
วันนี้หลังจาก Train C# เสร็จ ผมรีบออกจากบริษัท ให้มาถึง BTS เร็วที่สุด เพราะกลัวฝนจะตกอีกรอบ เพื่อมางาน SQL Server Community Thailand Meeting ครั้งที่ 3 ครับ โดยครั้งนี้จัดที่ Agoda ที่เดิมครับ ซึ่งในงาน Meetup ครั้งนี้มี 2 หัวข้อครับ ได้แก่
คำเดือน Blog นี้เขียนโดยมุมมองของ Developer อาจจะมีบางเรื่องที่เขียนผิดไปบ้างนะครับ ขอเข้าเรื่องเลยและกัน
Microsoft SQL Server Index (Row Store Index) & Statistics by Chulladej Aramsri

- ปกติแล้วในตัว MS SQL มี Index 2 แบบ ได้แก่
- Row Store Index - มีมานานมากแล้วว
- Column Store Index - เพิ่มมามีใน MS SQL Server 2012
- สำหรับใน Blog นี้เน้นไปในเรื่องของ Row Store Index ครับ โดยเท่าที่ผมฟังมา มัน Softๆ กว่าเรื่องใน Meetup ครั้งก่อนครับ (อันนั้นกลับบ้านไป พักสมองยาววเลย)
- Row Store Index
- เป็นการทำ Index โดยมองจากมุมของ Row Record เป็นหลัก
- ถ้ามองจากพื้นฐานของ Database แล้ว ท้ายที่สุดมันถูกเก็บลงที่ File โดยเนื้อของมันถูกเก็บใน Data File ซึ่งถูกแบ่งย่อยๆ ออกมาเป็น Page (ขนาด Default = 8KB)
- การค้นหาข้อมูล สำหรับดูใน Executetion Plan มันมี 2 แบบ
- Table Scan - Brute Force ไล่หาทั้ง Table
- Index - มีสารบัญ ไว้เป็น key ในการค้นหา เน้นสำหรับการอ่าน ดังนั้นการวาง Index ต้องใช้ให้คุ้ม
- ตัว Index เอาไม่ได้ถูกบังคับว่าต้องมีในมาตรฐาน ANSI แต่มันถูกเรื่องอื่นๆ ช่วยให้มันต้องมีขึ้นมา เช่น
- Contraint อย่าง Primary Key ต้องรับประกันว่าข้อมูลต้องไม่ซ้ำกัน มันเลยต้องมี Index มาข่วย
- แต่ Foreign Key ไม่จำเป็นนะ
- แนวคิดพื้นฐานของ MSSQL Index - ตัว MSSQL ทำ Index รูปแบบ Tree ชนิด Balanced tree โดยทำให้ Tree กว้างที่สุดเท่าที่จะทำได้ครับ เวลาตัดข้อมูลที่ไม่เกี่ยวข้องจะได้ทำได้เร็ว และ Tree ไม่ลึกจนเกินไป

- เงื่อนไขที่เอามาใช้ในการช่วยคัดเลื่อก Column เพื่อนำมาทำเป็น Index
- Selectivity - ความสามารถในการดึงข้อมูล ถ้าต้องการผลลัพธ์น้อยๆ จากข้อมูลทั้งหมดที่เยอะ ควรทำ Index เพื่อเพิ่มความเร็ว ตัวอย่างที่ใช้กัน คือ Primary Key (Unique อยู่แล้ว)
- Density - ความหนาแน่นข้อมข้อมูล ยิ่งต่ำยิ่งดี ตัวอย่างที่ดี คือ Primary Key ตัว Density ต่ำมาก ข้อมูลไม่ซ้ำเลย
- แต่ถ้าเอา Column อย่าง FirstName ซ้ำกับเพียบเลย หรือถ้าเอา Gender มาใช้ ซ้ำกันครึ่งๆเลยๆ เอามาทำ Index ก็ไม่ได้ช่วยอะไร
- Index Depth - ถ้าใน MSSQL ตัว Database Engine เป็นคนกำหนดให้
- Data Types & Index อันไหนที่เหมาะกับ DB
- Numeric - ต้องเป็นแบบ Exactly Numeric หรือ เลขที่หารลงตัว เวลาเอามาทำ Index มีประสิทธิภาพดีที่สุด เร็วสุด
- Character - ทำได้ดี ถ้า key ไม่ยาวมากเกินไป
