ฝั่ง Business คาดการณ์ได้ก่อน รู้จักตัวเองก่อน ไม่งั้นจะ Design ด้วยความกังวล กลัว เช่น ตอนนี้ยังไม่มี User ไม่ต้องคิดเคสที่โอเวอร์ไประดับล้าน สิบล้าน จะได้ไม่ Over-Engineer
- อีกคำได้ควรระวัง Under Engineer ถ้าเราไม่รู้จักระบบที่เราออกแบบดีพอ อันนี้ผมเข้าใจว่าไปในมุมของ Observability แล้วหาทาง Improve มันนะ
- Over-Engineer หรือไม่ให้ดูว่าจริงๆ มันมี Solution อื่นๆที่ Simplify กว่า แต่เราหาเหตุผลมาแย้งไม่ได้ ตามบริบทที่มี เช่น ทำระบบ HA 99.99 แต่ฝั่ง Business บอกว่าเรารอได้ และระบบภายในของพนักงาน เป็นต้น
- Solution ที่เราออกมามัน มันทำให้รู้สึก Cognitive load ไปไหม เพราะ การทำ Software > Software Architecture มันทำมาเพื่อลดความซับซ้อนของปัญหา แสดงของที่จำป็น ให้เข้าใจได้ง่าย จุด A > B ถ้าสร้างมา Complex มาก หรือ Over ไป อาจจะมีคำถามขึ้นมาได้ ว่ามีมาเพื่ออะไร แนวๆนี้ ที่ผมเข้าใจนะ
- อีกมุมนึงว่าตัว Software ที่เราออกมา มันตรงกับการทำงานที่ลูกค้าอยากได้ไหม มันจะมีกฏนึง Conway's Law (martinfowler.com) ที่บอกตัว Software มันสะท้อนให้เห็นถึงรูปแบบขององค์กร ว่ามันซับซ้อน หรือป่าว
- Badly-Engineer เสนอมาอีกคำนอกจาก Over-Engineer / Under-Engineer โดยที่ตัว Badly-Engineer นอกจาก Solution ที่ทำมาซับซ้อน แล้วมันยังไม่ได้ประโยชน์ด้วย แถมเสีย Effort เพิ่มอีก เช่น ระบบง่ายๆ แต่เล่นท่ายากขึ้นทุกตัวเป็น Microservice ทั้งที่มีคนทำคนเดียว ประมาณนี้
เรื่องอันนี้เหมือนเจอ Blog ของพี่ปุ้ยด้วย แปะไว้สักหน่อย มีอะไรบ้างที่ Under-engineering และ Over-engineering ในการพัฒนาระบบงาน (somkiat.cc)
- คำถาม เราจะทำอย่างไร หรือมี Process อะไรที่ช่วยให้ส่งต่อได้ว่าทำไมคน/ทีมก่อนหน้า ถึงได้ออกแบบมาแบบนี้
//คำถามผมเอง ขอโทษที่ทำให้คนในงานงงครับ
- ทำเอกสาร ADR (Architecture Decision Record) เพื่อมาจดบันทึกการเปลี่ยนผ่าน ว่าทำไมถึงต้องทำแบบนั้น แต่ทว่าส่วนใหญ่พอเอกสารนี้เป็นเอกสารที่ใช้ภายใน เราเลยละเลยกัน จนกลายเป็น Common Mistake
- การเปลี่ยน Architecture จาก A > B ควรมี
- Metric มาชี้ว่าเปลี่ยนไปแล้ว เราได้อะไรมันแก้ปัญหาที่เราต้องการไหม เช่น ลด Time เพิ่ม Throughput ระหว่างทำมันตรงตามเป้าไหม ?
- การเปลี่ยนใช้วิธีการแบบไหน ยกทั้งหมดออกไป หรือ เปลี่ยนที่ละส่วน
- นอกจาก Technical แล้ว มาต้องจัดการทีมปัญหาของคน มองให้เป็น Product not project จะอยู่พัฒนาไป และการจัด Build Team หรือ คน ถ้าจัดการไม่ดีคนออกไปเละเลย กลายเป็นการสร้างทีมใหม่ ผมฟังแล้วนึกถึง Bus Factor
- คำถาม สื่อสารยังไงให้ทุกคนเข้าใจปัญหา และTrade-Off ของแต่ละ Solution ตรงกัน
- ใช้ UX ดัน ให้ทุกฝ่ายเห็นภาพไปทางเดียวกัน
- เข้าใจตรงกัน แต่ตีความเหมือนกันไหมนะ ถ้าไม่เหมือนจะกลายเป็นว่าเห็น Gap ที่ไม่ตรงกัน แต่ต้องให้เห็นตรงกันก่อนว่าเรากำลังแก้ปัญหาอะไร
- เห็นปัญหาเข้าใจไม่ตรงกัน เป็นปัญหา ชอบคำนี้ อันนี้
- Stakeholder (Business / Tech) ต้องเห็นตรงกันไปในทางเดียวกันก่อน
- คนอาจจะเข้าใจ Trade-Off ได้ไม่ตรงกัน ต้องจูนอธิบายในภาษาเดียวกัน แต่ทุกคนต้องตัดสินใจแก้ปัญหาไปในทางเดียวกัน - ปัญหาที่หลายองค์กรจะเจอกันอีกอัน ทุกคนอยู่ใน Silo ของตัวเอง ทำให้มองภาพเล็ก ไม่ได้มองภาพใหญ่่ของปัญหาที่กำลังจะแก้
- อีกมุมที่เจอ ไม่เข้าใจ != ไม่ยอมรับ วิธีการแก้ปัญหาจะจะต่างกัน
Live
ถ้าสนใจ Blog สรุปต่างๆ ลองมา Subscribe กันได้ครับ เดี๋ยวจะมีเมล์จาก [email protected] มาให้กด Confirm อีกทีครับ
Reference
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


