
หลายคนอาจจะสงสัยว่า SQL มันก็นำมาคูณได้อยู่แล้วนี่ เอา Column A x Column B ก็จบ แต่ถ้าผมเปลี่ยนโจทย์หละลองทำการคูณในเหมือน Function SUM ใน SQL นะครับ
ทวนความรู้กันก่อน Function SUM ของ SQL คือ การหาผลรวมของข้อมูลใน Column เดียวกัน
ถ้าเราทำ Function MUL หรือ MULTIPLY ใน SQL คือ การหาผลคูณของข้อมูลใน Column เดียวกัน เมื่อเข้าใจ Concept แล้วไปลองทำ ผมค้นพบความโหดร้าย เพราะ ใน DBMS ไม่มี Function MUL สำหรับการคูณ (แทบทุกตัวนะ ผมไม่แน่ใจในส่วนของ Database ของ Big Data ว่าสามารถทำได้ หรือไม่ครับ)
กลับมาถึงพื้นฐานของคณิตศาสตร์ เราจะพบว่า MULTIPLY = EXP ของผลรวมของค่า LOG ในแต่ละ Field ใน Column นั้นๆนั่นเองครับ มองง่ายเลย MULTIPLY(คอลัมน์ที่ต้องการ) = EXP(SUM(LOG(คอลัมน์ที่ต้องการ))) หรือใช้งาน POWER แทน EXP ก็ได้ครับ
ลองมาใช้งานจริงบ้าง
- ก่อนอื่น ผมได้เสกข้อมูลออกมา ดังนี้
CREATE TABLE TESTMUTIPLICATIONAGGREGATE ( ID INT IDENTITY PRIMARY KEY, SECURITY_ID INT, VALUE INT ); INSERT INTO TESTMUTIPLICATIONAGGREGATE(SECURITY_ID, VALUE) VALUES (1, 2), (1, 4), (2, 6), (2, 8), (3, 10), (3, -12);
เมื่อลอง SELECT * FROM TESTMUTIPLICATIONAGGREGATE ได้ผลลัพธ์ ดังนี

ลองเขียน Query เพื่อหาผลลัพธ์ โดยใช้ Concept EXP(SUM(LOG(คอลัมน์ที่ต้องการ))) ได้ Query ดังนี้
SELECT EXP(SUM(LOG(VALUE))) AS MUL FROM TESTMUTIPLICATIONAGGREGATE WHERE SECURITY_ID IN (1,2) --เอาเฉพาะค่าบวกก่อน
ผลลัพธ์ที่ได้ครับ

ปัญหาที่เกิดขึ้น
- ปัญหาการ Overflow ของข้อมูล หรือข้อมูลมันใหญ่เกินไป
- สามารถจัดการได้ โดยอาศัยความสัมพันธ์ระหว่าง LOG กับ POWER เข้ามาช่วยได้ เพื่อให้ได้ตัวเลขที่เล็กลงจาก Query แล้วนำไปหาค่าจริงจาก Program ของเราอีกที
จาก step ที่ได้ เราได้ค่ามา 384 (สมมติว่ามันใหญ่มาก) ผมเลยจัดการใส่ LOG10 เพิ่มเข้าไปนี้
SELECT LOG10(EXP(SUM(LOG(VALUE)))) AS MUL FROM TESTMUTIPLICATIONAGGREGATE WHERE SECURITY_ID IN (1,2)
ผลลัพธ์ที่ได้ครับ
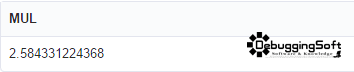
เมื่อเอาไปไปยกกำลัง =POWER(10, 2.584331224368) ได้ 384 ครับ นี่แหละความมหัศจรรย์ของคณิตศาสตร์
- ปัญหา ค่าที่เป็น ลบ
- ต้องระวังไว้นิดนึงเลย เพราะ log(0) กับ log(-ve) ตัว DBMS มันจะไม่สามารถคิดได้ ถ้าไม่ติดอะไรเรื่องเครื่องหมาย ผมแนะนำให้ทำ absolute ก่อนครับ