- Date-Related Index - กลไลเบื้องหลังมันแปลงเป็น Numeric ก่อนจัเก็บอีกที เหมาะสำหรับงานที่ต้องค้นข้อมูลตามเวลา
- Guid - ดีกว่า Character แต่คนอ่านยาก
- Bit Index - Bit 0,1 มันดี ถ้าใช้งานได้ถูกกับลักษณะ เช่น เอาไปเป็น Flag แสดง Product ช้นไหนที่ยัง Support / ไม่ Support
- Note: เสริม Key ที่ไม่ดี คือ Key ประเภทชุดอักษรยาวๆ เข้ารหัสสินค้า เช่น BKK-AYMC-2015-X ถึงว่าคนอ่านจจะอ่านแล้วเข้าใจเลย แต่ Database มันทำ Index ยาก
- Single Column vs Composite Index
- เป็นไปได้ควรจะทำ Index จาก Column เดี๋ยว ที่ Unique พอทำให้เจอข้อมูลได้
- แต่ในโลกความจริง มันมีสถานการณ์ที่ต้องทำ Composite Index
- ใช้เพื่อเพิ่มความสะดวกในการทำ Application
- แต่มันไม่ได้เพิ่ม Speed
- Composite Index ที่เรียงจาก Column A, B กับ B, A นั้น ไม่เหมือนกันนะ
- Heap table vs Clustered table
- Heap table (index_id = 0 ถ้าดูจาก sys.indexes)
- ตัว Page เอง ไม่มี Order เลย ถ้ามี Row เพิ่มเข้ามาตัว DBMS หา Page อันไหนที่ว่าง แล้ว ยัดข้อมูลเลย ทำให้มีจุดเด่นที่ใช้งานพื้นที่คุ้ม
- มาดูแต่ละ Operation ดีกว่า
INSERT เจอ Page ไหนว่าง ก็ยัดเลย UPDATE ปกติถ้า Update ลง Page เดิม แต่ข้อมูลมันใหญ่กว่า ย้ายไป Page ใหม่ที่มีพื้นที่พอ แล้วทำ Pointer ไว้ ซึ่งถ้ามีแบบนี้เยอะๆ จะเกิดปัญหา Forwarding Pointers ถ้ามีเยอะๆ กระทบ Performance DELETE Mark Flag ไว้ หากใครมาเขียนข้อมลทับสามารถทำได้เลย SELECT ทำ Table Scan อย่างเดียวเลย - งานที่เหมาะกับ Heap table พวกที่เก็บ Temp ทั้งหมด มีการ SELECT * FROM แต่ไม่ต้องใช้ WHERE
- ปัญหา Forwarding Pointers
- MSSQL รุ่นเก่า: DROP แล้วสร้าง Table ใหม่ย้ายกันวุ่นวาย
- MSSQL 2008 เป็นต้นไป สามารถใช้คำสั่ง: Rebuild ช่วยได้
ALTER TABLE <tablename> REBUILD
- Clustered table (index_id = 1 ถ้าดูจาก sys.indexes)
- ตัว Page มีการกำหนด Logical Order ซึ่งข้อมูลในแต่ละ Row เก็บมีการเก็บข้อมูลตาม Logical Order เหมือนกัน โดยที่ Leaf Level ของ Index มัน คือ Row ถูกจัดตาม Logical Order เลย
- ใน Clustered table มีได้แค่ 1 Clustered Index เท่านั้น เป็น Physical Index เลย อารมณ์เหมือนกับ Dictionary ถ้ามีการเปลี่ยน Column ที่เป็น Cluster Index ที ต้องรอมัน Rebuild ใหม่เลย
- สำหรับพวก Data warehouse พวก Fact Table นิยมทำกับ Clustered Index บน Field ประเภท Date เพราะ สิ่งที่เราสนใจดูพวกข้อมูลย้อนหลัง ในช่วงเวลาต่างๆ ถ้าทำ Index ไว้มันช่วยให้ดึงเร็วขึ้น
- มาดูแต่ละ Operation ดีกว่า
