
งานนี้จัดที่ Justco สามย่านมิตรทาวน์ ตอนแรกหลงด้วย ไม่รู้ว่าทางขึ้นสำนักงานไปทางไหน 5555 หัวข้อมี 3 Session ดังนี้
Table of Contents
Session 1 - Enhance your observability systems with OpenTelemetry
Speaker Mongkol Thongkralkaew
- What Observability ?
การทำให้เราเข้าใจ App / ระบบ หรือ Infra ที่เราสนใจ โดยมี Signal 3 แบบได้แก่ Log / Trace / Metric
- Logs - What is happening?
- มีอะไรเกิดขึ้นจาก อะไรบ้าง - Traces - Where is it happening?
- เกิดที่ไหน จุดไหน และมี Flow อย่างไร - Metrics - Size/Measure of Something ?
- ทำกี่รอบ มี user ในระบบกี่คน
- Why observability ?
- ทำให้เข้าใจ Business Flow / Workflow ของการทำของ System ต่างๆ หรือจะมาย่อยเป็นตัว Microservice
- รู้ว่าจุดไหนที่เกิดปัญหา ใน Flow
- เห็นสถานะของ Microservice
- เห็นว่า Microservice ควรจะ Improve ให้ดีขึ้น เพื่อไม่ให้เกิดปัญหาได้
- เอามาใช้ตัดสินใจว่าวางแผนได้
- proactive monitor
- What is OpenTelemetry
- มาจาก OpenTracing + OpenCensus มาทำ Standard กลางของ Observability เรื่องจาก tracing ก่อน
