
จะบอกว่าไปผิดตึกด้วย 55 นึกว่าอยู่ฟอร์จูน เลยมาดูใน Event Pop อีกที เดินมา G Tower หัวข้อประมาณ ดังนี้
Table of Contents
Architecture Kata, Learning Software Architecture by doing
Pain point
- เราจะออกแบบได้ดีได้ยังไง ถ้าไม่ได้ฝีก เพราะเอาจริง ตัว Architecture เราไม่ได้ตั้งต้นเอง บางทีคนอื่นมาทำ หรือ มี Blog เขียนอธิบายไว้ แต่ไม่ได้บอกอนาคตหลังจากนั้น มีปรับอะไรไหม //ฟังอันนี้แล้ว ผมมาเผา Blog อันนี้ให้จบเลย บันทึก Migrate .NET Framework > .NET6
- หรือ คน Design ไม่อยู่แล้ว เลยเป็นที่มาของการทำ Architecture Kata ที่ Speaker ได้ลองนำมาใช้ในองค์กร
Software Architecture
- System Blueprint อะไรอยู่ที่ไหน และบอกถึงความสามารถ กลุ่ม -ilities บอกว่าทำอะไรได้ functionalities /scalabilities / reliabilities เป็นต้น
- Architecture Decision ณ เวลานั้น บอกว่าตอนนั้น ทำทำไม และต่อยอดมาเป็น Design Principle เพื่อให้คนอื่นต่อยอด
KATA - Learn by doing ทำให้ซ้ำๆจดจำ ถ้าฝั่ง Dev Code Kata เช่น โจทย์เดียวกัน แต่ท่าไม่เหมือนกัน มี constraint เช่น ห้ามใช้ if เพื่อฝึกจะได้พร้อมตอนใช้จริง
- Architecture Kata
Architecture Kata คิดโดย Ted Neward มาฝึก เพื่อมาลองผิด ถูกในการทำ Architecture โดยเป็นการจับกลุ่มเล็ก แบ่งกลุ่มย่อยๆ มาลองออกแบบ โดยมี Benefit
- Learn by Doing / Other Experience (คนละ Project / มาจาก บ อื่นๆ)'
- Practice: Requirement Discovery / Communication / Discussion / Presentation)
- Learn from Alternative Solution - ไม่ต้องลองใน Project จริงเจ็บจริง / เปิดช่องทาง Idea ใหม่ๆ
Activities
Key ไม่มีผิด ถูก เน้น disscussion ได้อิสระ
- Architecture Session
Preparation
- Problem ที่สนใจ + Domain Expert เช่น จองวัคซีน / Survey App เป็นต้น
- Moderator จัดการ session ตามเวลา หรือ สวมหมวก มาตอบเพิ่มตามโจทย์ ระวังตอบให้สอดคล้องกับทุกทีม
- จอง facilities
- Onsite: ห้องประชุม board / Post-it
- Online: team / zoom / miro board - ตารางเวลา Kata Activity
Kata Activity
- Brief Requirement (5-10 mins) - Business + Technical Case
- Discuss Phase (45-60 mins)
- จัดกลุ่ม 3-5 คนละ skill
- Design Discussion ใช้ C4 Model เพื่อคุยในภาพเดียวกัน อาจจะคุยลง level 1 (Context) / 2 (Container / Sub System)
Rule
- Tech อะไรก็ได้
- สงสัยถาม Moderator
- อะไรที่น่าจะมี แต่อาจจะไม่รู้ ใส่ assumption เช่น resource ของ cloud aws มี xx azure น่าจะมีอะๆรคล้ายๆกัน
- อย่าเลือกคน เรามาฝึก คละกันจะได้แชร์ประสบการณ์ - Peer Review Phase (10-15 mins Per Team) เน้น
- Business Case ว่าที่เราทำมาตอบโจทย์ Business
- Tech Solution + Vision
- Q&A - Voting Phase: thumb up / OK / thumb down
Resource: Architectural Katas: Practicing Architecture
Saga Pattern 101: Orchestrating Distributed Transactions
SAGA pattern สำหรับ distribute Architecture มีหลาย action เกิดขึ้นต่อเนื่องกัน และมีความสัมพันธ์กัน เช่น ซื้อตั๋ว และ จองโรงแรม และ จองเครื่องบิน ถ้าสำเร็จหมด ถือว่าจองทริปสำเร็จ ถ้าไม่ต้อง Rollback.
