
สำหรับวันนี ผมมาแบบ + 1 ครับ ตอนที่พี่ที่บริษัทชวนมา ไอ้เราก็บอกว่าไปด้วย แถมลืมจ่ายตังค์ให้พี่เค้าอีก ดองค่างานข้ามปีกันเลยทีเดียวครับ สำหรับงานวันที่สถานที่จัดงาน คือ ที่ LINK Collaboration Space @ MRT หัวลำโพง มันอยู่แถวอุทยานจุฬา 100 ปีครับ ฝั่งถนนบรรทัดทองครับ ทางเข้าก็ซ่อนแอบอยู่ข้างโรงเรียนครับ เดินหลงไปเหมือนกัน

 NLP - Natural Language of Passion โดย ดร.อาร์ม [ NECTEC ]
NLP - Natural Language of Passion โดย ดร.อาร์ม [ NECTEC ]
ทุกปัญหา ทุกเรื่อง มันมี Pattern อย่าง ดร. อาร์ม สนใจความแปลกในภาษาเขียนของชนชาติต่างๆ Math และองค์ความรู้ของฝั่ง IT มันมีความหลงไหล(Passion) ที่พยายามหา Pattern ของมัน

Passion มาจากไหน ลองมาดู Pattern Finder Process
- เกลียด - เจอปัญหา อยากรู้คำตอบ
- สำรวจ Data - มันมีอะไรบ้าง ?
- สกัด information และ เบาะแส จาก Data
- หา Abstract pattern
- แก้ปัญหา โดยเริ่มจาก Abstract Pattern
- ทบทวนดูว่าเราได้อะไร จากการแก้ปัญหา ตาม Abstract Pattern นั้น
Language of passion
- ตัวเอง- อะไรที่ตัวเองตื่นเต้น Wow เราเองก็ไม่ต้องฝืนไปกับมัน และมันมีความท้าทาย ให้สู้
- สร้างตัวตน - make a plan 》 strive for execellence ต้องสุ้สิ 》 Continuous Improvement & Contribute
- ช่วยสังคม - ทำเอง 》 สอน 》 สร้างแรงบันดาลใจให้ผู้อื่น(Inspiration)
สุดท้ายแล้ว ทำอะไรตาม Passion แล้ว อย่าลืมทำเพื่อสังคม ^__^
People With Passion Can Change The World, Steve Jobs
DS แบบไม่ต้องโค้ด โดย ดร.เอกสิทธิ์ [ DATA CUBE ]
Text Mining ข้อมูลทั่วๆไปมี 2 แบบ
- Structure - พวก XML
- Unstructure