- Goal มำให้มี api sdk กลางของแต่ละภาษา
SDK: Language APIs & SDKs | OpenTelemetry - ตอนนี้ OpenTelemetry อยู่ในสถานะ General Availability ในงาน kubecon nov 2023 ทั้ง log trace metric
- OpenTelemetry Component
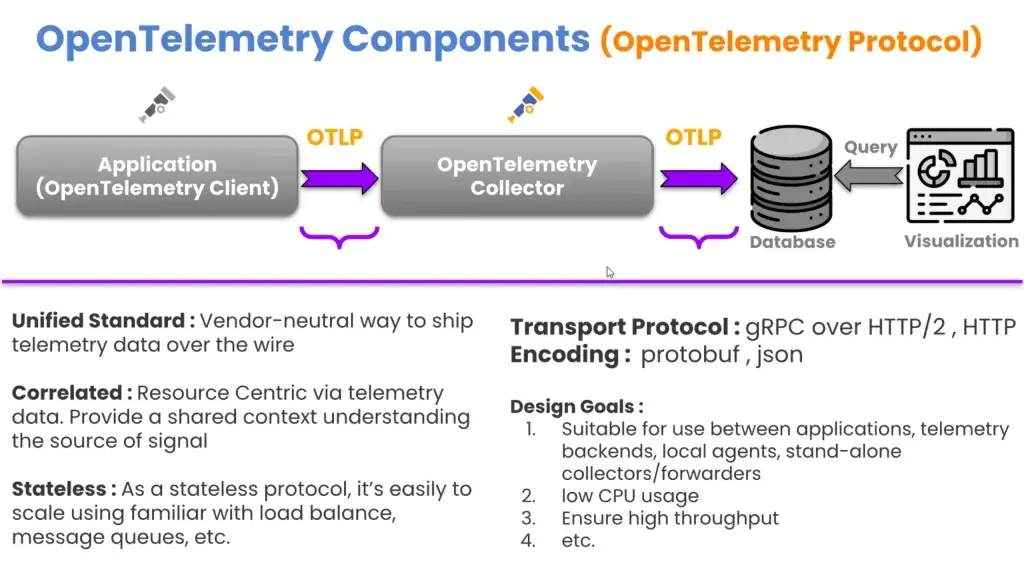
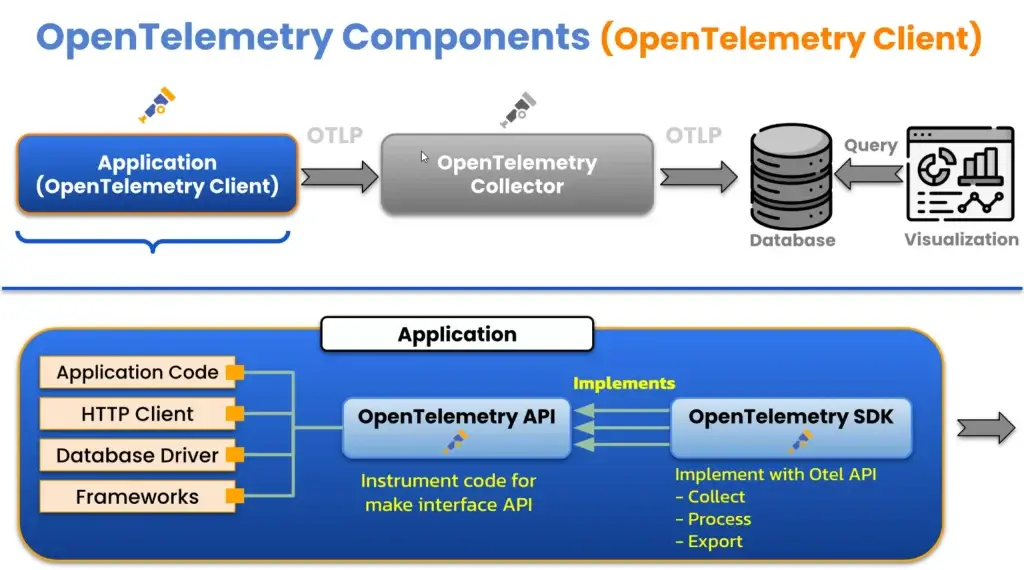
- Client อยู่กับตัว source ของ signal app / os ต่างๆ ตอนนี้ตัว OpenTelemetry มี SDK มาให้แล้ว มาทำให้ส่วน Instrumentation (ทำให้มี signal ออกมา) โดยมี 2 ท่า
- Auto Instrumentation - No Code เอาไปแปะปุ๊บได้ signal ออกมาเลย
- Manaul Instrumentation - เขียน Code บอก - Collector เก็บ Signal ต่างๆ มาจาก Client โดยมี 3 Step
- receiver - รับข้อมูลจาก Client ใน mode push/pull
- processor - pre-process signal เช่น ใส่ Label / Tag / Sampling
- exportor - แปลงจาก Format กลางของ OpenTelemetry ไปในส่วนของแต่ละ DB ที่ต้องการใช้งาน ในแบบ push/pull
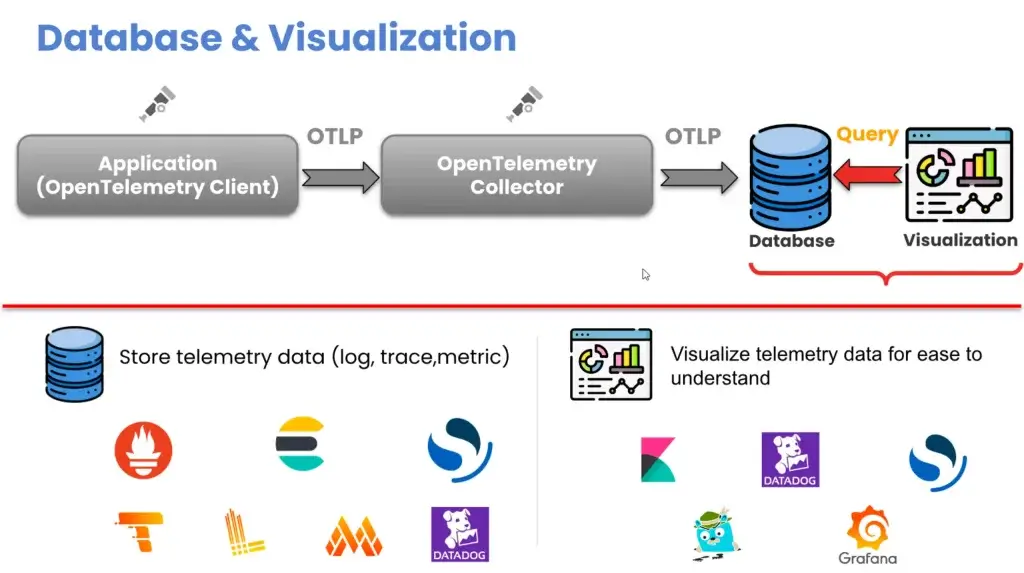