SELECT EXP(SUM(LOG(ABS(VALUE)))) AS MUL FROM TESTMUTIPLICATIONAGGREGATE WHERE SECURITY_ID IN (1,2,3)
ผลลัพธ์ที่ได้ครับ
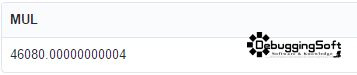
แต่ถ้าสนใจเครื่องหมายติดลบด้วยแล้ว ลองใช้ Query นี้ได้เลยครับ (Base on SQL Server นะครับ)
SELECT CASE WHEN MIN(ABS(VALUE)) = 0 THEN 0
ELSE EXP(SUM(LOG(ABS(NULLIF(VALUE,0)))))
* ROUND(0.5-COUNT(NULLIF(SIGN(SIGN(VALUE)+0.5),1))%2,0)
END AS MUL
FROM TESTMUTIPLICATIONAGGREGATE
จาก Query ด้านบนผมขออธิบายทีละส่วน ดังนี้
- MIN(ABS(VALUE) = 0 THEN 0 : เอาไว้ดักเลยว่า ถ้ามีข้อมูลเป็น 0 DBMS ไม่ต้องไปคิดอะไรเยอะแยะ Return 0 เลย
- EXP(SUM(LOG(ABS(NULLIF(VALUE,0))))): ส่วนเดิมที่เรารู้กัน
- ROUND(0.5-COUNT(NULLIF(SIGN(SIGN(VALUE)+0.5),1))%2,0): อันนี้ คือ ส่วนที่เอาไว้จัดการกับข้อมูลที่ติดลบ
- Function SIGN ตรวจสอบ
- ถ้าข้อมูล >0 Return 1
- ถ้าข้อมูล 0 Return 0
- ถ้าข้อมูล <0 Return -1 - ต่อมาได้ บวก 0.5 เพิ่มเข้าไป เพื่อกรองให้ผลลัพธ์เหลือเพียง -1 กับ 1 (รวม 0 กับ 1) เมื่อใช้ Function SIGN อีกครั้ง
- จากนั้นใช้ Function NULLIF รวมกับ ผลลัพธ์จากข้อที่แล้ว %2 เพื่อตัดจำนวนที่เป็นบวกออกไง
- COUNT เพื่อนับจำนวนเลขติดลบที่เหลืออยู่
- ถ้าได้ 1 แสดงว่ามีจำนวนเลขติดลบเป็นเลขคี่ เช่น มีเลขติดลบ 3 ตัว ได้แก่ -1, -2, -5
- ถ้าได้ 0 แสดงว่ามีจำนวนเลติดลบเป็นเลขคู่ เช่น มีเลขติดลบ 2 ตัว ได้แก่ -1, -2 - จากนั้นก็ใช้ Trick เล็กน้อย คือ -0.5
- แล้วไป Round อีกทีนึง เพื่อนำผลลัพธ์ที่ได้ คือ -1 หรือ 1 ได้ คูณกับผลลัพธ์ที่ได้จาก EXP(SUM(LOG(ABS(NULLIF(VALUE,0)))))
- Function SIGN ตรวจสอบ
สรุป ROUND(0.5-COUNT(NULLIF(SIGN(SIGN(VALUE)+0.5),1))%2,0) มีเพื่อเอาไว้หาว่า คูณ -1 หรือ 1 ดีตอนท้าย ตามหลักการง่ายๆ ทีเราเรียนตอนเด็กๆครับ
- ลบ * ลบ ได้ บวก
- บวก * ลบ ได้ ลบ
ผลลัพธ์ที่ได้ครับ
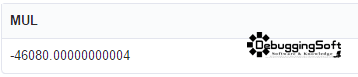
- ถ้าเอาไปลองใช้กับพวก GROUP BY ได้ไหม
- ได้ครับ โดยผมใช้ข้อมูลที่เสกมาตอนต้นมาลองนะครับ โดยผม Group ตาม SECURITY_ID โดยสนใจเฉพาะค่าบวก (เดี๋ยว QUERY ยาวเกิน)
SELECT SECURITY_ID AS SEC_ID, EXP(SUM(LOG(ABS(VALUE)))) AS MUL FROM TESTMUTIPLICATIONAGGREGATE WHERE SECURITY_ID IN (1,2) GROUP BY SECURITY_ID
- ผลลัพธ์ที่ได้ครับ
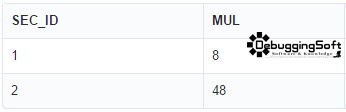
ทำไม DBMS ถึงไม่ใส่ Function นี้ Build-in มาให้เลย ?