Application
- Classify
- Sentimental Analysis
ถ้าวิเคราะห์ทำ Text Mining กับ Twitter เรามีขั้นตอน อย่างไร
- เอา Emoticon ออก
- ทำ Tokenization ตัด stop word ทำ Tf (Term Frequency) IDF- คำไหนสำคัญ
- มันจัดกลุ่มคำว่าคำไหนเป็น + หรือ -
สำหรับ Tools ที่ใช้ โดยไม่ต้อง Code คือ โปรแกรม Rapid Miner
- Rapid Miner เป็นลักษณะของ Process ลาก แต่ละ Operator มาต่อกัน ซึ่งตัว Twitter เอง มี Operator ของ Search Twitter นะ
- ใน Rapid Miner เวอร์ชัน 8.x ตัว Tools เองมี Feature ใหม่อย่าง Auto Model ใช้ Run Model Machine Learing หลายๆ Model พร้อมๆ และเลือก Model ที่เหมาะสมมาให้ แต่มันมีข้อจำกัดว่าต้องใช้ในเวอร์ชันเสียเงิน หรือ Educational License(ใช้ได้ 1 ปี) ต้องใช้ E-mail ของมหาวิทยาลัยสมัย
From Good to Great DS โดย ดร.ศิษฎพงศ์ [ G-ABLE ]
Good is enemy of great - Jame C. Colins จะทำอะไรให้ดีง่าย แต่ถ้าต้องการเป็นที่หนึ่งมันยาก
ผมชอบ Quote นี้นะ
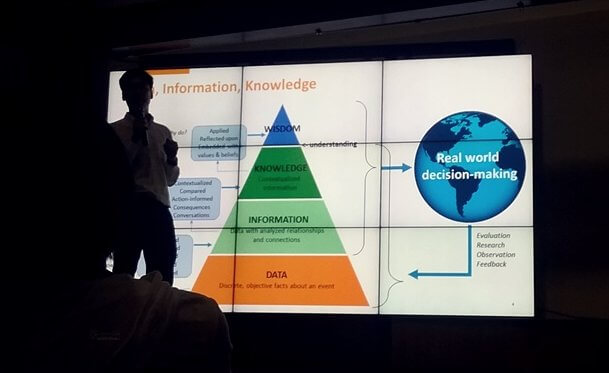
โลกมันหมุนไปเร็วมาก จากเดิมการจัดการองค์ความรู้ มันมี 4 ระดับ ได้แก่
- Data: ข้อมูลดิบ
- Information: สารสนเทศ - ผมมองว่าเป็นข้อมูลที่ผ่าน Preprocess มาแล้ว สะอาด
- Knowledge: ความรู้-เชี่ยวชาญ
- และ Wisdom: ปัญญา-เอามาปรับใช้ได้จริง
แต่ในปัจจุบันความต้องของฝั่งธุรกิจเปลี่ยนไปเร็วมาก จนบางทีการพัฒนา Information ขึ้นมา มันไม่ทันกับธุรกิจ จนบางครั้งต้องคุยที่ Data ดิบ ซึ่งถ้าสามารถทำที่สามารถสร้าง Wisdom ก็ถือว่าเป็นผู้นำ
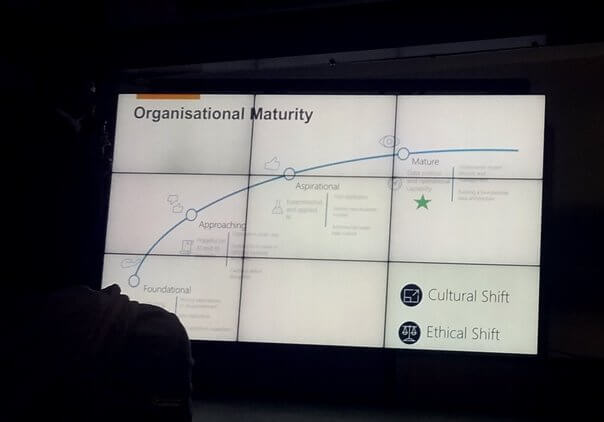
Organizational Maturity - ผมชอบคำนี้นะ บอกว่า เราพร้อมมีวุฒิภาวะมากเพียงไหน จริงพอลองมาดูกับ SDLC เออช่าย