INSERT เก็บข้อมูลตาม Page โดยต้องเรียงตาม Logical Order ถ้าข้อมูลที่ต้องการเก็บใหญ่เกินไปเกิดการ Splitting Page (ย้ายข้อมุลที่ยัดลงไม่ได้ลง page ถัดไป) UPDATE ถ้ากรณีที่แก้ไขข้อมูลแล้วไปตรงกับ Column ที่ทำ Clustered Index ไว้ Row นั้นต้องถูกย้ายที่เก็บให้ตรงตาม Logical Order DELETE Mark Flag ไว้ SELECT ถ้า Query มีเงื่อนไขที่ตรงกับ Clustered Index มันช่วยให้การ เข้าถึงได้เร็วขึ้น ลด Table Scan ทั้ง Seek(ค้นข้อมูลเดี๋ยวๆ) และ Scan(ค้นเป็นช่วง)
Note: ถ้า Scan ตาม Clustered Index ข้อมูล Sort อยู่แล้ว - งานที่เหมาะกับ Table ทีมีการ SELECT เยอะ ใช้เงื่อนไขที่ตรงกับ Clustered Index
- ปัญหา Index Fragmentation
- เกิดจากการ Splitting Page หรือย้าย Row ในช่วย INSERT หรือ UPDATE ซึ่งถ้ามี Fragmentation เยอะๆ ไม่ดี Performance ตก
- Type of Fragmentation
- Internal - เกิดใน Page เดียวกัน
- External - ข้อมูลกระจายไปข้าม Page
- การ Defect Fragmentation ดูได้จาด
- SSMS - Index Properties
- sys.dm_index_physical_stats
- Page fullness - ถ้ามีค่าเยอะๆ ข้อดีตอนอ่านข้อมูลอยู่ใกล้กันแล้ว อ่าน Pageได้ข้อมูลเยอะแล้ว แต่ข้อเสีย Fragmentation น้อยโอกาสเกิดการ Splitting Page สูง ลักษณะนี้เหมาะกับ Table เน้นอ่าน หากตรงข้ามกันเหมาะกับ Table ที่เน้นเขียน สรุป Fragmentation ควรมีอยู่บ้างสำหรับ Table ที่เน้นเขียน
- การ Control Fragmentation ทำได้โดย
- การกำหนด FillFactor บอก DB ไปเลย ในแต่ละ Page เรายอมให้ DB เติมข้อมูลได้กี่ % ถ้าเกินปุ๊บ Splitting Page เลย แค่ค่า FillFactor กำหนดให้พอดี เพราะ ถ้าทำมาก Disk เปลือง Read อาจจะช้า เพราะ ต้องอ่านข้าม Page
- เน้นทำ Clustered Index มากกว่า
- ดูค่า Default ของ FillFactor จาก sys.sp_configure
- การปรับ FillFactor ใช้คำสั่ง
--Change When ReBuild USE YourDatabaseName GO ALTER INDEX YourIndexName ON [YourSchemaName].[YourTableName] REBUILD WITH (FILLFACTOR = 80); GO --Change When Add Constrait USE YourDatabaseName GO ALTER TABLE YourTable ADD CONSTRAINT PK_of_YourTableColumn PRIMARY KEY CLUSTERED ( YourTableColumn ASC )WITH (PAD_INDEX = OFF, FILLFACTOR = 80); GO
- Index Statistics
- Statistics ค่าพวกนี้ ถ้าคนอ่านมันตีความยาก และไม่รู้ว่ามันสื่อถึงอะไร แต่ตัว Database Engine เอาค่าพวกนี้ไปใช้ในการกำหนด Execution Plan ซึ่งถ้าค่าพวกนี้ เป็นค่าที่อัพเดทล่าสุด จะช่วยให้ Database Engine ตัดสินใจได้แม่นยำมากขึน ในการกำหนด Plan
- Statistics ถ้าเข้าไปดูใน Table >> Statistics พบอยู่ 2 กลุ่ม
- Statistics ชื่อเดียวกับ Index
- Statistics ชื่อประหลาด แต่มี Pattern ประมาณ _WA_Sys_
- Statistics เกิดขึ้นมาตอนไหนหละ ?