จริงๆแล้ว SAGA Pattern มันมีอยู่แล้วและแก้ปัญหามาแล้วใน Database ตัว ACID
- Atomicity - transaction is treated as a single unit ทำสำเร็จจบ ถ้าไม่ ตี Fail
- Consistency - ใน Single Unit มันต้องสอดคล้อง โอนจาก A -> B เงินหัก A ไปเพิ่ม B เก็บตาม data type / Schema
- Isolation - concurrent transactions โอนเงินพร้อมกัน มันไม่ต้องเข้ามั่ว / หลบ race condition
- Durability - อะไรที่ Commit ไปแล้วสถานะคงเดิม เช่น ปิด DB ไปเปิดมาก็เหมือนเดิม
จากเดิมที่
- Monolith จบในตัว SQL จบ order / customer / inventory / account เปิด Transaction และจัดการ Table 4 ตัวให้เรียบร้อย ถ้าสำเร็จ Commit จบ
- พอปรับเป็น Microservice แต่ละ system จะมี Local Transaction ของตัวเอง เสีย Atomicity / Isolation ไป
จริงๆแล้วมีวิธีแก้ปัญหา Distribute Transaction / 2 phase commit แต่มัน scale ยาก และเกิด deadlock นานๆ ถ้าต่างระบบ คนละ vendor เช่น คนละ Bank เราไม่สามารถคุม lock ได้
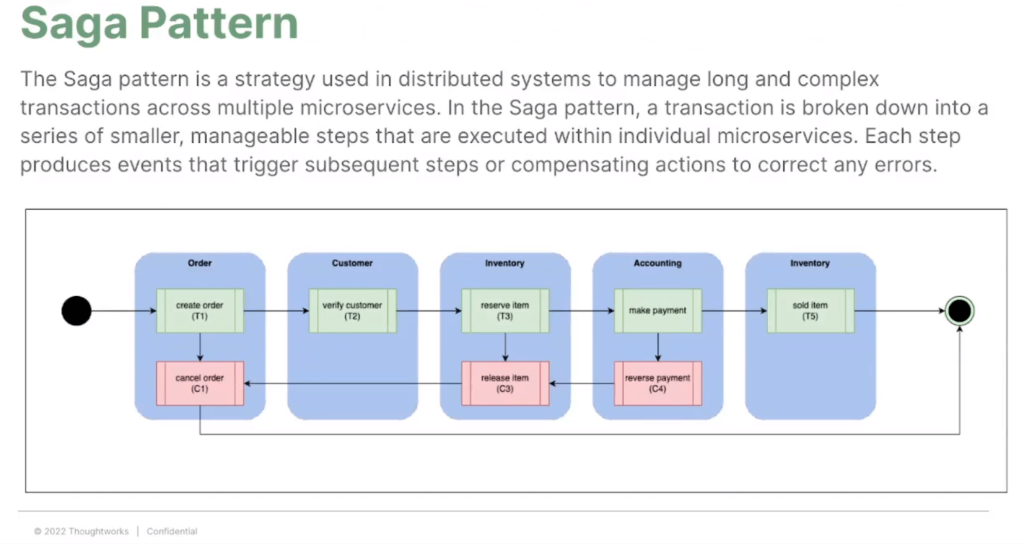
Saga Pattern = คิด Flow ของแต่ละ Microservice ให้ครบ (เหมือนพวก BPMN) จัดการพวก Long Living Tx
- Happy Flow (สีเขียว)
- Alternative Flow หรือ Compensation Tx (สีแดง) ในแต่ละเคส ต้องคุยกับฝั่ง business ด้วย เพื่อรองรับ
- การ Rollback - ยกตัวอย่าง เช่น ต้องจองบัตร ถึวจอง รร ได้ แล้วถ้าไม่สามารถจองบัตรได้ ต้องถอยยังไง
- Retry Flow- เช่น ตัดเงินไม่ได้ แต่มีการใส่บัตรใหม่มา ให้ต่อเลยไหม