- Fundamental - ตระหนักถึง เช่น AI ทำอะไรได้ ยังไม่มีการเตรียมข้อมูล
- Approaching - มีการจัดการข้อมูล และบอกได้ว่ามันสร้างประโยชน์อะไรได้
- Aspirational - เอาข้อมูลที่จัดการแล้ว มาคิดต่างได้ สร้าง Product & Service พวก Startup จัดในกลุ่มนี้ คือ มี Experiment & Apply
- Mature - เอาไปใช้งานจริงแล้ว มีการ MA ดูแลต่อไปได้
3D
- Data Scientist - ทำให้ได้ Insight
- Data Engineer - ทำให้ Data มันสะอาด
- Data Analyst - ทำให้มันเห็นภาพ
ทุกองค์กร สมัยนี้ต้องมี R&D สร้าง Insight ใหม่ๆ มา (อธิบายได้ด้วยนะ ว่ามันมีที่มาอย่างไร ให้ Business เอาไปใช้) และ Factory ทำให้มันตอบโจทย์ Business
Data Science = Processing >> Insight >> Action (บอกได้ว่า Fact ที่ได้ Insight ที่ได้ เกิดจากอะไร มาจากไหน)
ถ้าถามผม Session นี้
- R&D = Data Science
- ส่วน Factory = Software Engineering มี Process / Coding ดี รวมถึง Product ที่ออกมามีคุณภาพ(Quality)
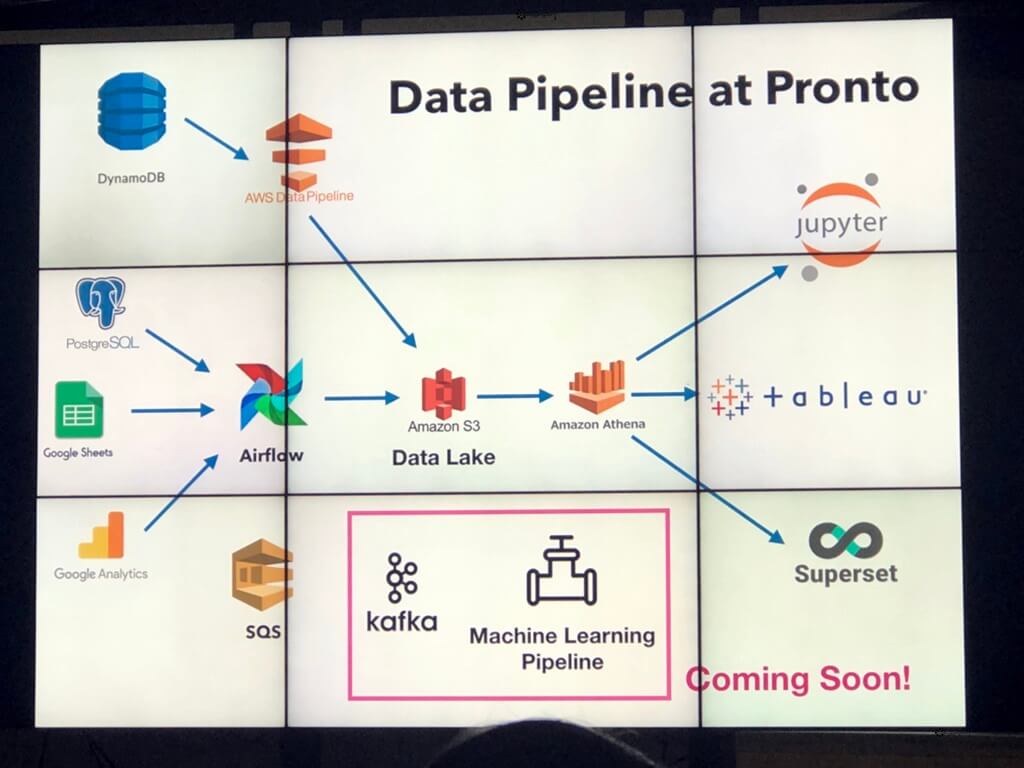
Data Science Pipeline โดย ดร.กานต์ [ PRONTO MARKETING ]
- ทุกวันนี้ Data มีขยะเพิ่มมากกว่าข้อมูลที่พร้อมใช้หา Insight เช่น ทำ 5 วัน ใช้ 5 วิ
- Data Pipeline - Process การประมวลผลข้อมุล แบ่งเป็น Block / Debug รับ Stream และ Automate
- มาดู Stack ของ Pronto บ้าง
Master of Data Science โดย แอดเพิร์ธ [ Data Science ชิลชิล ]
หลายมหาวิทยาลัย Top ของโลกมีปริญญาโทด้าน Data Science กันแล้วครับ Google ได้เลย *เท่าที่ผมทราบมาของไทยมีที่ NIDA กับที่ CHULA(ออกแนว Technical เยอะ)