Tools: OTelBin – by Dash0 ตัว Visualize Config ของ Otel Collector ตอนแรกไปวาดรูป ได้ Tools ใหม่และ - Database เก็บข้อมูลของ Signal แต่ละแบบ เช่น
- Log > Loki
- Trace > Tempo
- Metric > Mimir - Visualize - นำข้อมูลจาก Database มาทำให้เห็นภาพ Dashboard ทำให้เชื่อมโยงกัน จากเวลาที่สนใจ มี Log / Trace / Metric อะไรบ้าง

- Adopting OpenTelemetry
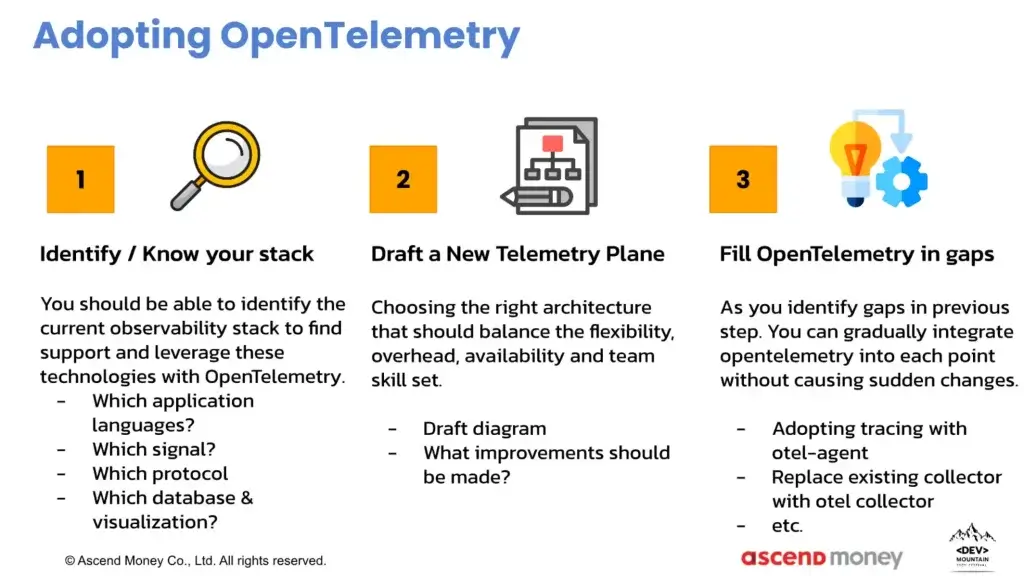
- Identify / Know You Stack
- ตอนนี้ Artitechture แบบไหน
- มี Resource อะไรบ้าง พวก App + ภ่าษาที่ใช้ Dev / DB / Queue บราๆ
- Deploy แบบไหน VM / Container Base
- Signal ตอนนี้มีอะไร ออก Log เฉยๆ - New Telemetry Plane
- เอาของที่มีจาก 1 มาดูว่าเราขาดอะไร
- ต้องการอะไร มาตอบ Business ผมมองว่าเป็นการตั้งคำถามนะ หรือปัญหาที่จะแก้ - Fill the Gaps (Solution/Improve)
- ปรับสิ่งที่ยังไม่ เช่น มี Logs แล้ว เพิ่ม Trace เข้าไปก่อน รอบถัดมาเพิ่ม Metric
- ตัว Artitechture เดิม ใช้วิธิยิงตรงจาก Serice ของ Signal นั้นๆ เช่น ตัว Jaeger Collector เราอาจจะมาปรับให้ใช้ตัว OTEL Collector แทน ลด Coupling
