Data = ข้อมูลดิบ ทำอะไรได้บ้าง ?
ภาพนี้คงตอบได้หมดครับ ถ้าเรามีการจัดการกับข้อมูลที่ดี เราสามารถใช้ประโยชน์จากมันได้เต็มที่ครับ ถ้า Data เป็นวัตถุดิบที่ป้อนเข้าโรงงาน Information, knowledge, Insight และ Wisdom เป็นผลิตภัณฑ์ (Product) ที่ได้จากกระบวนการในขั้นตอนต่างๆครับ

แล้วข้อมูลแต่ละแบบ บอกอะไรเราบ้าง ?
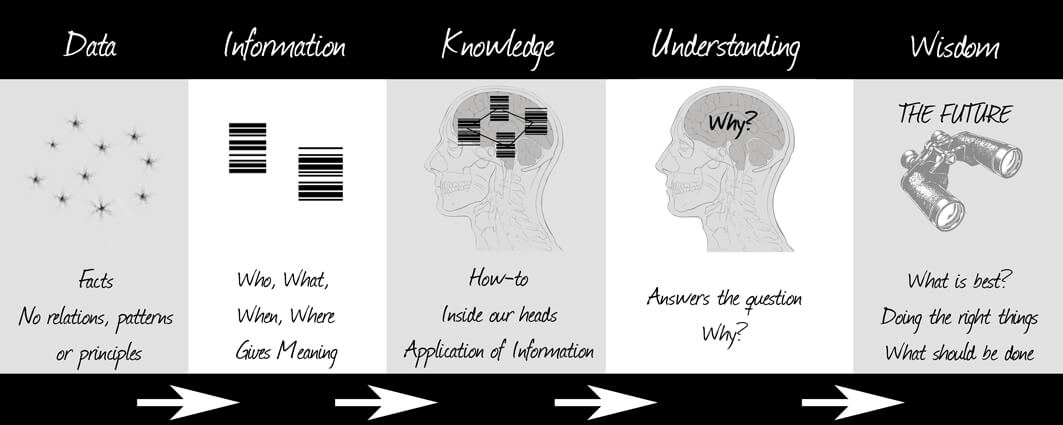
- เข้าใจความสัมพันธ์
- รู้รูปแบบ Pattern
- ทำนายได้
ลองมาดูอีกมุม
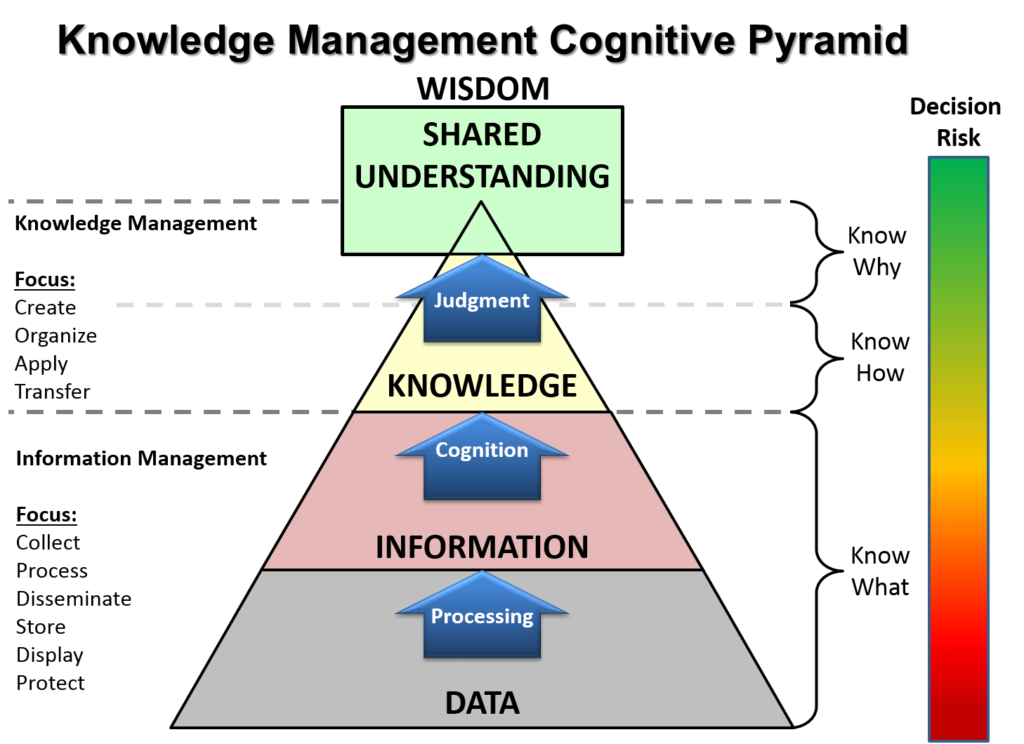
- Mind Map vs Mega Mind Map
- Mega Mind Map ข้อมูลมันเยอะขึ้นจน Mind Map มันเล็กเกินไป
- ในมุมของผมเอา Consept ของ Mind Map มาใช้ แต่มีการจัดกลุ่มของข้อมูล โดยมีการเรียงลำดับความสำคัญ จากราก ลำต้นไป กิ่งใหญ่ และกิ่งย่อยๆ จนแตกออกมาเป็นใบ เป็นผล ครับ