Note ต้องเป็น Idempotent ทำกี่รอบ ผลต้องเหมือนเดิมด้วย
Implementation - Event Driven Architecture ส่วนใหญ่มาท่านี้ เมื่อ Microservice A เสร้จ publish และรออีก Microservice มา subscribe โดยมีรูปแบบ
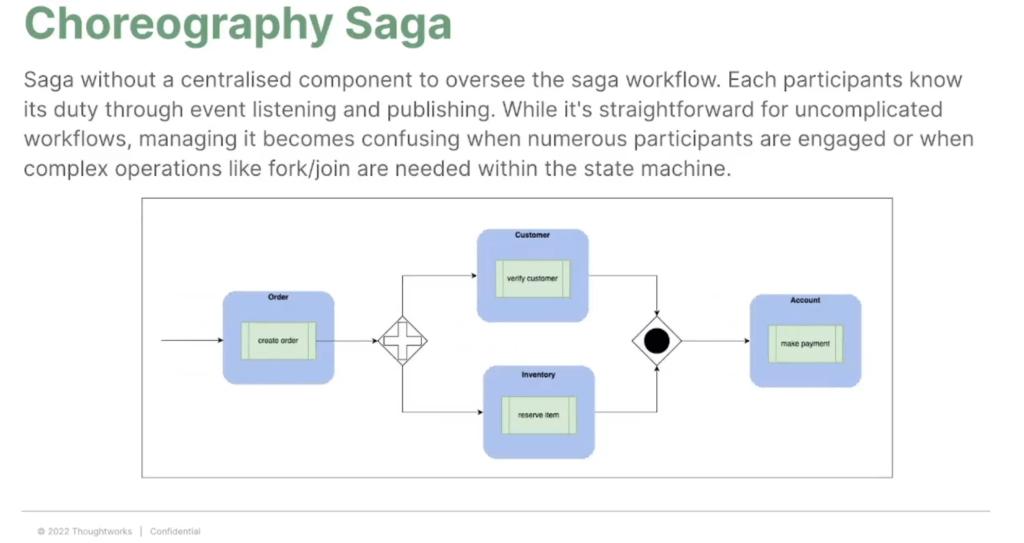
- Choreography SAGA - ไม่มีตัวกลาง ทุกคนได้ Event แล้วทำเลย แต่ต้องเก็บ state ไว้ Pattern เส้นตรง + fork/join (กรณีที่ทำงาน parallel)
- ข้อดี simple
- ข้อเสีย ต้องมาไล่ State กัน /ไม่เหมาะกับงานที่ State ที่ซับซ้อน
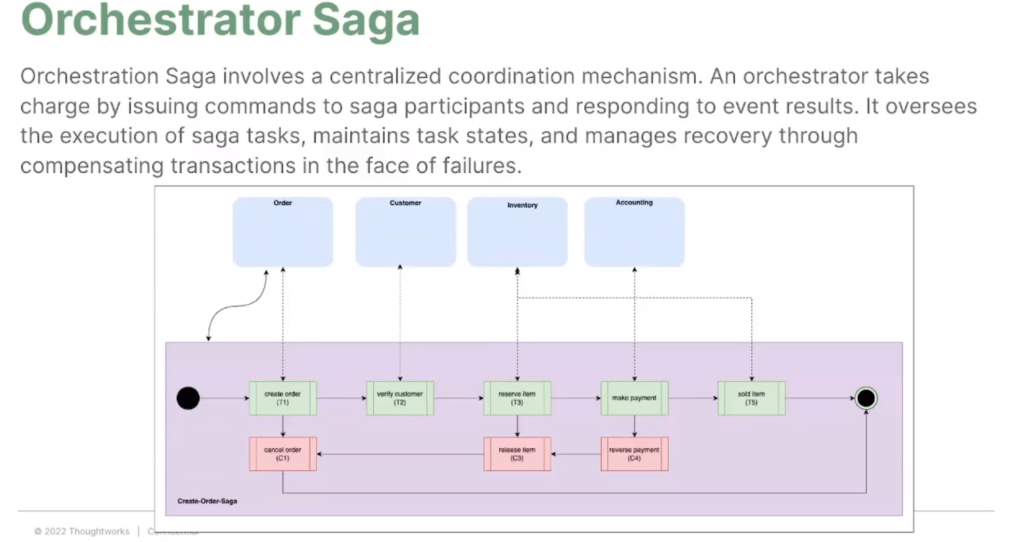
- Orchestrator SAGA - มีตัวกลางจัดการ state / workflow
- ข้อดี รวมศูนย์ logic รู้เลยว่าใครต้องรอใคร
- ข้อเสีย พอมีตัวกลางมา แสดงว่า cost เพิ่ม Microservice มาทำตรงนี้
ตอนนี้แก้เรื่อง Atomicity เหลือ Isolation ปัญหาเหมือน DB เลย
- Dirty Read - อ่านมาแล้ว แต่ไม่ข้อมูลล่าสุด
- Lost Updates - เขียนทับของ SAGA อื่น เช่น Request SAGA (Create) สักพัก ส่งงานให้อีก SAGA (Cancel) แต่ผลลัพธ์เป็นของ SAGA (Create)
- Non-repeatable Reads - อ่านข้อมูลสองรอบแล้วได้ค่าไม่เท่ากัน เพราะมี SAGA Write ไปแล้ว
วิธีแก้
- Semantic lock กำหนด flag ห้ามยุ่ง data lock ไว้ก่อน ที่หลังจากนี้จะให้ทำอะไร เช่น cancel หรือ retry รอ
- Commutative Updates - ทำให้ Operation ของเรา Order ไม่มีผล พวก a+b หรือ b+a เท่ากัน
- Pessmistic View - เรียง operation ลด dirty read