- Goal ของการเอา OpenTelemetry ลดการใช้ Resource เช่น CPU / Mem เพื่อให้ได้ Throughput สูงสูด
- Future of OpenTelemetry
- SDK สำหรับทุกภาษา
- Real User Monitoring
- Distribute Profiling
- Semantic Convention (gRPC / DB / Message Queue / K8S Resouce / Cloud Resource
- OpenTelemetry ขยับไปในส่วน Dev + Test มากขึ้น ในส่วนของ CI/CD
- eBPF
- Q&A
- Q: observability เก็บข้อมูลขนาดไหน แล้วควรใช้เท่าไหร่ เพื่อที่จะได้ไม่กระทบกับตัว Resource ของ APP
A: เก็บแบบ Sampling ช่วยทำให้ app smoth ถ้าเก็บพวก observability อาจจะกระทบ CPU > APP - Q: ติด observability ตอนไหนดี
A: เล่า Impact ตอนระบบ down ให้ฝุ่ง Business ว่าเเกิดแล้วรับได้ไหม จะได้มาจัด Weight + Priority ได้
Resource: Slide
Session 2 - Grafana LGTM Stack in action
Speaker Jirayut Nimsaeng
- Monitor vs Observability
- Monitor (What) เก็บช้อมูล พอเกิดปัญหาแล้ว ก็แก้มัน
- Observability (Why) เน้นไปที่การเข้าใจระบบ หา Context จาก Signal แล้วทำให้ระบบเกิด resilience ผมมองเป็น preventive
- Observability Signal