ตอนนี้ แอดเพิร์ธเรียนที่ ที่ Australia ที่มหาวิทยาลัย Monash สำหรับหลักสุตร Master of Data Science จะเรียนกัน 2 ปี 4 เทอม ซึ่งใน 1 เทอม(12 week) เรียน 16 หน่วย ตีง่ายๆลงได้มากสุด 4 วิชา ซึ่งใน 1 คาบ 4 ชั่วโมงแบ่งเป็น
- Lecture 2 ชั่วโมง
- Lab 2 ชั่วโมง โดย Lab เป็น Workshop และ Lab ที่นี่ ทำแล้วลองตรวจผลลัพธ์ได้เลยครับ (อันนี้ ผมคิด น่าจะเหมือนระบบของตัว Edx นะครับ)
แต่ละเทอมเรียนอะไรบ้าง
- เทอม 1 - Foundation Unit ปูพื้นฐาน Data Science
- เทอม 2 - เรียนลึกเรื่อง Data Science
- เทอม 3 - เรียน + ติดต่ออาจารย์ทำ Thesis
- เทอม 4 - เรียน + ทำ Thesis ให้จบ และ Speaker บอกว่า ป.โท ที่ต่างประเทศ มันเรียนข้ามสายได้ด้วย อย่างตัว speaker เองไปลงวิชาทาง Business
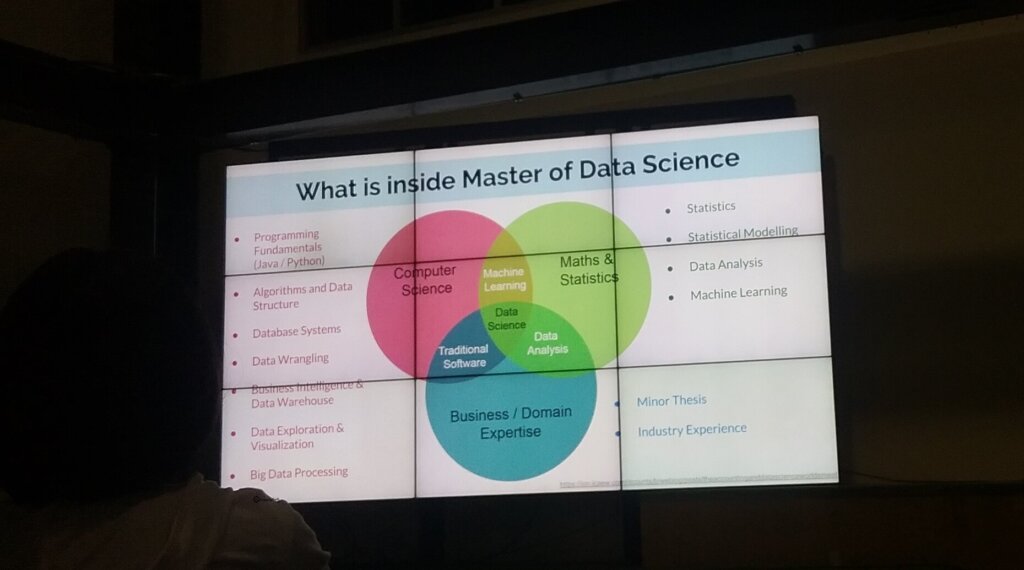
จุดเด่น - มันมี Course ปูพื้นฐานให้ ถ้าไม่จบสายคอมก็เรียนได้ Data Science ของที่ Monash - รู้ภาพกว้างๆ 3 มุมมอง
- IT - Programming / Algorithm / Data Structure / Database / BI / Big Data
- Math - Stat / Data Model/ Data Analysis / Machine Learning / etc.
- Business - Minor Thesis หรือ Industry Experience (ผมเข้าใจว่าเป็นพวกสหกิจนะ)
นอกจากเรียนมีกิจกรรมอื่นๆมากมาย
- ท่องเที่ยว
- Meetup - งาน Tech ต่างๆ หรืองานอื่นๆ
- ศัพท์ใหม่สำหรับผมนะ Datathon vs. Hackathon
- Datathon - หา insight จาก Data
- Hackathon - ทำ Product ตอบโจทย์กับปัญหา
ชีวิตดราม่าของคนทำ Social โดย @leafsway [ Thoth Zocial ]

Note: Social Listening - เป็นการดูแบบ Passive ผมเข้าใจว่ามองทางอ้อม อยากรู้ว่าสังคมพูดถึงเราอย่างไร !!!!