- Reread Value - Optimistic lock
Tools & Implementation
- Choreography SAGA (State Machine Base) - AWS Step Function / Spring State Machine / Eventuate Tram
- Orchestrator SAGA (Workflow-Based Base) - Camunda.io (BPMN Engine) / orkes.io / Netflix/conductor
Key Takeaway: SAGA for long living Tx ถ้าเอามาใช้ระวังเรื่อง Atomicity / Isolation แต่ถ้าทำแล้ว SAGA เยอะๆ ต้องมาไล่แล้วผิด Business Flow แปลกไหม
Q&A:
- Q: ระบบที่จองของแล้วตัดเงิน ตัดเงินเคสบัตรเครดิต เดบิต แล้วถ้ารอโอนจะ Handle ยังไงกับการเสียโอกาส
A: แก้ที่ business ทำ wallet ให้สิทธิมากกว่า เช่น ถูกกว่า, มี point, ฟรีค่าธรรมเนียม / Overbooking สำรองจาก limit
Prove distributed system with TLA+
What is distribute system
- หลาย System ทำงานร่วมกันผ่าน Protocol กลางเช่น network ถ้ามีอะไร Failure เราจัดการยังไงให้มันทำงานต่อได้
- คนที่ดังๆด้านนี้ Leslie Lamport
Failure in System
- ยิ่ง system complex failure เกิดง่าย เช่น
V1: Upload csv เล็กๆ เก็บลง >> DB Simple server 1 db 1
V2: 10 GB CSV ต้องมี obs พักไฟล์ และทำ Queue แยก node ช่วยกัน process
V3: External System
ยิ่ง system complex failure เกิดง่าย ทั้งจาก HW / SW
- HW พัง disk / network
- SW พัง latency / Concurrency update พร้อมกัน / GC / Crash / Metric แปลกๆ load เยอะบางจุด