- Transaction Processing vs Event-Based Processing
- Transaction Processing - Batch ข้อมูลเข้าระบบ ทำ Decision Tree ออกมา
- Event-Based Processing - เมื่อข้อมูลมันเยอะมากขึ้น Macine Learning ก็เข้ามา
- อะไรที่ทำให้ Data Science ดัง
- Business Need - ทุกอย่างเริ่มต้นจากความต้องการของมนุษย์ ต้องการสร้าง Insight เพื่อเข้าใจลูกค้า
- Technology
- Cloud - รองรับการประมวลผลที่เยอะมากๆได้
- Internet of Things (IoT) - Smart Device รอบตัวเรา ถ้าในฝั่ง IT ที่เยอะๆ และคุ้นตากันคงเป็นพวก Log File
- Big Data - ผมมองว่าไม่ใช้ศัพท์ใหม่ แต่เป็นคำรวมๆที่รวมอะไร ที่ใหญ่ และเยอะไว้
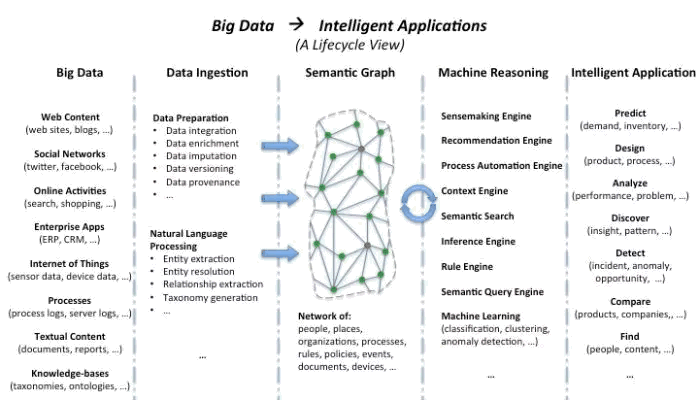
