
สำหรับมางาน SQL Server Community Thailand Meeting งานนี้จัดเป็นครั้งที่ 2 แล้ว ส่วนงานแรกผมพลาด เพราะติดสอบพอดี
SQL Server Performance Tuning Essential
โดยคุณ Chulladej Aramsri
หมายเหตุ: เขียนในมุมของ Developer หากมีอะไรผิดพลาด ขออภัยมา ณ ที่นี้ครับ
- Root-Cause ของ Performance หลักๆ ที่พบบ่อยๆ จากมากไปน้อย

- T-SQL - เกิดจากการ Query เขียนไม่ดี
- Poor Index Strategy - วาง Index ผิด หรือไม่เหมาะสม เช่น Table นี้ Write เยอะ แต่ทำ Index เยอะ แต่ความจริง Index ช่วยให้การ Read ให้เร็วขึ้น
- Note: SQL Server มี index 2 แบบ Row Store กับ Column Store ต้องเลือกใช้ และ Control ให้ดี
- ถ้าเลือก Index ไม่เป็น ก็อย่าใส่ Index เลย มันบาป - I/O SubSystem
- Application Code - Code ของ Dev แหละ เช่น ใน Loop 1 ครั้ง แวะไปเยี่ยม DB ก่อน ทั้งที่ความจริงมันกวาดมาบางส่วนก่อนได้ (อันนี้ส่วนตัวผมเจอเยอะนะ)
- DB Schema Design
- Out-of-date /missing statistic
- SQL Server Configuration - ตัว MS SQL Server การ Tuning มีรายละเอียดปลีกย่อยในแต่ละ Version โดยการ Tuning เริ่มทำตั้งแต่ติดตั้ง แต่ส่วนใหญ่กด Next รัวๆ กัน
- Virtualization / Hardware Problem และ CPU Power Saving มีน้อยมาก ถ้าดูจากรูป
- แล้วปกติที่ไปจัดการกับ Data ที่ทำผ่าน SQL มันมีแบบไหนบ้าง ?
- Adhoc - เขียน Query สดๆ หรือ เป็น String ที่ฝั่งไว้ในตัว Application
- Stored Procedure - ตัว DBMS มีการเตรียมพร้อมไว้แล้ว มันเร็วกว่าแบบ Adhoc แต่ขึ้นกับวิธีการเขียน Logic ด้วยนะครับ เช่น ตัว Cursor ถ้าใช้ไม่เป็นให้มันอ่านที่ละ Row มันก็ช้าได้ ปกติตัว DBMS อยากได้อะไรเป็นชิ้นๆ ส่งไปปุบ DB ไป Process ได้ผลลัพธ์เป็นชิ้นกลับมาเลย
- Common Approach ในการ Optimize Performance เริ่มจากสิ่งที่ควรทำมากที่สุด
- Schema Design - พื้นฐานสำคัญที่สุด
- Query Optimization - แยกเรื่อง ทำให้เหมาะสม
- Indexing - เน้นอ่าน
- Locking
- Deadlock ( 1205) - Resource ถูกยึดไว้
- Blocking - น่ากลัวกว่า เพราะ มันไม่มี Error Number เอาง่ายๆ ตัว DBMS ไม่สามารถ Detect ได้ แบบ Deaklock (ส่วนตัวเข้าใจว่า Blocking = Starvation หรือ livelock ของการทำ Multithread นะ)
- Server Turing ควรทำตั้งแต่ต้น ควรทำตั้งแต่ Design
- Memory ตัว SQL Server DMV มันกิน Mem เอาไว้ Cache
- I/O - ssd เขียนพอๆกับ disk หมุน Data File อยู่คนละ Physical Drive กับ Log File เราจับกลุ่ม Table แล้วแยกไฟล์ Data ของ DB เป็นหลายไฟล์
- CPU
- Wait Statistic Performance Tuning Approach
- ใช้เมื่อทำ Common Approach แล้ว ยังช้า ยังมีปัญหาด้าน Performance อยู่
- สนใจงานที่รอทำงานอยู่ (Wait) ทำไม ? มันยังไม่เสร็จ เอามาวิเคราะห์จริงๆ มันช้า ที่ DB หรือ App เขียนไม่ดีแล้ว DB ช้าตาม Query ของ App
- Back to Basic ก่อนจะรู้เรื่อง Wait Statistic เราควรรู้อะไรบ้าง
- Three Network Protocal ที่ MS SQL Support
- Shared Memory - ถ้าช้า ลองรันที่เครื่อง DB เรา ผ่าน SSMS เลย จะได้รู้ที่มันดึงข้อมูลช้า เกิดจากตัว Network หรือป่าว ?