- เกิดขึ้นตอนที่ Build Index ครั้งแรก
- เกิดขึ้นตอนที่ Query แล้วไป โดน Column ที่ไม่มี Index แต่ต้องใช้ ตัว Database Engine มันสร้าง Statistics พวก _WA_Sys_ ขึ้นมา เอาไว้อ้างอิงในครั้งถัดไปที่ใช้งาน
- ตัว SQL Server มันมี Auto Update Statistics นะ แต่มันมีเงื่อนไขในการ Update ค่า ดังนี้
- เงื่อนไขที่ 1: เมื่อ Table ที่จากเดิมว่างๆ แล้วมี Row แรกเข้ามา
- เงื่อนไขที่ 2: Table มี Row < 500 Records และ มีการ Insert เพิ่มเข้ามาอีก 500 Row ขึ้นไป
- เงื่อนไขที่ 3: Table มี Row >= 500 Records และ มีการ Insert เพิ่มเข้ามาอีก 500 Row + 20% ของจำนวน Row ทั้งหมด
- แล้วทำไมมี Auto Update Statistics แลัวมัน Database ยังช้า
- ตัว Auto Update Statistics ไม่ทำงาน เนื่องจากไม่เข้าเงื่อนไขของมัน ปัญหานี้ มักจะเจอใน Table ที่มีขนาดใหญ่มาก
- Operation ที่เข้ามายุ่งกับ Table มีพฤติกรรมที่เปลี่ยนไป เช่น
- จากเดิม SELECT น้อยๆ (1/10) อยู่ๆมา SELECT เอาข้อมูลในปริมาณที่มากกว่าแต่ก่อน (5/10)
- หรืออยู่มีข้อมูลก้อนใหญ่เข้ามา Dump หรือถูกเอาออกไป แต่ไม่เข้าช่ายเงื่อนไขของ Auto Update Statistics