- Profiles - Metric บอกของแต่ละกลุ่มที่สนใจ เช่น CPU / Heap / GPU / IO เป็นต้น
- Dump - Logs เอาไว้แก้ปัญหา บอกว่าเกิดอะไรขึ้น
- Observability Challenge
- Volume - Metric มันเล็ก แต่ Log + Trace มันใหญ่
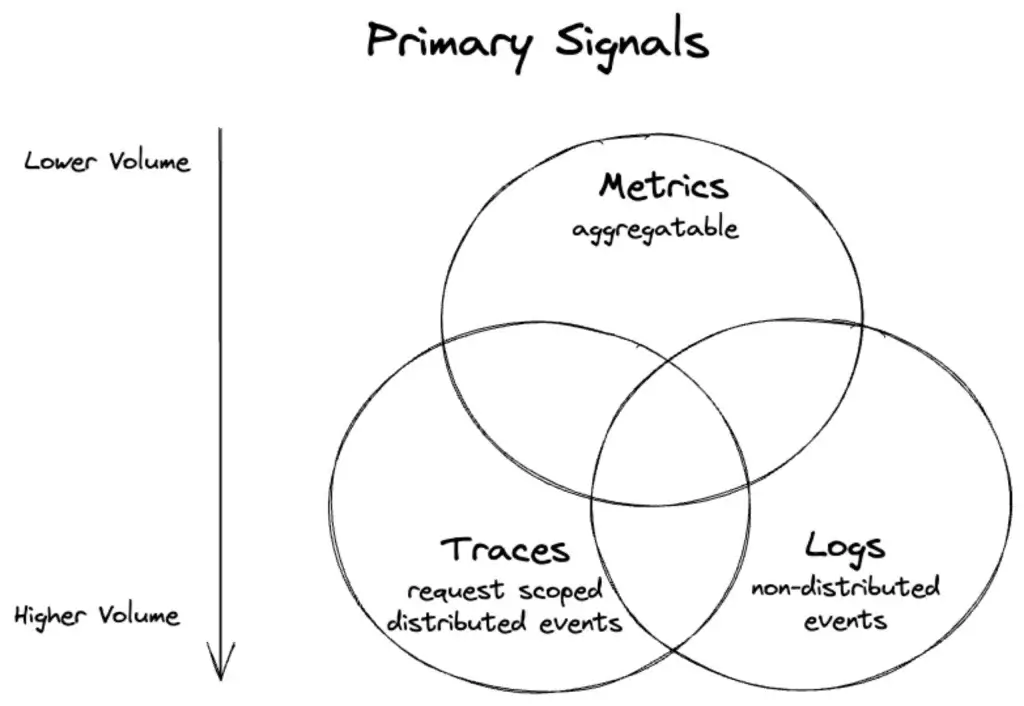
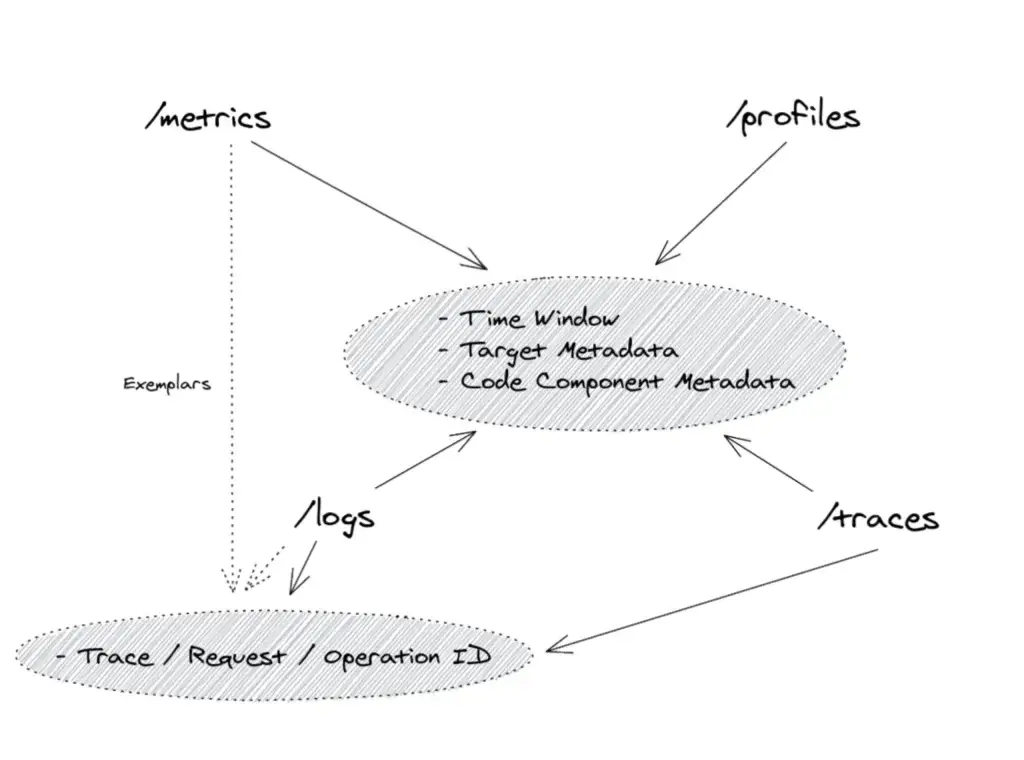
- Correlation - จาก Signal เราต้องทำให้ Log / Metric / Trace มีความหมาย ในตัวได้ ตามช่วงเวลา
- Grafana LGTM Stack
- Logs with Loki
- Grafana for Visualizations
- Tracing with Tempo
- Metrics with Mimir
ถ้าสังเกตุดูตัว Architecture
- ของ Loki / Tempo / Mimir แยกขา Read / Write ไว้ชัด ถ้าภาระงานส่วนไหนเยอะ ก็ Scale ขานั้นๆ ก็พอ
- ส่วน Grafana แบบที่มาแสดงผล แบบทั่วไป ไปจนถึงตัว HA
- Monitoring Best Practices
- USE Method - infra monitoring.
- Utilization - Rate การใช้ Resource ในเวลานั้นๆ จะอยู่ในพวก Percent เช่น การใช้งาน CPU
- Saturation - queue length เช่น งานค้างรอ CPU / IO
- Error - จำนวน Error Event - RED Method - application monitoring
- Request - Request/Sec ของตัวระบบ หรือ Microservice นั้นๆ