- Name Pipes
- TCP/IP
- สำหรับในส่วนของ Application Layer ใช้ตัว Tabular Data Stream Protocol(TDS) ซึ่งใช้ได้กับ MSSQL ทุก Version ที่นิยมใช้ในปัจจุบัน รวมถึงบน Azure ด้วย
- Query Lifecycle จาก Query ที่เราส่งมาจาก App ของระบบงานที่พัฒนา หรือจาก SSMS มันต้องผ่านอะไรบ้างอย่าง Network ถัดมาเข้า DB Engine
>> DB Engine มันประกอบด้วยอะไรบ้าง

- Query Execution Layer - มาตรวจก่อน ว่า Query Syntax ถูกไหม มันคิดยาก หรือป่าว ถ้าง่าย SELECT * FROM ไป Query ตรงๆเลย แต่ถ้ายากใน Layer นี้ไปวางแผน หากลยุทธ์ เพื่อให้มันทำงานอย่างมีประสิทธิภาพที่สุดครับ โดยในแบบนี้ตัว DB สร้างตัว Execution Plan ขึ้นมาครับ
- Storage Engine Layer - เอา Plan จาก Query Execution Layer มาใช้ใน Layer จัดพื้นที่ โดยตัว SQL มันมองเป็น Page เหมือนหนังสือ ว่าจะเอาข้อมูลตรงไหนมา
- SQLOS - MSSQL มี OS ของตัวเอง โดยทำงานเป็น User Mode OS (ถ้าสาย ComSci เรียนวิชา OS มันมี 2 Mode คือ Kernel Mode กับ User Mode
- ทำ Wait Statistic ทำนี้
- low - level ที่จัดการ Resource, ทำ Scheduling, จัดการ I/O, Locking, จัดการ Transation, Deadlock, Exception และอื่นๆ
- คุมงานที่ส่ง ป้อนให้ CPU ไปทำงาน
- ถ้าลง DB แล้ว พยายามอย่าให้ Server ทำงานอื่นเสริม รวมทั้ง Service ของ MS เช่น ลง Service อย่าง Reporting / Analysis
- ในตัว DMV ของกลุ่ม sys.dm_os_xxx เป็นตัวที่มา Track ดูการทำงานของ SQLOS
NOTE: ผมเพิ่งรู้ว่าตัว MSSQL Server มัมี OS ชั้นนี้ ปกติสนใจพวก Query Execution Plan มากกว่า
>> NUMA System
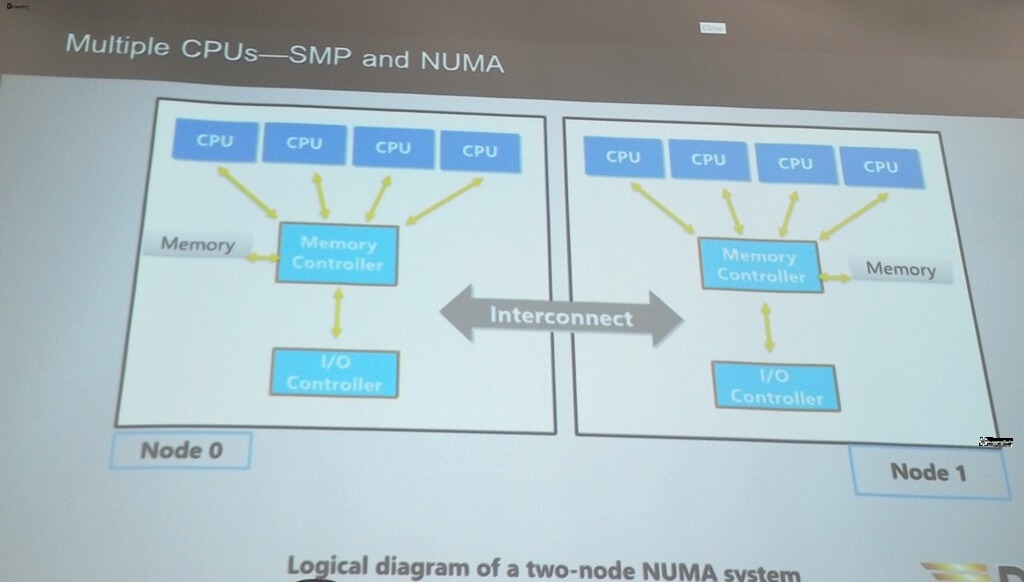