ชีวิตดราม่าของคนทำ Social 5 เรื่อง
#เราไม่เข้าใจนาย - ภาษาที่มันซับซ้อนทุกวัน ทุกวันนี้ มีศัพท์แปลกๆ เกิดขึ้นทุกวัน เช่น นก, ตะใตะมิ หรือ ประโยคนี้มันตีความได้อย่างไรนะ หรือ caption กับภาพคนละแบบ คำผวน ประชดความเพี้ยนของภาษา เกิดการใช้คำที่ง่าย ชิมิ - ช่ายไหม / เหตุการณ์ / พิมพ์ผิด เช่น เมพ - เทพ
- ข้อความกลุ่มนี้ เราตีความได้อย่างไร ? - คิดยังตีความยาก ระบบยิ่งยากกว่า
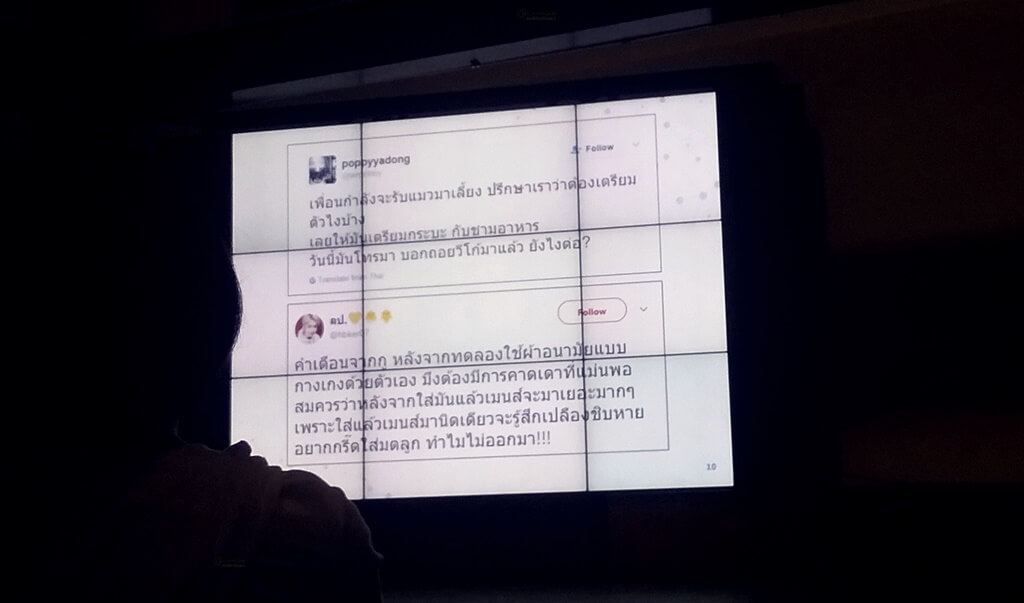
- ดร.อาร์ม [ NECTEC ] เสริมตรงส่วนนี้เข้าไป ว่าทำไม ภาษาไทยถึงทำงานพวกนี้ยาก ตาม Slide อ แก เลยครับ



#คุณเก็บความลับได้ไหม - API ที่เปลี่ยนไปตาม Policy ของ Platform ข้อมูลบางอย่างเมื่อก่อนเก็บได้ แต่ตอนนี้เก็บไม่ได้แล้วนะ อันนี้จริงของผมเองก็โดนมากับตัวตอนทำ Term Project ตอนเรียน SNA เหมือนกัน เปลี่ยน API ปุ๊บชีวิตพัง จากเดิมเคยดูข้อมูล FB Page ต่างๆมาได้ พอจะทำโปรเจคอ้าวต้องเป็นเจ้าของเพจซะงั้นถึงจะดูข้อมูลได้
#แล้วจะเก็บยังไง - ตอนนี้มี 3 แบบ
- Keyword
- Page tacking - เก็บทั้ง Page เลย ไม่สนใจ Keyword ทั้ง Post จาก Page และจาก User ได้ความเห็นที่มีต่อ Brand แต่เอาข้อมูลมาเปรียบเทียบยาก เพราะ จำนวนที่ Follow / Like ก็แตกต่างกันแล้ว จริงๆ ถ้าไม่ชอบ Page ก็คงไม่ Like
- Collect by post tracking -ดึง Comment จาก Post ที่สนใจมาวิเคราะห์
- Note: เราจะเก็บข้อมุลบน Assumption อะไร ตกลงกันให้ได้ก่อน ทั้งทีมพัฒนา และลูกค้า

#Mr. Report - Presentation มันง่าย จริงเหรอออ !!!! กว่า 1 Report ออกมาใช้ยลโฉมได้ มันต้องใช้เวลา และทีมงาน Data Team (Collecting / Process / Deliver & Visualization)
#ทำไมไม่บอกกัน !! - วิเคราะห์ข้อมูล เราจะรู้ได้ยังไง ว่ามาจาก Brand จ้างมา (ต้องเขียนดีอยู่แล้ว) หรือ มาจากใจ(ใช้แล้วดี แย่ มาแชร์กัน) ปัญหานี้มันทำให้ผลลัพธืมัน Bias