งานด้าน Data Science - ใช้แผนภาพนี้น่าจะบอกได้ง่ายกว่า สำหรับในมุมของผม Data Science คือ งานในด้านการวิเคราะห์แบบหนึ่ง อย่าง System Analyst - เอาความต้องการของลูกค้ามาสร้างให้เป็นระบบงาน(Product) ขึ้นมาชิ้นนึง ส่วน Data Science เป็นงานที่สนใจนมุมของ Data เป็นพิเศษครับ
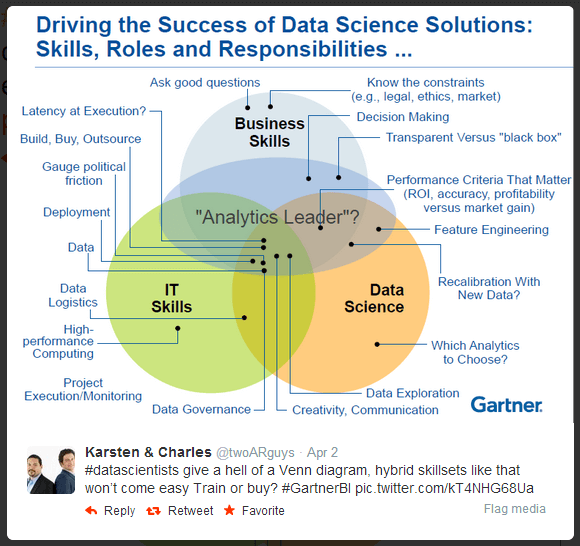
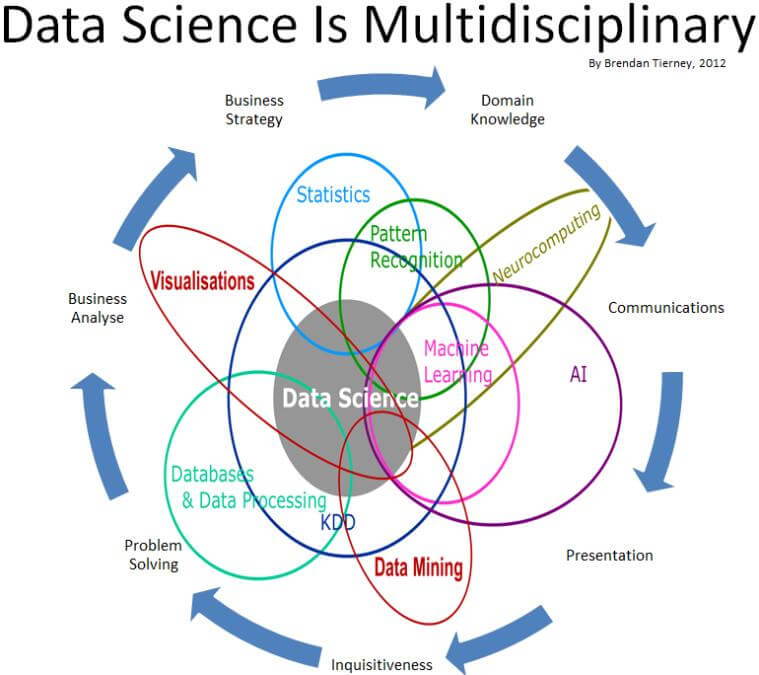
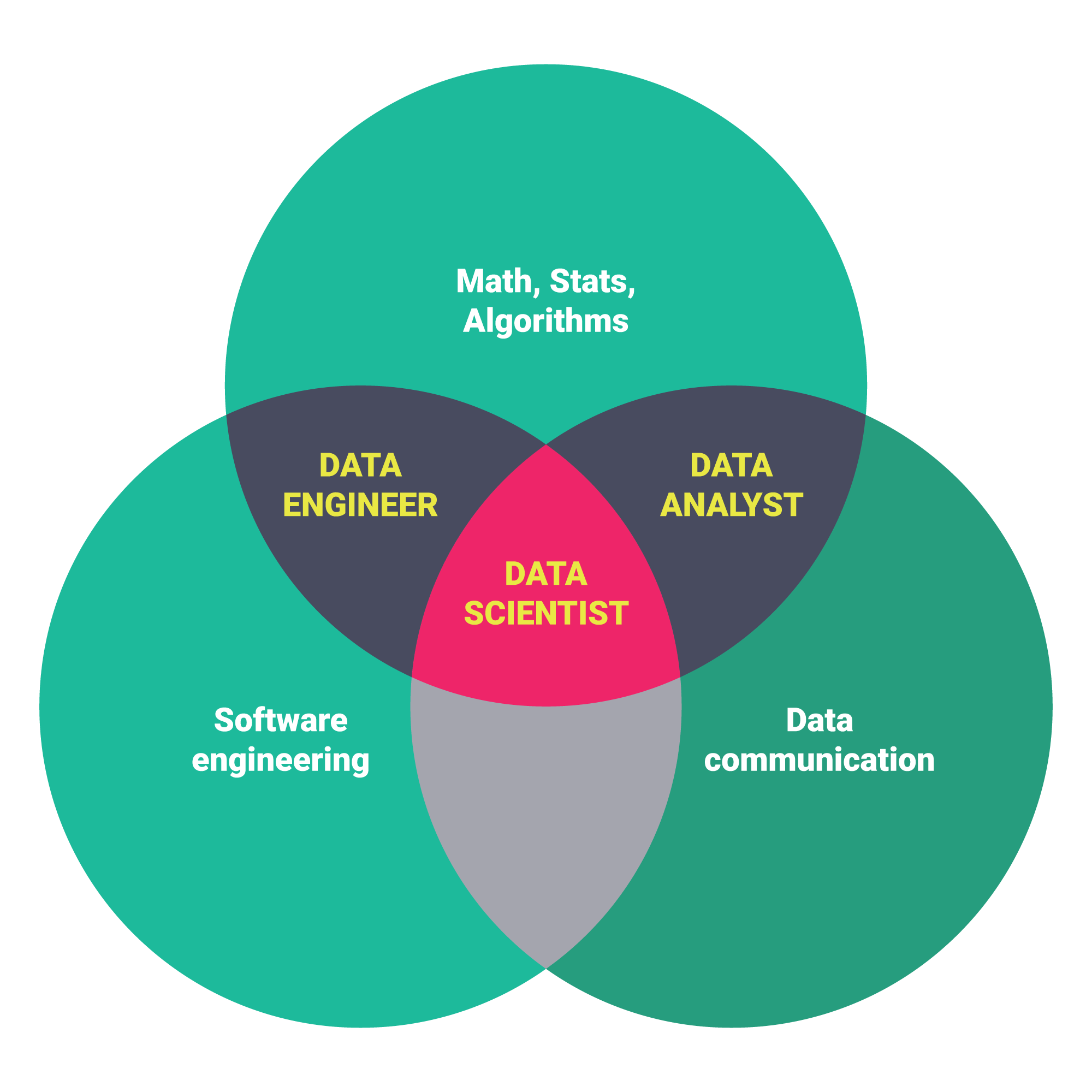
ส่วนทำไม Blog ตอนนี้ชื่อ Data Science 0.121 โดย 0 = เริ่มต้น และ 121 เป็นวิชาสายคอมวิชาแรกที่ผมเรียนตอนปริญญาตรีครับ (CP121 - Computer Science Principle) แถมชอบ Repo นี้จัง ดูแล้วมัน Awesome https://github.com/okulbilisim/awesome-datascience
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.