- NUMA node แบ่งกลุ่มให้ CPU เข้าไปให้ Memory แต่ละผืนที่จองไว้ จากเป็น CPU 8 Core
- 1 CPU ต่อ 1 Scheduler โดยเราสามารถปรับได้ที่ตัว Server Properties และกำหนด CPU ที่ใช้ตัว MSSQL มันใช้งานได้
- ตัว CPU เองมันทำงานจริงได้ 1 งาน ตัว SQLOS ส่งไปเข้าที่ละ Task ให้มันเผา
- ถ้ามีหลาย NUMA node พยายามเลือกใช้ CPU ใน Node เดียวกันให้ MSSQL เพราะ ถ้าทะลึ่งเลือกกันกระจายไปหลายๆ Node พอเวลามันใช้ข้อมูลจาก อีก Node มันต้องผ่านเส้น Interconnect ทำให้มันช้า
เวลามี Query เข้ามาจาก Client / App Server หรือ Web Server มันจอง 1 Session เอาไว้ โดยที่
- 1 Session มีหลาย Request
- 1 Request มี หลาย Task โดย Task เป็นตัวที่ CPU ต้องรีบเอางานไปเผาให้เร็วที่สุด
- โดยใช้ตัว sys.dm_exec_requests เรารู้ว่ามีงานทำงาน Background อยู่เท่าไหร่ ใช้ CPU อย่างไรบ้าง มี Status อะไรบ้าง เวลาดูให้ดูเบอร์ที่มากกว่า 50 น้อยกว่านั้นเป็นของ System
- Preemptive vs Non-Preemptive
- Preemptive - จัดความสำคัญ Windows พอใช้ CPU หนักๆ เช่น เล่มเกม / Process EOD ตัว OS จัดงานนี้มีความสำคัญเยอะสุด
- Non Preemptive - ทุกงานมีความสำคัญเท่ากัน ไม่ว่าจะงานใหญ่ หรืองานเล็ก ไม่สนว่าแต่ละ Task ทำทันไหม ตัวอย่างการทำงาน MSSQL
Note: ถ้า MSSQL ต่ำกว่า 2000 ใช้แบบ Preemptive แต่ Version หลังๆ ใช้แบบ Non Preemptive
- MSSQL-Non Preemptive Scheduler
ในแต่ละ Task มีเวลาทำงานเท่าๆกัน คือ 1 Quantum (4 ms) ถ้า CPU ทำทันจบ แต่ถ้าทำไม่ทัน มันวนเก็บไว้ใใน List เข้า Queue ไว้ โดยตัว List ที่สำคัญของ MSSQL
- Worker List - งานส่งไปเผาไปให้ CPU เผา
- Runable List - งานที่รอเผา โดยส่งไปเป็น Worker ทำงานเป็น FIFO