สำหรับผมเองนะ ดราม่าพวกนี้ มันก็คล้ายกับปัญหาของการทำ Software ขอบ่นบ้าง ดึกมาหลายคืนแล้ว
Requirement !!!
Requirement !!!
Requirement !!!
DS Learning Path 2018 โดย แอดทอย [ DataRockie ]
ตอนนี้ Chat Bot ที่เป็น AI ตอนยังไม่ผ่าน Turing Test - Concept ของ AI เบื้องต้น Blade Runner การตรวจสอบว่าเป็น repentance ปัจจุบัน ยังไม่มี Chat Bot ตัวไหน ผ่าน Turing Test แต่ทุกอย่างโตขึ้น ดีขึ้นเหมือน Moore's Law
การเรียนรู้ มันเป็นการ Connecting the dot เมื่อถึงเวลาสิ่งที่เราได้เรียน มันจะมี Pattern ความสัมพันธ์ และก่อให้เกิดประโยชน์ได้
Live as if you were to die tomorrow. Learn as if you were to live forever. – Mahatma Gandhi
Stick with it - ทำยังไงให้มันสำเร็จ
- Step Ladder - ค่อยๆก้าวไปทีนะนืด ตั้งเป้าให้ได้ที่ละนิด เพิ่มทีละหน่อย
- Community - Share & Contribute
- Important - มี priority ของชีวิต เติมคุณค่าให้ตัวเอง
- Easy - ทำจากเล็กไปใหญ่
- Neurohack - เรียนรุ้จากการ ลงมือทำ (Try & Error)
- Captivating - ให้รางวัลกับชีวิต (Gamenification)l
- Engrained - พัฒนาอย่างต่อเนื่อง Continuous Improvement
สนใจอะไรแล้ว เราลุยไปเลย และไม่ต้องแคร์เรื่องชื่อตำแหน่ง จะเป็น Data Scientist หรือป่าว ขอแค่ทำงานได้ก็พอ ^__^
ปิดที่ด้วยของกิน ถ่ายมาฝาก แต่กินไม่ได้ ผมลดน้ำหนักอยู่ครับ 555

สุดท้าย
- วันนี้ผมเพิ่มรู้ว่า แอดเพิร์ธ [ Data Science ชิลชิล ] กับ แอดทอย [ DataRockie ] ไม่ได้จบสายคอมมาทั้งคู่ แต่เก่งมากๆ ทำ FB Page สอนความรู้ทางด้านนี้ ให้รูปแบบที่เข้าใจได้ง่าย
- ฺBlog นี้น่าจะเป็นสรุปงานที่กลับมาเขียนอีกครั้งหลังจากที่ห่างหายไปนานเลยครับ
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