- Errors - จำนวน Error ของ Request/Sec ถ้ามาเยอะ 500 /404 ต้องมาส่องว่าเกิดอะไรขึ้รน
- Duration - เวลาที่แต่ละ Request ใช้งาน ถ้ามันนาน ต้อง Drill Down ลงไปดู พวก Observability Signal ในส่วนนี้
จากนั้น Demo และ เอา LGTM มาขึ้น แล้วลองเอา App ยิง Request นอกจากทาง Ops แล้ว ทาง Dev + Biz ต้องร่วมมือด้วย บางส่วน อย่าง Log / Trace / Metric ต้องมา Custom กันเอง อย่าง เช่น พวก Trace ถ้าไม่ใส่ใน Code มันจะไม่มีข้อมูลมา
- Q&A
- LGTM Stack ใช้ Storage เท่าไหร่
- บน Cloud ใช้ Object Storage เลย เพิ่มลดได้
- ถ้าต้องการวางแผนมี Tools นะ แต่มันๆไม่ Accurate //ลองหาดูน่าจะประมาณนี้
>> Loki: Size the cluster | Grafana Loki documentation
>> Mimir: Planning Grafana Mimir capacity | Grafana Mimir documentation
>> Tempo: Sizing Grafana Tempo Cluster - Grafana Tempo - Grafana Labs Community Forums - พวก Log Metric Trace เก็บนานแต่ไหน
- Log ตาม พรบ คอม
- Metric ข้อมูลมันเล็ก เก็บนานได้
- Trace ต้องดูเคส หรือ ถามทาง Business ว่าต้องการดูข้อมูลย้อนหลัง ประมาณไหน 1 สัปดาห์ แล้วเผื่อกะเอาเพิ่ม