- Waiter List - งานที่เผาไปแล้ว แต่ไม่เสร็จ เกินเวลา 1 Quantum (4 ms) จะถูกวนมาเก็บใน List นี้ โดยตัว MSSQL เก็บข้อมูลตรงนี้ เอาไปทำ Wait Statistic
- I/O List
- Time List
- กลับมาที่ Wait Statistic
- พอเข้าใจแนวคิดแล้ว ว่าตัว MSSQL มันแตกงานย่อยที่สุดเป็น Task โดยแต่ละ Task ต้องส่งไปเผา(Worker List) ถ้างานมันใหญ่เผาไม่หมด ถูกย้าย (Waiter List) พักไว้ ซึ่งถ้าแต่ละงานมันสัมพันธ์กัน แสดงว่างานที่ถูก Waiter ไปมันถูก Suspend รอให้ต้องรองานนั้นทำให้เสร็จก่อน จริงๆ เราเอาตรงนี้มาดูพวก Blocking ได้นะ
- Wait & Queue
- Wait ถ้าเป็นที่ Resource รองาน รอ I/O - ระบบแสดง Suspend
- Wait ถ้าเป็นที่ Signal จาก CPU- ระบบแสดง Runable
- Queue - งานใน Worker List ที่ทำไม่เสร็จ
- DMV ที่เกี่ยวข้อง
- sys.dm_os_wait_stats -
- sys.dm_os_waiting_tasks -
- sys.dm_exec_session_wait_stats - เพิ่งมาใน SQL Server 2016 ++ โดยดูที่ละ Session ได้เลย
- Wait Statistic - Wait Type ที่เราพบเอกกันบ่อยๆ
- LCK_M_* - Lock ที่ resource เจอเยอะๆไม่ดี
- PAGELATCH_* - บอกว่ามีปัญหาระหว่าง Memory กับ Disk มี page ที่ถูกแย่งกันใช้งานเยอะ วิธีแก้ปัญหา เพิ่ม DataFile(.mdf) หรือทำ Partition
- PAGEIOLATCH - บอกว่ามีปัญหาระหว่าง Disk กับ Memory วิธีแก้ปัญหา มีเงินปรับ I/O หรือไม่ทำ Index ให้ DB มัน Update ค่า Stat ใหม่ หรือง่ายที่สุด ปรับที่ Query เราเองที่ทำ Table Scan หนักๆ
- CXPACKET - ดี เพราะ ตัว MSSQL Server ใช้ Parallel Plan (ต้องดูจาก Execution Plan) มีการใช้ Scheduler มากว่า 1 ตัว ช่วยกันทำงานมากกว่า 1 CPU โดยปกติใช้ CPU ตัวเดียว ทำให้ Query มีการทำงานอย่างมีประสิทธิภาพ ถ้าจะปรับต้องไปดู MAXDOP