- Table ไหนที่มี Statistics กลุ่ม _WA_Sys_ เด็มไปหมดเลยแสดงว่า Query ที่เราใช้มันไม่ตรงกับ Index ที่เคยสร้างเอาไว้เลย ซึ่งตัว _WA_Sys_ ถ้าอันไหนถูกใช้บ่อยๆ ก็เปลี่ยนมันให้เป็น Index ซะ
- ถ้ามี Operation ที่ Dynamic มากๆ จนไม่เข้าข่ายของ Auto Update Statistics ก็ต้องทำเอง โดยใช้คำสั่ง (ถ้าเป็นไปได้คำสั่งพวกนี้ควรอยู่ในรอบการ MA ของ Database ด้วย)
--Update All Table in Database EXEC sp_updatestats --Update Specific Table UPDATE STATISTICS INVEST.DAILYACCPOSITION
- NOTE: Non-Cluster Index เหมือนดัชนีท้ายเล่ม ทำบน Heap หรือ Cluster Index เพิ่ม
Power BI with R by Chawalit Pusitdhikul

- Power BI
- ภาพรวมใน Section นี้คล้ายกับ Blog ตอนที่แล้ว
- เพิ่งรุ้ว่ามี Onpremise Power Bi แต่ยัง Support Data Source ไม่เยอะ ในอนาคตการ Integrate เข้ากับ MSSQL
- R
- Stat software
- flexible กว่า บางเรื่อง power bi ทำได้ แต่อาจจะ lock วิธีไว้
- Prerequisite
- R
- Power Bi desktop จากนั้น Set Path ของ R ให้ Power BI รู้จัก
- Where can you use R in Power BI