Resource: Slide / tag-observability/whitepaper.md at main · cncf/tag-observability (github.com)
Session 3 - Observability Maturity Model (เติบโตอย่างแข็งแรงกับ Observability)
Speaker Warach Wongpairoj
ชอบเกมก่อนเริ่ม Session ลองให้เห็นภาพไปเลย ว่า break my app สร้าง request มาให้พัง แล้วข้อมุล โผล่บน data dogแอบโหด เก็บ user behaviour ว่ากดตรงไหน ของจอบ้าง / ข้อมูลมัน Link กันมาเลย
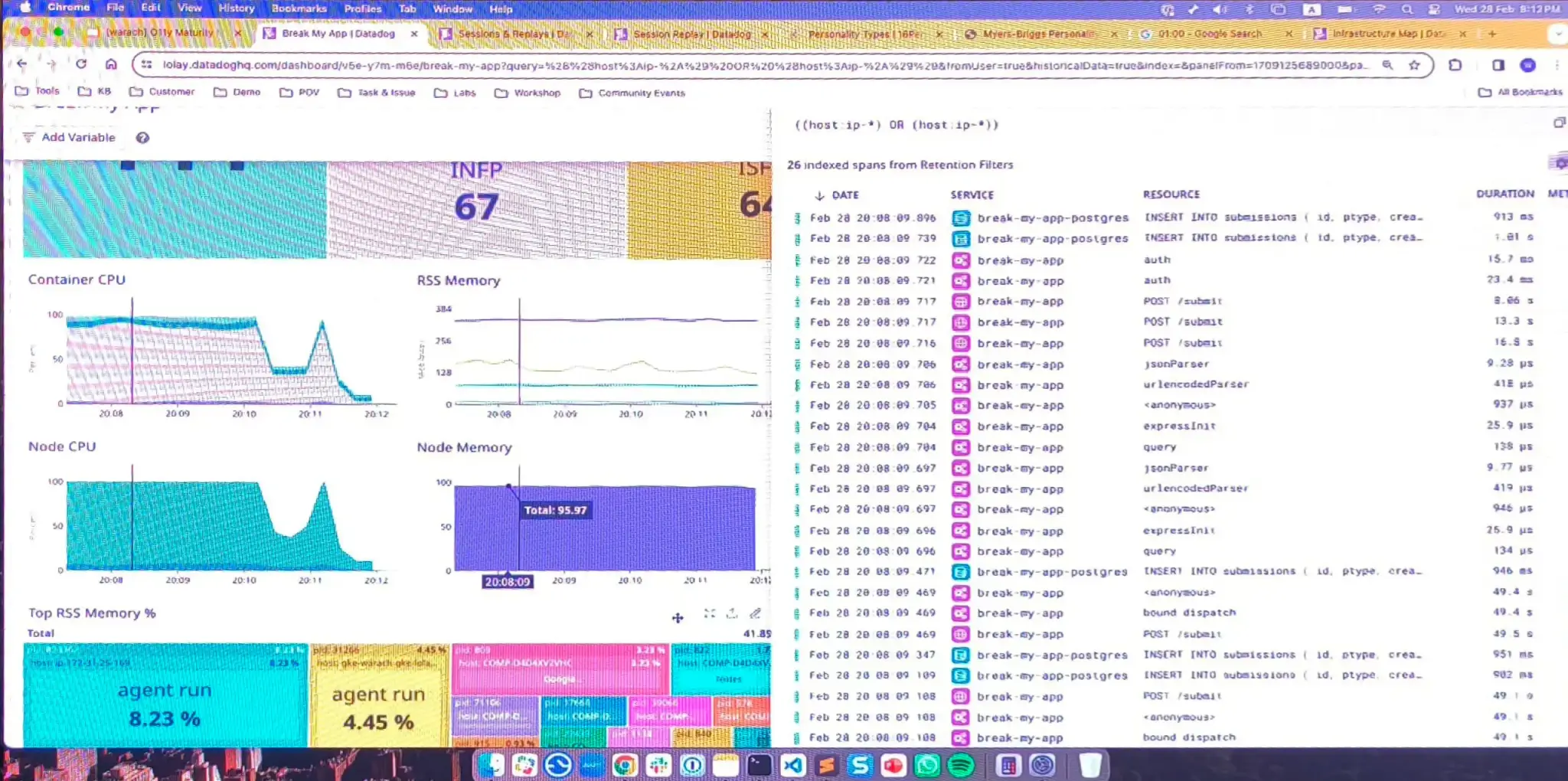
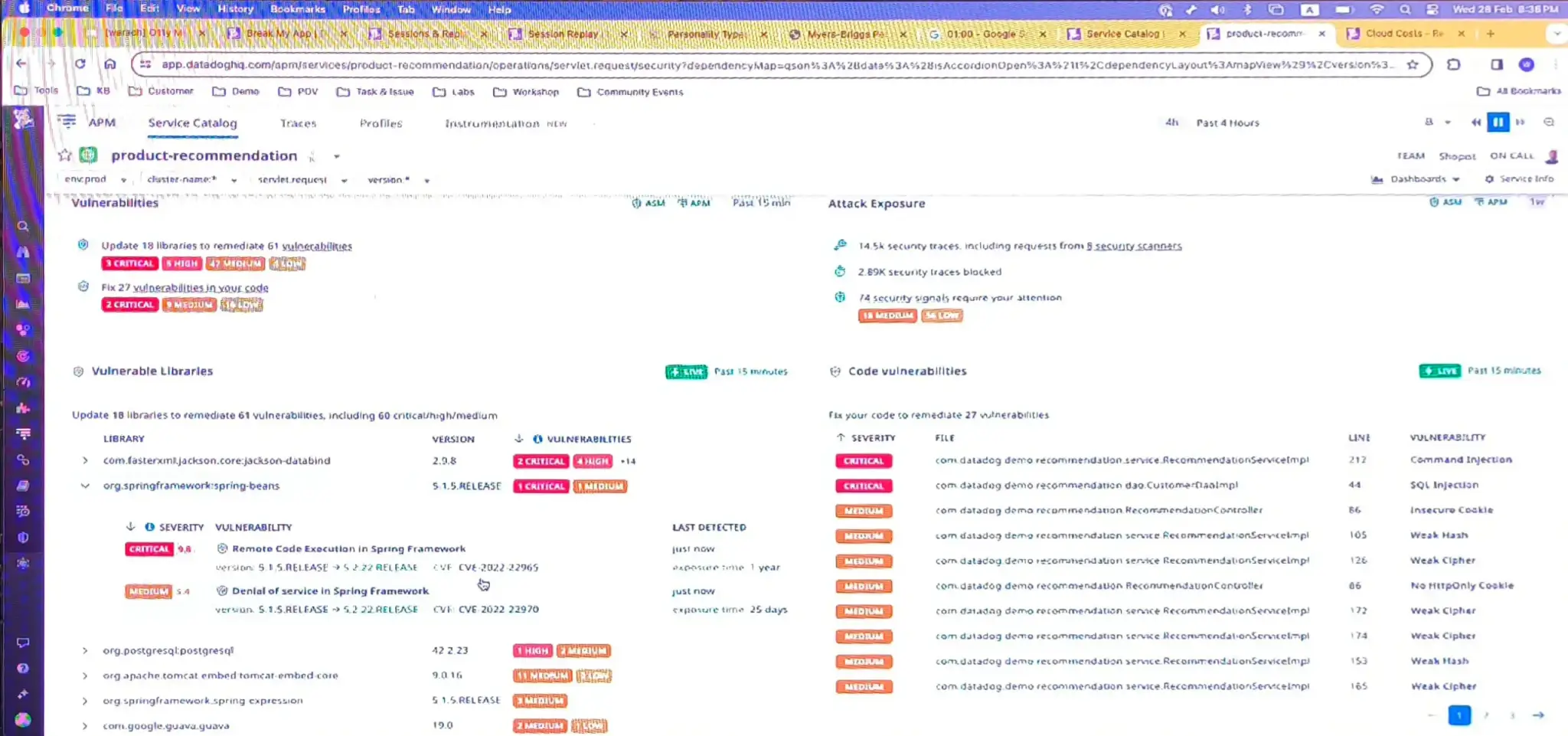
จริงๆมันมีตัวอย่างของ Speaker เรื่องการวิเคราะห์นักเตะ มาเป็น Monitor (Simple Stat แพ้-ชนะ ของทีม) > Observability (มองลงไปในแต่ละคนเลย ว่ามี Skill ยังไงด้่วย ไม่แน่ใจว่าเขียนถูกไหมนะ ไม่ใช่คอบอลด้วย
- Why Observability
มุมของ Data Dog > Industry Paradigm shift จาก
- Tech ที่เปลี่ยนไป
- Computing Uniy เพิ่มขึ้น จาก Physical > VM > Cloud > Container
- Release ถี่ขึ้นให้ทัน Business
- Workflow ที่เปลี่ยนไป ได้ Buzzword ใหม่ๆ DevOps > DevSecOps ...