- เพราะ มันไม่มีความต้องการของ Business ที่จะใช้มันมากมาย อย่าง Function SUM(), AVG(), MIN(), MAX() ไง มีแค่งานเฉพาะเจาะจง แต่ละด้านลงไป เช่น การเงิน, วิทยาศาสตร์ ซึ่งคนทั่วๆไปมักไม่ได้ใช้อยู่แล้ว
- เพราะ มันอาจจะหา Data Type ที่เก็บผลลัพธ์ได้ยาก มีสิทธิเกิด Overflow และกิน Performance ลองคิดดูเล่น ถ้ามีข้อมูลแบบนี้มาให้หาผลคูณ ประมาณ 1,000,000 รายการ ตัว DBMS ต้องจัดการ memory สำหรับทด และจัด Data Type ที่เป็นผลลัพธ์ อย่างไร เพื่อไม่ให้มันเกิด Overflow อย่างกรณี ยอดวิว Gangnam Style ทะลุค่าสูงสุดของตัวนับยอดวิวแล้ว เป็นต้น
- เพราะ กระบวนการทำงานต่างๆมันซับซ้อนกว่าที่เราเขียน Code วน Loop แล้วเอาไปคูณกัน โดยลองดูจาก Query นี้เป็นตัวอย่างครับ
SELECT LOG10(EXP(SUM(LOG(VALUE)))) AS MUL FROM TESTMUTIPLICATIONAGGREGATE WHERE SECURITY_ID IN (1,2)
- เราต้องไปคิดถึง 4 ชั้นตอนเลยนะครับ LOG >> SUM >> EXP >> LOG10 ซึ่งกันกิน Performance แล้ว มันมีโอกาสเกิดข้อมูลผิดพลาดได้จาก เจ้าเศษทศนิยมนี่แหละครับ เนื่่องจากคอมพิวเตอร์มันไม่ได้มองว่า 1 คือ 1 เหมือนคนเรานะครับ แต่มันมองเป็นเลขฐาน 2 โดยคอมาจจะเห็นเป็น 1.00000000000000000000000000000000000000006 แล้วพอผ่าน Aggregate Fucntion ต้องดูคู่มือก่อนว่ามี Return Type แบบไหนด้วยนะครับ (ตัวอย่างของ SQL Server มี Doc บอกไว้ "Using the POWER and EXP Exponential Functions" ดังนี้ครับ
สรุป
- ใช้แนวคิดนี้ เท่าที่จำเป็นนะครับ โดยผมได้สรุป Pattern เอาไว้ตามตาราง สามารถใช้ EXP หรือ POWERได้ ดังนี้
หาผู้อ่านท่านใดงง สามารถดูเพิ่มเติมได้ที่ TEST_MUTIPLICATION_AGGREGATE
| DBMS | Pattern(EXP) | Pattern(Power) |
| Oracle | EXP(SUM(LN(column))) | POWER(N,SUM(LOG(column, N))) |
| MSSQL | EXP(SUM(LOG(column))) | POWER(N,SUM(LOG(column)/LOG(N))) |
| DB2 | EXP(SUM(LN(column))) | POWER(N,SUM(LOG(column, N))) |
| MySQL | EXP(SUM(LOG(column))) | POW(N,SUM(LOG(N,column))) |
- ขอบคุณที่มานั่งอ่านการวิจัยฝุ่นของผมจนจบนะครับ 😀
Discover more from naiwaen@DebuggingSoft
Subscribe to get the latest posts sent to your email.