- As a Data Source - เขียน Script เข้าไปเองเลย
- With in a query applied step - เขียน Script เอามาทำ Custom Process ที่ Power BI ยังไม่มี
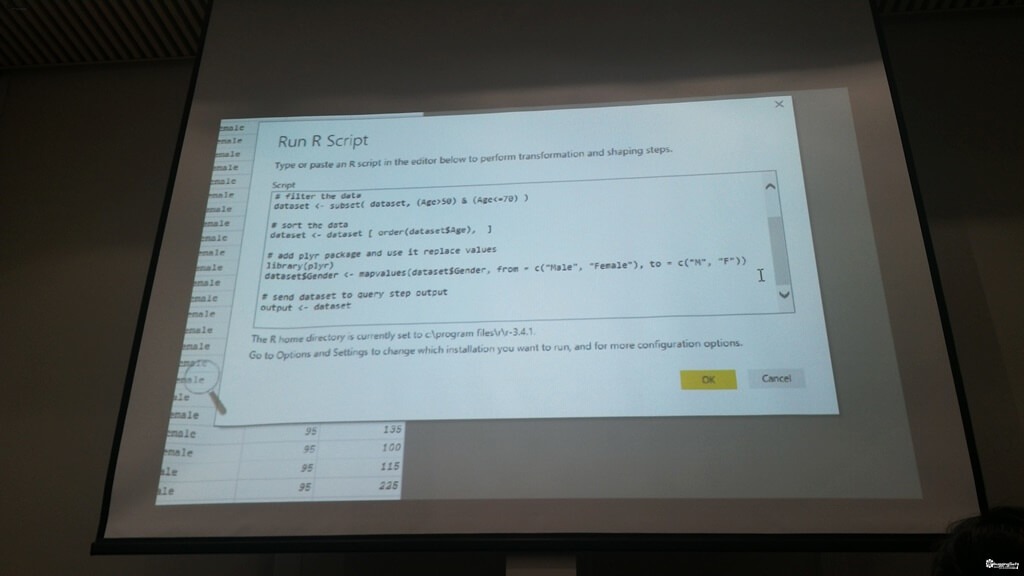
- Inside R Visual in a Power BI Report -ทำการ Visualize แต่ต้องเลือกบางค่า เพื่อบอก R ว่าเอาอะไร ไปเป็น Input
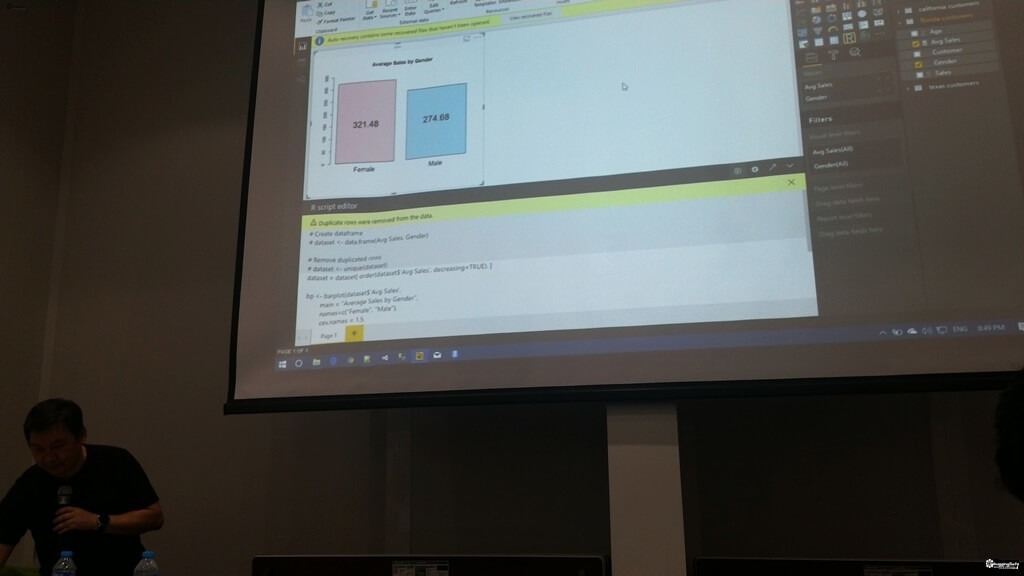
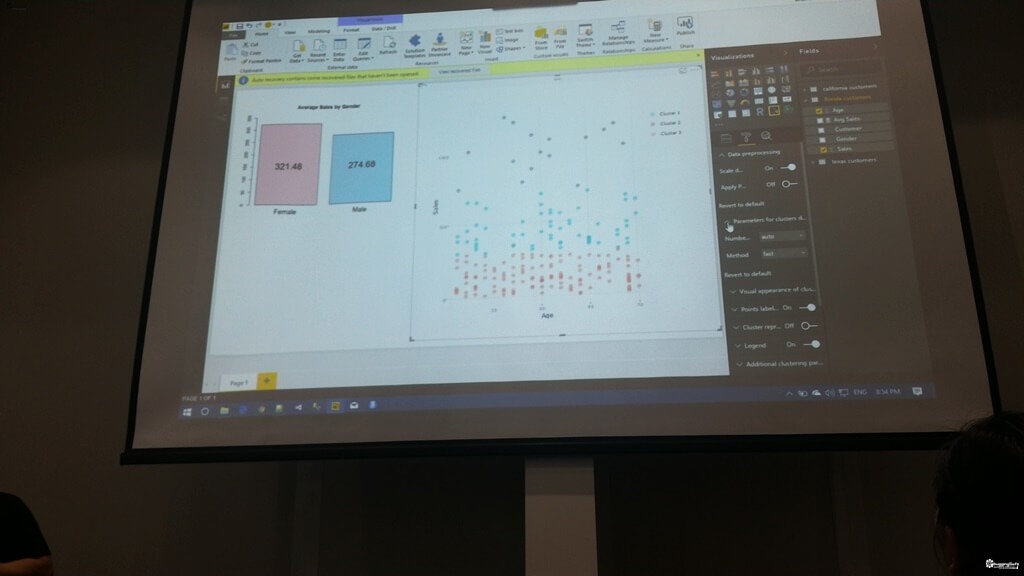
- Custom Visual build with R - เอาตัว Visual จาก Office store มาใช้งาน ต้องการ runtime ของ R และสามารถใช้ร่วมกับ Visual เดิมของ Microsoft ได้ จากตัวอย่างเป็นการทำ Clustering ครับ (กราฟทางขวา)
- R integration Limitation with power bi
- รองรับ dataFrame อย่างเดียว
- ข้อมูลที่เป้น N/A Transalate เป้น Null
- ไม่เหมาะกับข้อมูลที่เยอะมาก (ณ เวลานี้ ในอนาคตไม่แน่)
- Visual Calculation มีรอบ 5 นาที ถ้าเกินจากนั้นมันส่ง Error ออกมา (เหมือนพวก Azure แหะ)
ปิดท้ายของ Blog อาหารการกินครับ มี KFC กับโดนัท อิ่มทั้งท้อง อิ่มทั้งสมองเลยครับ


Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