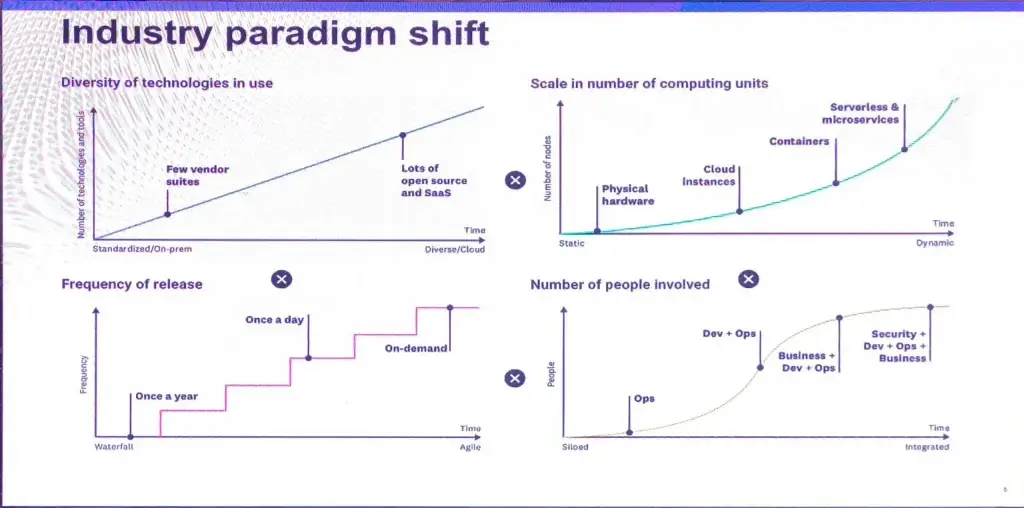
สิ่งที่ต้องเอามาพิจารณาสำหรับการขึ้นตัว Observability
- Size - ระบบที่มีทั้งหมด แล้วเราจะเอาระบบไหนมาเข้าตัว Observability
- Time - เวลาเหลือ หรือ เวลาจำกัด ถ้าจำกัด ต้องเอา Tools ที่ Config ง่ายๆมาใช้ อย่าง Data Dog
- Team - คนพร้อมไหม มี KPI ที่เกี่ยวข้องไหม
- Budget - ทำแล้วได้ผลตอบแทน ROI กลับมาอย่างไร
- Observability Maturity Model

- ภาพนี้อธิบายชัดเจนดี ว่าเราอยู่ใน Stage ไหน Foundation (LV1) > Tactical (LV2) > Strategic (LV3) ตามมุมต่างๆ มี Basic
- 1 Step แต่ Log ส่วน Metric optional
- 3 Pillar มี 3 Signal ตาม Observability Log / Metric / Trace - ที่เหลือมุมมองต่างๆที่สนใจ ตอน Demo พวก Dashboard มีข้อมูลในส่วนนี้มาให้นะ
- Business Impact ให้ฝั่ง Business รู้ว่าที่ทำๆกันมีผลอย่างไร เช่น Cost (เอามาตัดสินใจ ว่าลด เพิ่มอะไร) / User Journey ของการใช้ App เป็นต้น
- CI/CD (Dev + Test)
- Security
- Automation - ภาพด้านล่างเป็นอีกมุม เรื่องต้นจาก กลุ่่ม Monitor / Operate จากนั้น กระจายออกไปในด้านที่สนใจ
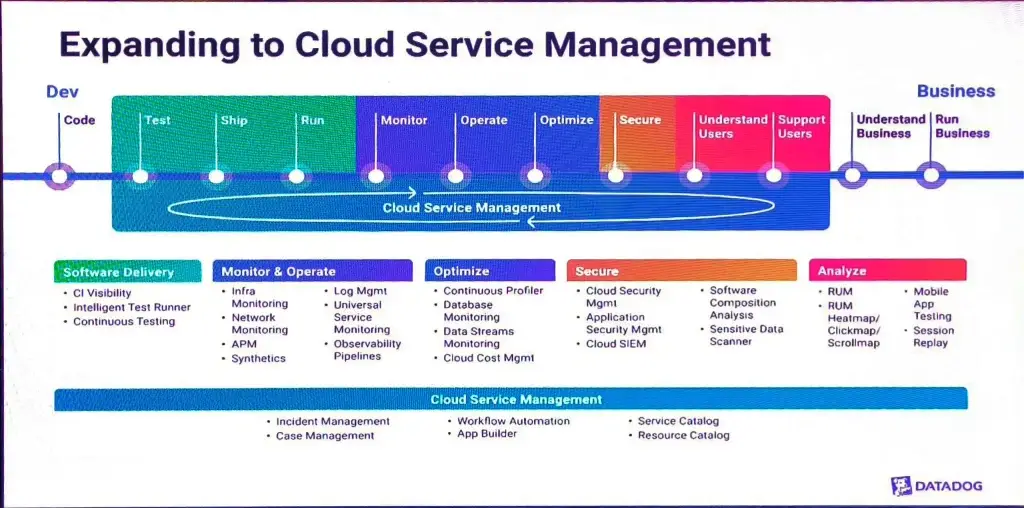
เหมือนฟังมา หัวข้อแรกในส่วน Future of OpenTelemetry Datadog จัดมาให้หมดแล้ว เสียเงินครบจบ
ที่จัดงานวันนี้วิวสวยดีครับ คนใน Cloud Camp มากันโดย ไม่ได้นัดหมายหลายคนเลย

Reference
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