Reason to go distribute - จาก Business Need เช่น ระบบต้องรองรับ User ล้านคนต้องมี Scalability / Availability / Latency load ไว เป็นต้น
Design Distribute ควรรู้อะไร
- Cap Theorem เลือก 2 จาก 3 (Consistency/Partition Tolerance/Availability) มี blog ฟังจากนี้แหละของปีก่อน คล้ายๆกัน
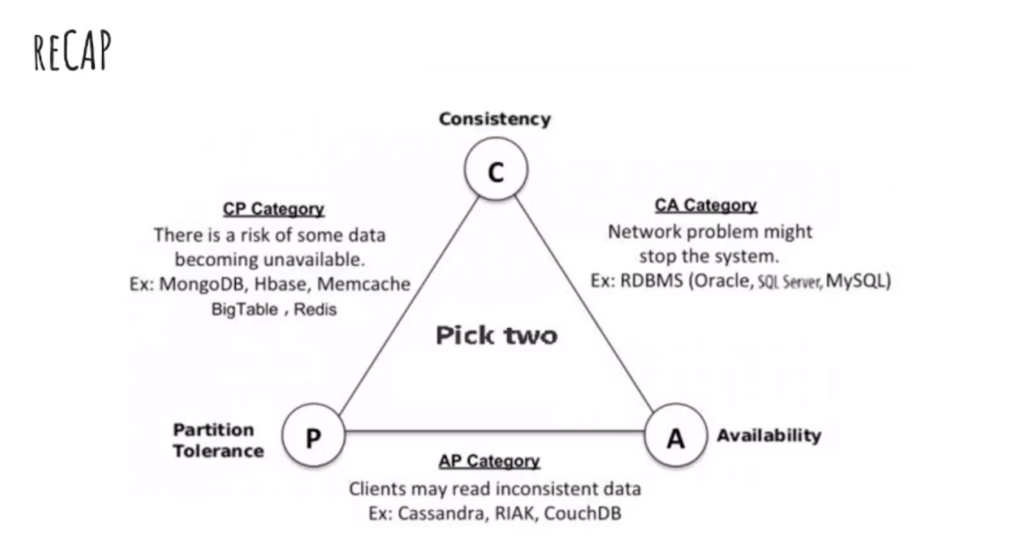
- Key Property ฟังแล้ว เอ๊ะ มันน่าจะใช้เรื่อง Formal Verification หรือป่าวนะ
- Liveness Availabilityหรือ ไม่ค้าง deadlock
- Safety เช่น เงินฝากต้องไม่ติดลบ โอนแล้วเงินต้องหัก
How you verify that system work correctly
- Unit Test + Automate Test ถ้า distribute flaky test เกิดไหม
- Scenario / Behavior Base Testing
- jepsen-io
- TLA+ Formal Verification ที่เดาไวใช่แหละ ผมย้อนไปถึงเรียน ป โท เลยเขียน Promela / Crisp มั้ง โดยที่ Formal Verification มาช่วย Test in Design TLA+ เป็นภาษาที่ช่วย model มา proof concept เช่น ทำ DB ใหม่ที่แก้เรื่อง isolation งาน scale ใหญ่ๆ ขึ้นมา การ PROVE จาก MODEL ให้เรียบร้อย ช่วงลดข้อผิดพลาด Design แต่มาดักอีกทีตอน Implement System
จากนั้น Demo TLA+ แนะนำดูจาก Live อารมณ์เหมือนย้อนกลับไปเรียน โท เลย Session นี้
Reference
- Software Architecture Meetup 2023 #2 | Eventpop | Eventpop
- Live: https://www.facebook.com/100045274272935/videos/3420939444885146/
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