- WRITELOG - ถ้ามันมีเยอะไป แสดงว่า I/O ของ Log มีปัญหา
- Useful Resource

Learning Resource
- SQL Global Meetup - http://www.pass.org/default.aspx
- SQLSkills - https://www.sqlskills.com/sql-server-resources/
- สำหรับ Script ในการจัดการตรวจสอบสามารถดูได้จากของคุณ Glenn Berry
- Virtual Labs - https://www.sqlskills.com/sql-server-resources/
- Facebook Group: SQL Server Community Thailand
Power BI Desktop โดยคุณ Chalaivate Pipatpannawong
ตัว Power BI เป็น Tools ที่เกิดมา เพื่อเล่นกับ Data โดยเฉพาะ และสามารถรองรับข้อมูลจำนวนมากได้ ถ้าใน Excel แบบเดิม มันจะถึงจุดนึงที่ Excel มันเดี้ยง และเอาข้อมูลนั้นมาแสดงผลให้น่าดึงดูด และมีลูกเล่น (Visualization) ซึ่งเจ้า Power BI App มี 3 แบบ
- Desktop - จัดการข้อมูล ทำ Model
- Service อยู่บน Cloud - เป็น Software As A Service เท่าที่ฟังมา ผมเข้าใจว่าตัวนี้เป็ฯแกนหลักนะ
- Mobile - เน้นการ View ดู เพื่อเอาข้อมูลสร้าง Value
- ขั้นตอนการทำ มี 5 Step
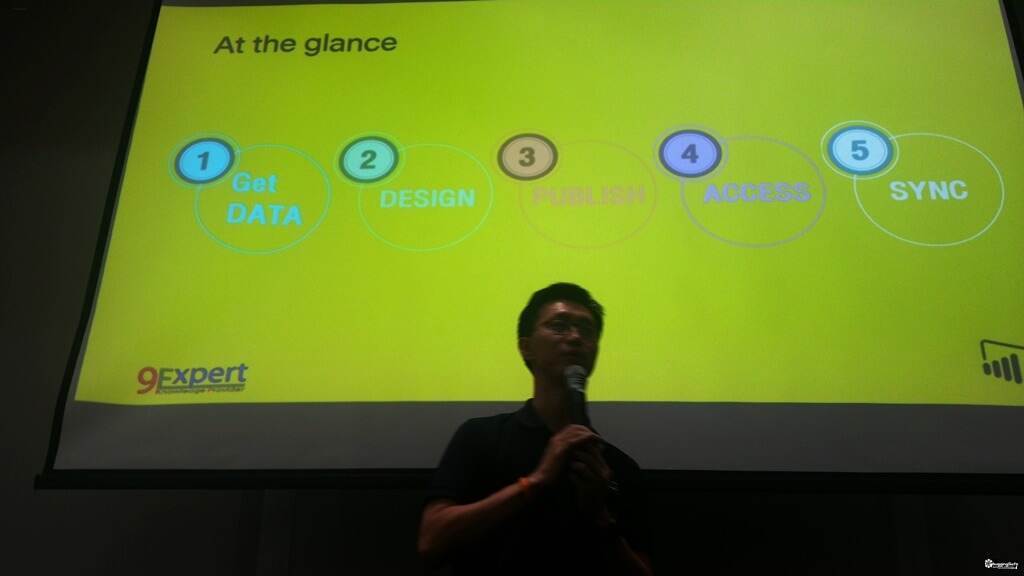
1. Get Data
เราสามารถเอาข้อมูลจากหลายแหล่ง Multi Source เอาอะไรมายัดก็ได้ครับ อาทิ เช่น
- Microsoft Family พวก SQL Server / Azure หรือ พวก MS Office Excel เป็นต้น
- Text File - CSV
- ของค่ายอื่นอย่าง Oracle (พวก DB เป็นต้น)
- หรือจาก Service อย่าง Google Analytic
- และอื่นๆ Step การทำงานหลัก มี 5 ส่วน
Note: การเอาข้อมูลเข้ามาใน Power BI มี 2 Mode
- Import - ดึงมาหมด ช้าในตอนแรก
- Direct Query - ดึงทีสนใจ
2. Design
- Clean Data - ทำพวก ETL จัดการข้อมูลเรียบร้อยให้พร้อมใช้งาน
- Data Model - สามารถนำข้อมูลมาเทรวมกัน และสร้างความสัมพันธ์กันได้
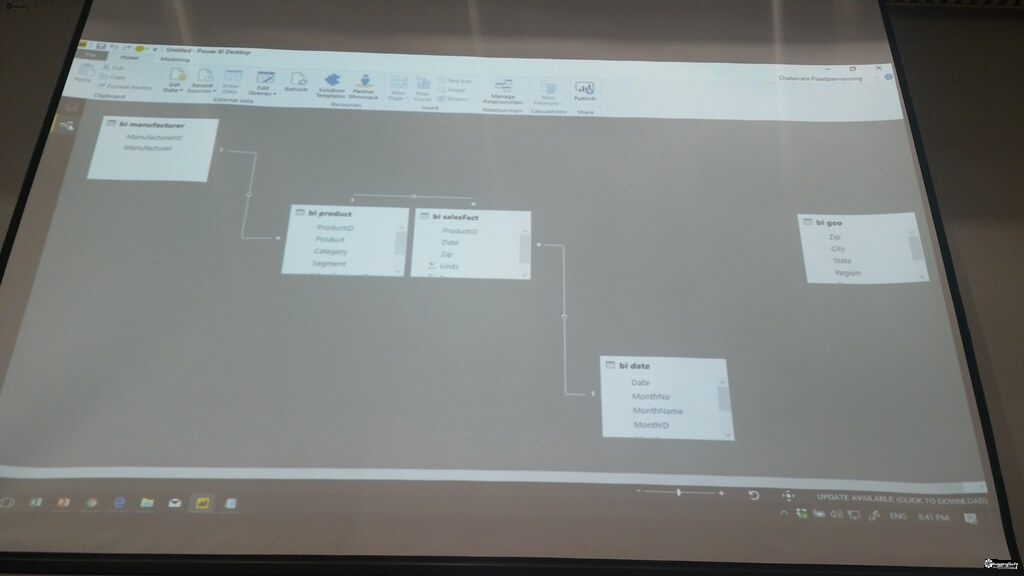
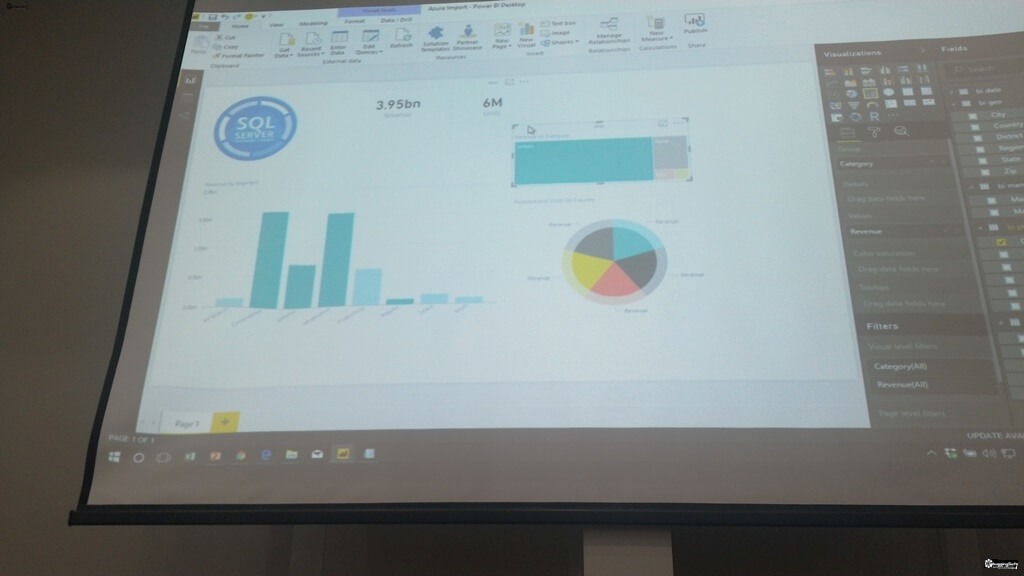
- Visualization - ทำให้มันดูง่ายขึ้น โดยสร้าง Report หรือ Dashboard ซึ่งของตัว Power BI มันเป็น Interactive ทำให้ข้อมูลมันมีลูกเล่น เปลี่ยนตามเงื่อนไขของผู้ใช้
- Design Once Access All Device
- พวกสูตรเหมือน Excel ใช้ DAX Syntax ช่วยได้
- แต่ถ้ามันซับซ้อนสามารถใช้ภาษาที่ฮิตๆ ในการทำ Data Science อย่างภาษา R เข้ามาจัดการได้
- เพิ่ม Q&A เวลา Public ขึ้นเว็บมีตัวช่วยให้ User สามารถค้น และการแสดงผลของข้อมูลตาม User ได้
3. Publish
Publish - เอาข้อมูลขึ้นเว็บ เพื่อให้คนอื่น เอา Model(Dashboard, Report) ที่ได้จาก Power BI ไปใช้งาน
4. Access
Access - ดูได้จาก App ทั้ง 3 หรือ Get Code ไป Embed บน เว็บได้ ตัวอย่าง 9experttraining
5. Sync
Sync - ถ้าข้อมูลมีข้อมูลมาใหม่ สามารถเติมเข้าไปได้ แล้วตัว Model ที่สร้างจาก Power BI รับรู้ และดึงมาแสดงผลได้
Power BI - Save ได้ไฟล์ .pbix
Q&A
Q&A #01 - สามารถกำหนดสิทธิของกับข้อมูลได้ไหม ?
- Ans ได้ กำหนดสิทธิการเห็นข้อมูลได้ แต่ผู้บริหารเห็นทั้งหมด และหัวหน้าส่วนภาคต่างๆ ดูได้เฉพาะของพื้นที่ตัวเองเป็นต้น
Q&A #02 - สาย DEV ของ Office มีตัว VSTO ให้มาทำส่วนเสริม (AddIns) ของ Office ได้ ใน Power BI มีอะไรคล้ายกันไหม ?
- Ans มีตัว Power BI เปิดใช้ ทำตัว Custom Visuals
สุดท้ายของกินภายในงานครับ มีโดนัทด้วย แต่ลืมถ่ายไว้


Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


